
Introduction
What if you could write, ‘A cozy cabin in the woods, surrounded by snow, under a beautiful aurora,’

Or ,”A man reading a blog online from CloudxLab Website.”

Or ,”An ancient castle on a cliff, with waves crashing below and the moon glowing overhead “

and within seconds, seeing a perfect image of it come to life. That’s the magic of Stable Diffusion – a groundbreaking technology reshaping creativity as we know it .
What exactly is Stable Diffusion ?
Stable Diffusion, introduced in 2022, is a cutting-edge deep learning model that applies diffusion techniques to transform text into detailed, high-quality images. This innovative technology, developed by Stability AI, has quickly become a foundation in the generative AI domain, marking a significant milestone in the ongoing artificial intelligence boom.
The model’s primary capability is generating visually stunning images based on text descriptions, enabling users to bring their imagination to life. However, its applications extend beyond text-to-image generation. Stable Diffusion can also perform tasks such as:
- Inpainting: Restoring or modifying specific parts of an image based on user input while preserving the overall aesthetic.
- Outpainting: Expanding the boundaries of an image to create a larger, seamless composition that aligns with the original content.
- Image-to-Image Translation: Transforming one image into another while adhering to a textual guide, opening doors to creative storytelling and artistic exploration.
Stable Diffusion versions include 1.x (2022), 2.x (2022), SDXL 1.0/1.5 (2023), 3.0 (2024), and 3.5 (2024), each improving text-to-image quality, resolution, efficiency, and control. The latest, 3.5, offers customizable models and broader accessibility
| VERSION | QUALITY | RESOLUTION | EFFICIENCY | CONTROL | ACCESSIBILITY |
| 1.x (2022) | ■■ | ■■ | ■■ | ■ | ■ |
| 2.x (2022) | ■■■ | ■■■ | ■■■ | ■■ | ■ |
| SDXL 1.0/1.5 | ■■■■ | ■■■■ | ■■■■ | ■■■ | ■■ |
| 3.0 (2024) | ■■■■■ | ■■■■■ | ■■■■■ | ■■■■ | ■■■ |
| 3.5 (2024) | ■■■■■■ | ■■■■■■ | ■■■■■■ | ■■■■■ | ■■■■ |
The Evolution of Generative AI: From GANs to Stable Diffusion
1. The Foundation of Diffusion Models
The concept of diffusion models, which form the foundation of Stable Diffusion , was first introduced in 2015 by researchers such as Sohl-Dickstein et al . These generative models work by reversing a diffusion process, transforming random noise into coherent data. While diffusion models showcased significant potential for producing high-quality data, their adoption was initially delayed due to their computational complexity.
2. A Pivotal Moment: Denoising Diffusion Probabilistic Models (DDPM)
A pivotal moment in the development of diffusion models came in 2020 with research by Jonathan Ho , Ajay Jain, and Pieter Abbeel on “Denoising Diffusion Probabilistic Models (DDPM) .” This work enhanced image quality and diversity, addressing limitations of Generative Adversarial Networks (GANs) and establishing diffusion models as a powerful alternative.
Building on these advancements, diffusion models began to surpass GANs in both image quality and diversity, catalyzing their adoption in creative AI applications like Stable Diffusion
Generative Adversarial Networks (GANs): The Predecessor
Before diffusion models gained prominence, Generative Adversarial Networks (GANs) were the dominant generative models from 2014 to 2020 . GANs are a type of neural network architecture designed to generate new, realistic data samples similar to a given dataset. They consist of two components that work in tandem:
- Generator :
- This neural network creates new data samples. It starts with random noise and attempts to generate data (e.g., images, audio, text) that resemble the target dataset.
- Discriminator :This neural network evaluates the authenticity of the data. It distinguishes between real samples from the dataset and fake samples generated by the generator.
Despite their ability to generate realistic data, GANs faced challenges such as mode collapse (where the model produces limited variations) and issues with diversity .
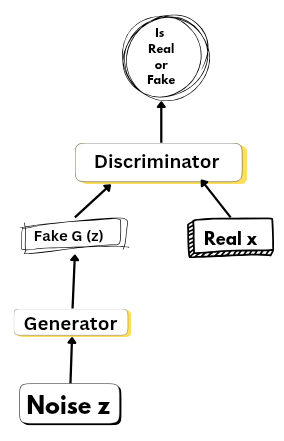
Learn more about GANs on our YouTube channel CloudxLab
The Emergence of Stable Diffusion
1. Introduction of Latent Diffusion Models (LDMs)
In 2022 , Stability AI introduced Stable Diffusion , leveraging Latent Diffusion Models (LDMs) to generate high-quality images efficiently. Unlike earlier models that operated in pixel space, Stable Diffusion works in a compressed latent space, drastically reducing computational requirements while maintaining exceptional output quality. This innovation made Stable Diffusion both powerful and accessible for use on consumer-grade hardware.

