In Natural Language Processing (NLP), embeddings transform human language into numerical vectors. These are usually arrays of multiple dimensions & have schematic meaning based on their previous training text corpus The quality of these embeddings directly affects the performance of search engines, recommendation systems, chatbots, and more.
But here’s the problem:
Not all embeddings are created equal.
So how do we measure their quality?
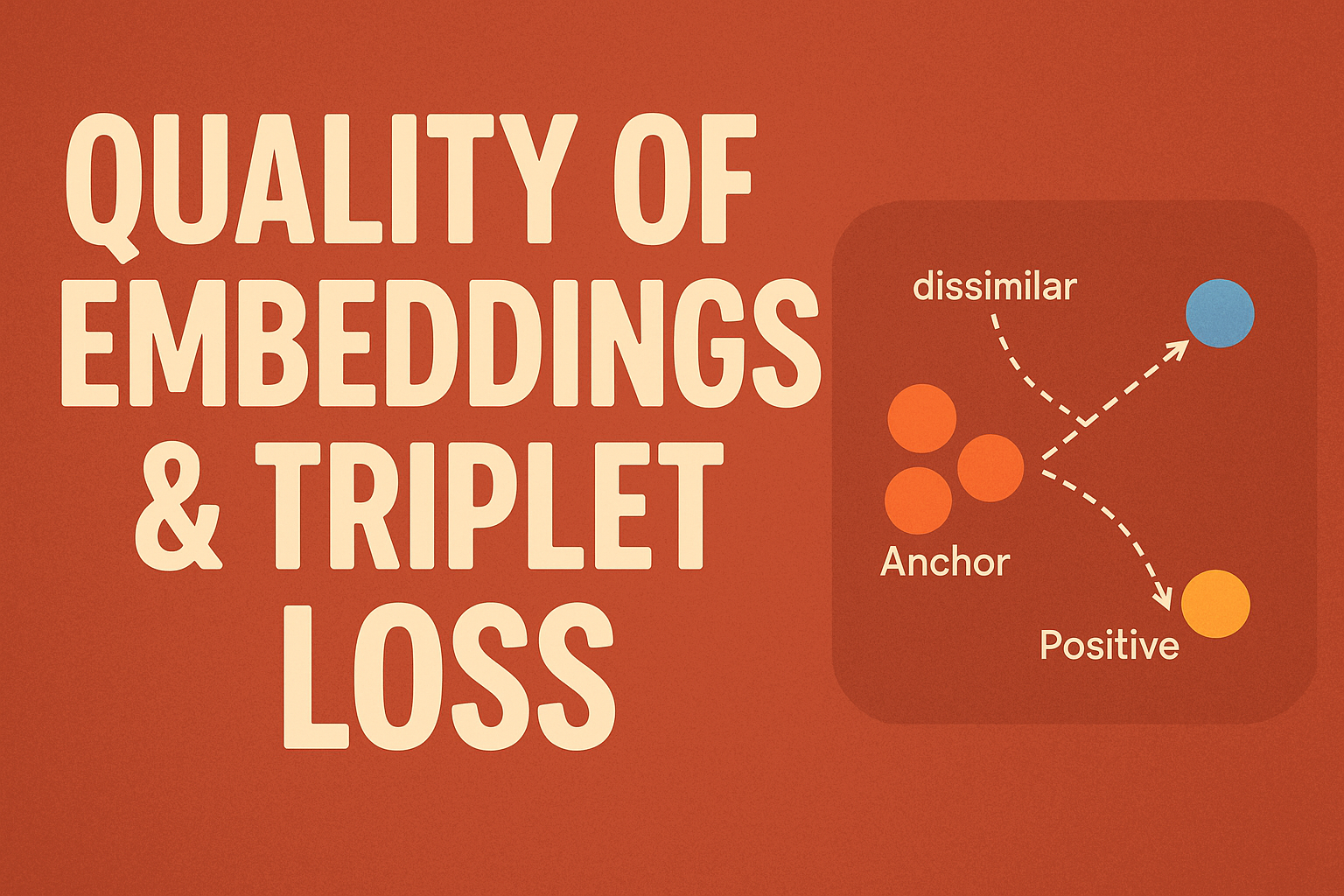
To Identify the quality of embeddings i conducted one experiment:
I took 3 leading (Free) Text → Embedding pretrained models which worked differently & provided a set of triplets and found the triplets loss to compare the contextual importance of each one.