How Stable Diffusion Works
1. Iterative Denoising Process
In Stable Diffusion, creating an image starts with a noisy, almost unrecognizable version of the picture. This noise represents randomness and acts as the starting point. The system then refines the image step by step through a carefully designed process called iterative denoising .
At each step, a noise-reduction algorithm is applied, gradually removing the random noise while reconstructing the key features and details of the intended image. The process is guided by patterns and structures the model has learned during training, which come from a large dataset of images.
How It Works in Detail:
- Latent Space Representation : Unlike traditional models that operate directly on pixel data, Stable Diffusion works in a compressed latent space , which reduces computational requirements while maintaining high-quality output.
- Reverse Diffusion Process : The model reverses the diffusion process, where noise is progressively removed in small increments. Each iteration refines the image further, bringing it closer to the desired result.
- Text Conditioning : The text prompt you provide serves as a guide for the denoising process. The model uses this input to ensure the generated image aligns with the description, ensuring both creativity and accuracy.

2. Refinement Through Multiple Iterations
The refinement continues through multiple iterations, each step bringing the image closer to a clear, polished result. A key strength of Stable Diffusion is its ability to consistently produce clear and reliable images by carefully managing the noise-removal process, ensuring it doesn’t add too much noise or lose important details

Why Iterations Matter:
- Progressive Refinement : Each iteration enhances the image’s clarity and sharpness. Early iterations focus on broad shapes and structures, while later iterations refine finer details like textures, lighting, and shadows.
- Balancing Noise and Detail : One of the challenges in image generation is finding the right balance between removing noise and preserving important details. Stable Diffusion achieves this by using advanced algorithms that prioritize key features mentioned in the text prompt.
- Customization and Control : Users can adjust parameters such as the number of iterations or the level of noise reduction to fine-tune the output according to their preferences.
How Encoders,Decoders and Transformers Power Stable Diffusion
To truly understand the magic behind Stable Diffusion , it’s essential to explore key technologies that form its backbone: Encoder, Decoder and Transformers . These components are not only foundational to Stable Diffusion but also play a critical role in many modern AI systems, from natural language processing (NLP) to image generation.
1. What is an Encoder and Decoder?
An Encoder is a neural network component that processes input data and converts it into a more abstract, compact representation, often called a latent space or embedding . In the case of Stable Diffusion, the encoder compresses the input image into a latent space, which is a compressed version of the original image. This compression reduces computational requirements while retaining essential features, making the model both powerful and efficient.
- Processes input sequence
- Generates encoded representation
- Outputs context vector
The decoder is a crucial neural network component that transforms a compressed, abstract latent representation (produced during the denoising process) into a high-resolution, detailed image. It works by progressively upscaling and refining the latent vector, reconstructing the image step-by-step until it matches the desired output resolution. This allows the model to efficiently generate realistic images from lower-dimensional data.
- Generates output sequence
- Uses context vector from encoder
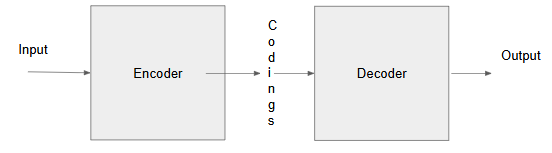
Why Encoders Matter in Stable Diffusion:
- Latent Space Representation : Instead of working directly with pixel data, Stable Diffusion operates in a compressed latent space . This approach drastically reduces the computational load, allowing the model to generate high-quality images even on consumer-grade hardware.
- Feature Extraction : The encoder extracts meaningful features from the input image or text prompt, ensuring that the generated output aligns with the user’s description. For example, if you input a text prompt like “a cozy cabin in the woods,” the encoder ensures that the model focuses on key elements like “cozy,” “cabin,” and “woods” during the image generation process.

2. What is a Transformer?
A Transformer is a type of neural network architecture introduced in 2017 that has revolutionized fields like NLP and generative AI. It uses a mechanism called self-attention to capture relationships between all elements in the input sequence, making it highly effective for tasks that require understanding context, such as text-to-image generation.
Key Components of Transformers:
- Self-Attention Mechanism :
- The core innovation of Transformers is the self-attention mechanism , which allows the model to weigh the importance of different parts of the input when generating output. In Stable Diffusion, this mechanism helps the model focus on specific keywords in the text prompt and ensure they are accurately reflected in the generated image.
- Example: If your prompt is “a futuristic city under a glowing aurora,” the self-attention mechanism ensures that the model emphasizes “futuristic,” “city,” and “glowing aurora” while generating the image.
- Weigh input features
- Calculate context vector
- Use context vector to weight input features
- Generate output based on weighted input
Context