Yes, it is Artificial Intelligence, Machine Learning, Data Science, and Data Engineering.
Therefore, now is the time to propel your Data Science career. Look no further because you can enroll for a PG Certificate Course in Data Science from IIT Roorkee. To make enrolment easy for you, here’s a Free Scholarship Test you can take and earn discounts up to Rs.75,000!
The Scholarship Test is a great opportunity for you to earn discounts. There are 50 questions that you have to attempt in one hour. Each question you answer correctly earns you a discount of Rs 1000, and you can earn a maximum discount of Rs 75,000! (50/50 rewards you with an additional 25000 scholarship)
This Scholarship Test for the Data Science course is a great way to challenge yourself in basic aptitude and basic programming questions and to earn a massive discount on the course fees.
The PG Certificate course from IIT Roorkee covers all that you need to know in technology right now. You will learn the architecture of ChatGPT, Stable Diffusion, Machine Learning, Artificial Intelligence, Data Science, Data Engineering and more! The course will be delivered by Professors from IIT Roorkee and industry experts and follows a blended mode of learning. Learners will also get 365 days of access to cloud labs for hands-on practice in a gamified learning environment.
Data Scientists, Data Engineers, Data Architects are some of the highly sought after professionals today. With businesses and life-changing innovations being data driven in every domain, the demand for expertise in Deep Learning, Machine Learning is on the rise. This PG Certificate Course gives you the skills and knowledge required for a propelling career in Data Science.
So what are you waiting for? Seats to the PG Certificate Course in Data Science from IIT Roorkee are limited. Take the Scholarship Test, earn discounts, and enroll now.
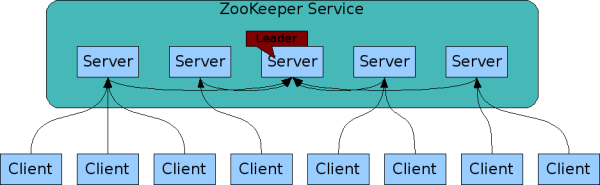
In the Hadoop ecosystem, Apache Zookeeper plays an important role in coordination amongst distributed resources. Apart from being an important component of Hadoop, it is also a very good concept to learn for a system design interview.
What is Apache Zookeeper?
Apache ZooKeeper is a coordination tool to let people build distributed systems easier. In very simple words, it is a central data store of key-value pairs, using which distributed systems can coordinate. Since it needs to be able to handle the load, Zookeeper itself runs on many machines.
Zookeeper provides a simple set of primitives and it is very easy to program.
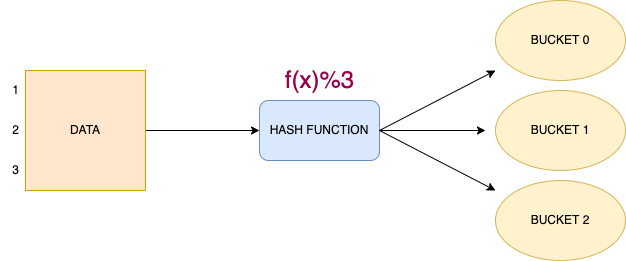
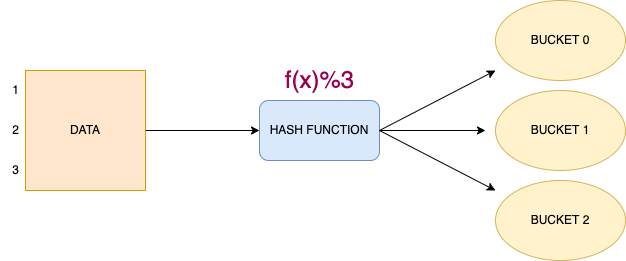
The bucketing in Hive is a data-organising technique. It is used to decompose data into more manageable parts, known as buckets, which in result, improves the performance of the queries. It is similar to partitioning, but with an added functionality of hashing technique.
Introduction
Bucketing, a.k.a clustering is a technique to decompose data into buckets. In bucketing, Hive splits the data into a fixed number of buckets, according to a hash function over some set of columns. Hive ensures that all rows that have the same hash will be stored in the same bucket. However, a single bucket may contain multiple such groups.
For example, bucketing the data in 3 buckets will look like-
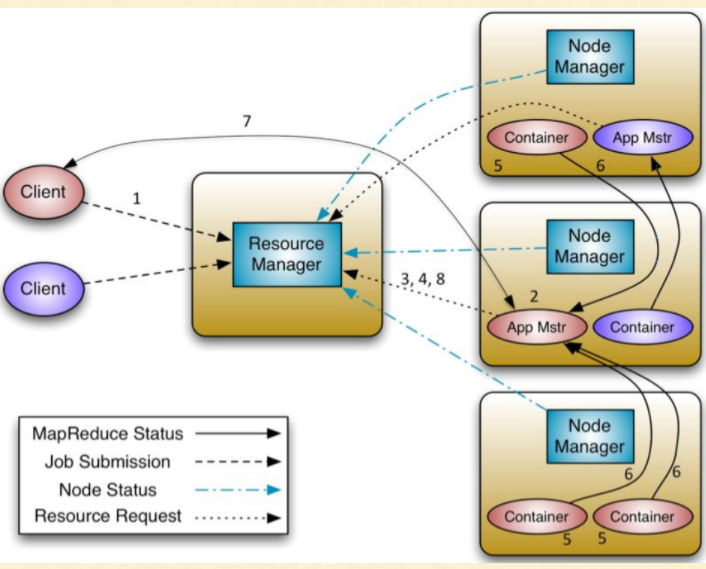
In the Hadoop ecosystem, YARN, short for Yet Another Resource negotiator, holds the responsibility of resource allocation and job scheduling/management. The Resource Manager(RM), one of the components of YARN, is primarily responsible for accomplishing these tasks of coordinating with the various nodes and interacting with the client.
To learn more about YARN, feel free to visit here.
Architecture of YARN
Hence, Resource Manager in YARN is a single point of failure – meaning, if the Resource Manager is down for some reason, the whole of the system gets disturbed due to interruption in the resource allocation or job management, and thus we cannot run any jobs on the cluster.
To avoid this issue, we need to enable the High Availability(HA) feature in YARN. When HA is enabled, we run another Resource Manager parallelly on another node, and this is known as Standby Resource Manager. The idea is that, when the Active Resource Manager is down, the Standby Resource Manager becomes active, and ensures smooth operations on the cluster. And the process continues.
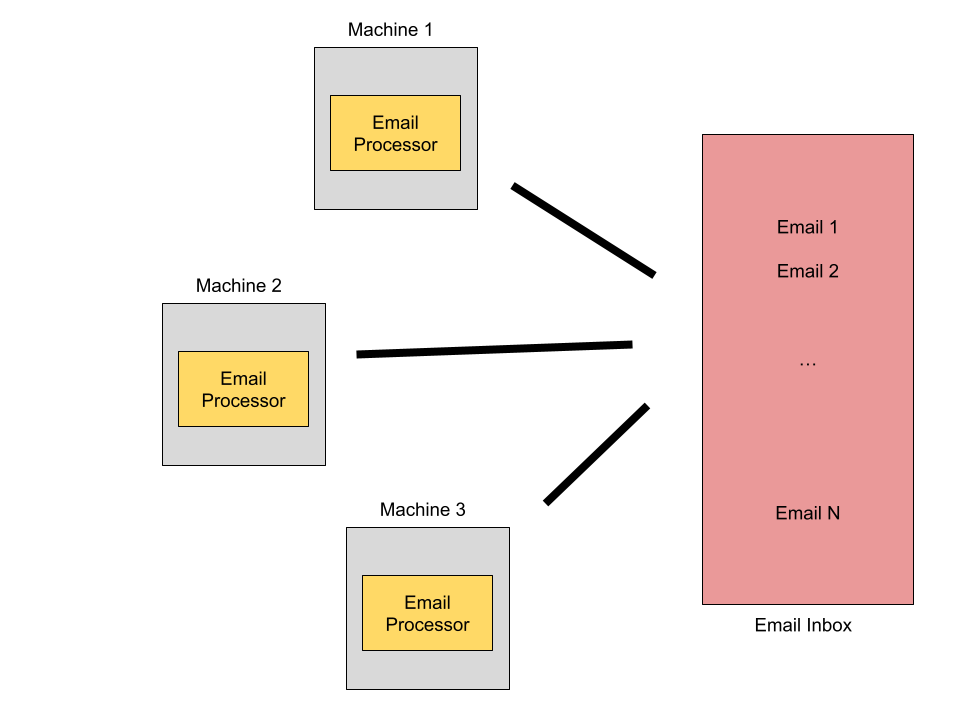
Consider a situation where we have an email inbox that consists of emails, and emails are to be processed. For example, processing those emails and classifying each of the emails as spam or non-spam. The other example of the processing could be we are indexing the email so that the search could be performed.