- Multi-Head Attention :
- Transformers use multi-head attention , which allows the model to focus on different aspects of the input simultaneously. For instance, one attention head might focus on the “cityscape,” while another focuses on the “aurora,” ensuring that both elements are well-represented in the final image.
- Split input into multiple heads
- Calculate attention for each head
- Concatenate attention results
- Use concatenated attention to weight input features
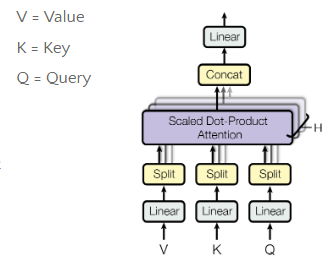
- Positional Encoding :
- Since Transformers do not inherently understand the order of elements in a sequence, positional encoding is added to provide information about the position of each word in the text prompt. This ensures that the model understands the relationship between words and generates coherent images.
Generates embeddings which allows the model to learn the relative positions of words.

3. How Do Encoders and Transformers Work Together in Stable Diffusion?
In Stable Diffusion, encoders and transformers work hand-in-hand to generate high-quality images from text prompts. Here’s how:
- Text Encoding with Transformers :
- When you input a text prompt like “an ancient castle on a cliff,” the Transformer-based encoder processes the text and generates a contextualized embedding. This embedding captures the meaning of the words and their relationships to each other.
- The Transformer’s self-attention mechanism ensures that the model understands the context of the prompt. For example, it knows that “castle” is related to “cliff” and “ancient,” which helps guide the image generation process.
- Image Encoding with Latent Diffusion Models (LDMs) :
- Once the text prompt is encoded, Stable Diffusion uses a latent diffusion model (LDM) to generate the image. The LDM operates in a compressed latent space, where the encoder has already processed the input image or noise.
- The iterative denoising process (explained earlier) refines the image step by step, guided by the text embedding generated by the Transformer. Each iteration brings the image closer to the desired result, ensuring that it aligns with the text prompt.

Visual Breakdown of the Image Refinement Process
Here’s a visual breakdown of the iterative stages involved in refining an image using Stable Diffusion:

Applications of Stable Diffusion
Stable Diffusion is a major step forward in generative AI, offering a powerful system for creating detailed, high-quality images from complex text prompts or datasets. By blending advanced noise-reduction techniques with modern deep learning methods, it supports many uses, such as:
- Art Creation : Generating realistic and artistic images from textual descriptions.
- Synthetic Data Generation : Producing high-quality synthetic data for training other AI models.
- Research and Development : Aiding in scientific research by generating visual representations of complex data.

How can one access Stable Diffusion?
A person can access Stable Diffusion in multiple way such as
1. Hugging Face: You can use the Stable Diffusion model directly through Hugging Face’s web interface. Simply visit their Stable Diffusion page, where you can input text prompts to generate images without any setup.
2. Run Locally: You can set up Stable Diffusion on your machine by cloning the GitHub repository here, downloading pretrained weights, and running the model locally. This method requires installing Python, some dependencies, and having a powerful GPU for optimal performance.
3. Third-Party Platforms: DreamStudio (by Stability AI) offers an intuitive interface for text-to-image generation. Visit DreamStudio to start creating but it comes with a limited token you can use stabledifffusion for unlimited image generation for absolutely free
4. Google Colab: Several developers provide pre-configured Google Colab notebooks where you can run Stable Diffusion in the cloud, allowing you to generate images without needing powerful hardware. Simply search for “Stable Diffusion Colab” for ready-to-use notebooks.
Stable Diffusion and Future Possibilities
As artificial intelligence continues to advance, Stable Diffusion is evolving beyond a mere technical tool and becoming a dynamic creative platform that can revolutionize various sectors, including visual arts, advertising, film production, education, research, and healthcare. The possibilities for its application are vast and ever-expanding.
Having already reshaped how art is created, Stable Diffusion’s influence is set to grow as it extends into additional fields, accelerating the ongoing digital transformation of society. For the general public, this means simplified creative processes and a broader range of expressive opportunities. For professionals, it provides more efficient, innovative tools to enhance their craft. The journey of this transformation is just beginning, and the future holds limitless potential for the breakthroughs Stable Diffusion may bring.
Want to master Data Science, Machine Learning, Generative AI, and more? Check out our expert-designed courses at CloudxLab.com and start your journey today!

Conclusion
Stable Diffusion represents a significant milestone in the evolution of artificial intelligence, transforming from a technical tool into a versatile and powerful creative platform. Its applications span a wide range of industries, from the arts to healthcare, and its potential to drive innovation is virtually limitless. As technology advances, Stable Diffusion will continue to enhance creative workflows, offering both the general public and professionals new, efficient ways to express ideas and solve problems. While its impact on digital transformation is already profound, the future holds even greater promise, with countless possibilities still to be discovered