We have an email-processor program, running on various machines distributed physically from each other.
Email processor program running on distributed systems
Now these machines need to somehow coordinate such that:
Consider a situation where we have an email inbox that consists of emails. We have the task of processing those emails and classifying each of the emails as spam or non-spam. This email inbox is read-only.
We have an email-processor program, running on various machines distributed physically from each other.
Now these machines need to somehow coordinate such that:
No email is processed two times
No email is left unprocessed
Solution 1:
Usage of flags: we could mark the emails to be read or unread by any machine previously, and only consider those emails which are not yet read.
CONS:
While processor 1 reads an email and mark it as read, and then the processor dies, then the email would not touched by any other processor in future, because it was already marked as read by the first processor, and thus this email would be left unprocessed.
SOLUTION 2:
There should be a manager that could handle the workload and distribute the work to workers.
Cons:
This manager could be a bottleneck as it has to maintain a large number of systems, and thus it would be overloaded. Also, what is the manager dies?
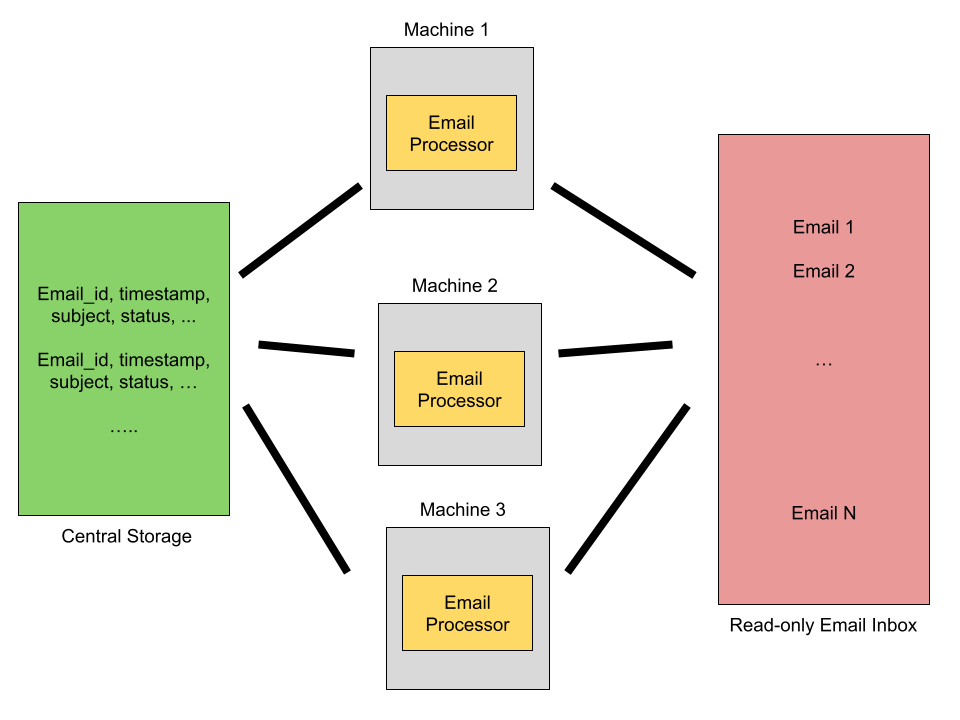
SOLUTION 3:
We need a central storage which could note down who is doing what, like email id, timestamp it was taken up by a processor, status of completion of processing, etc.
Distributed systems with central storage service for coordination
CONS:
The central storage system can be a bottleneck. Say the email processor programs are running on a lot of machines, then the central storage system would be on high demand and thus it will be overloaded, and it may also die.
Solution 4:
Distributed storage system like Zookeeper could be an ideal solution for the problem.
Zookeeper :
provides simple primitives like set/get, so easy to program
has an easy data model, like a directory tree
is a resilient and highly available tool
How it could solve the problem?
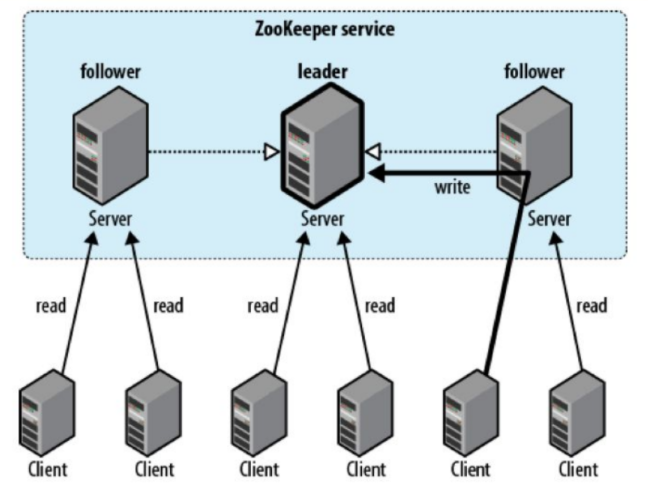
Suppose the process on Machine 1 wants to read some data from the email inbox. Say it has successfully picked 100 emails to process and it noted down this information with Zookeeper. This could be done by creating a sequential ephemeral znode, along with the info about the email_id, timestamp, status, etc. Since this process is creating a znode, it is obviously a write operation. When a process is carrying out a write operation on Zookeeper, then it acquires a lock(with its session id to identify who performing this write). In the meanwhile, another process (maybe from another machine) may want to read emails and make a note of it in zookeeper. This means another process wants to create a znode about the emails it wants to pick. This would not be possible, as the first process has still not released to lock for the second process to conduct a write operation in zookeeper. Also, once the lock acquired by the first process is released, the second process would check if the emails it has picked up are already processed by some other process, to ensure no email is processed more than once. Also, the second process also could check the timestamps when the emails were taken up by other processes and what is status(if the email is processed successfully after being picked by some other process). If the timestamp was made long ago and still the status is unsuccessful, the next process could pick that email, so as to make sure that no email is left unprocessed. In this way, the zookeeper makesure that no email is processed more than once, and n email is left behind unprocessed.
As long as the first process has acquired to like to perform some write operation, all the other processes – those who wish to acquire the lock and perform some write operation – will have to wait, by creating sequential ephemeral znodes. The sequential znodes would have suffixes with the incremental numbers for each of the newly created znodes. Once the current process releases its lock, that znode could be removed, and then the process whose znode is having the minimum number could acquire the lock. Thus, by creating sequential znodes, the order of operations could be preserved. Further, ephemeral znodes help in tracking the clients if they are active or dead. If a client is active, it sends regular signals(called heartbeats) to Zookeeper to mark its presence. If it could not send the heartbeats due to network some temporary network failure or likewise, the session is still alive, but if the heartbeat is ceased for a duration longer than the session timeout, Zookeeper understands that the client is dead. This means the session times out and the ephemeral znode disappears. Thus, the reason for creating sequential ephemeral znodes is that, sequentiality preserves the order in which the operations should be performed, and ephemerality ensures that all the clients are alive(a watcher could be placed to track if any of the processes get disconnected. Then, a notification could be sent to appropriate resources so that a new process could be up and continue the work which was previously handled by the dead process, thus making the whole system fault-tolerant and highly available).
If a zookeeper server dies, then a new server could come up, or the client could connect to some other server in the ensemble. Thus zookeeper is distributed service so that even if a zookeeper server fails, it could still manage resiliently to maintain coordination amongst the distributed systems.
Conclusions
Zookeeper is a distributed coordination service that provides the following mechanisms to promote coordination amongst distributes systems:
distributed key-value store to store small JSON data
Various types of znodes suitable for different use cases
monotonically increasing unique ids to the znodes
Zookeeper ensemble
watches
notifications
The above mechanisms thus make Zookeeper:
resilient
highly available
fault tolerant
efficient intermediary for coordination amongst distributed systems
If you are still more eager to know about Zookeeper, feel free to visit here. To know more about CloudxLab courses, here you go!
In the Hadoop ecosystem, Apache Zookeeper plays an important role in coordination amongst distributed resources. Apart from being an important component of Hadoop, it is also a very good concept to learn for a system design interview.
If you would prefer the videos with hands-on, feel free to jump in here.
Having known of the prevalence of BigData in real-world scenarios, it’s time for us to understand how they work. This is a very important topic in understanding the principles behind system design and coordination among machines in big data. So let’s dive in.
Scenario:
Consider a scenario where there is a resource of data, and there is a worker machine that has to accomplish some task using that resource. For example, this worker is to process the data by accessing that resource. Remember that the data source is having huge data; that is, the data to be processed for the task is very huge.

![How to design a large-scale system to process emails using multiple machines [Zookeeper Use Case Study]?](https://cloudxlab.com/blog/wp-content/uploads/2021/05/Untitled-drawing-4.png)