Part of CloudxLab’s Future Ideas series, where we explore where technology is headed before it arrives. In this piece: why the next generation of enterprise software will look like a conversation, not a screen – and what that means for the engineers who will build it.
For nearly three decades, the enterprise has run on software that employees tolerate rather than use. ERP suites like SAP and Oracle, HR platforms like Workday, accounting systems, workflow and ticketing tools, CRM, and a sprawl of reporting dashboards became the circulatory system of the modern organization – each encoding its own slice of how the business runs, in its own schemas, its own approval chains, its own logins. Together they succeeded at their founding mission: an authoritative record of the enterprise. But that success came at a cost paid daily in fragmented screens, swivel-chair integration, and the quiet resignation of every employee who has ever filed an expense report in one system, checked its status in another, and reported on it in a third.
That era is ending. The convergence of generative AI, agentic workflows, and semantic data architectures is producing a new form of enterprise software – not a better dashboard, but a fundamentally different surface for work.
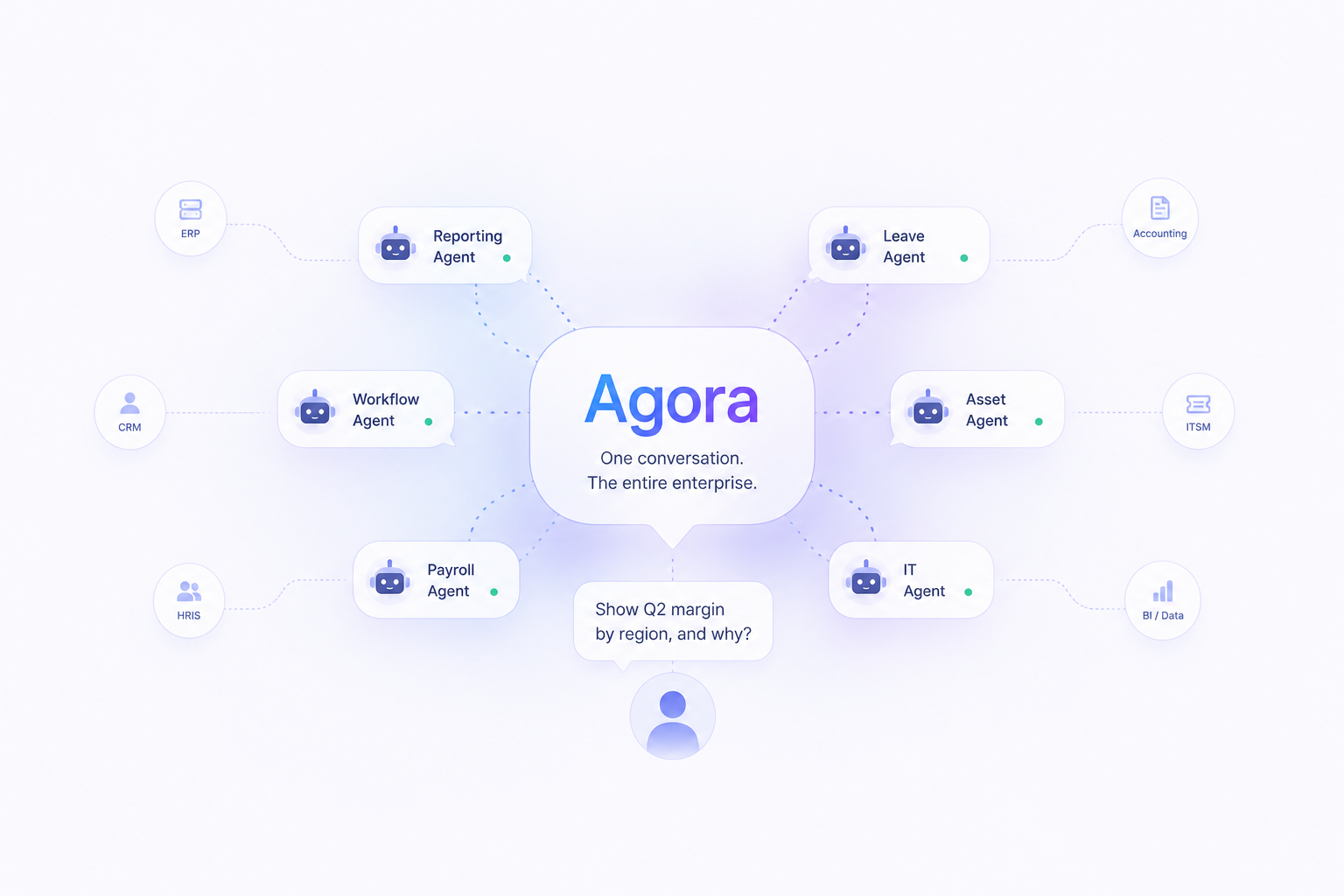
Call it Agora – after the ancient Greek gathering place where commerce, conversation, and decision-making happened in one shared space. Agora is not another application in the stack. It is a conversational, agent-populated operating layer that sits above the entire enterprise app estate – ERP, workflow systems, accounting, reporting, CRM, HRIS – where the enterprise talks to itself, and where human intent becomes governed, auditable action.
The Brittleness Tax
To understand why this shift is inevitable, name what legacy enterprise apps actually are: institutional memory fossilized into configuration.
These systems were architected for an era that prized stability over agility. Every business rule – who can approve a purchase order above $50,000, which cost center a new hire bills to, how a customer escalation routes through support – lives somewhere in a thicket of tables, customization layers, and workflow engines, often documented nowhere but in the head of a consultant who left years ago.
The result is what we might call the brittleness tax: each customization is an asset on day one and a liability at every upgrade thereafter. And the tax compounds across the portfolio – the ERP customization that breaks the accounting integration, the workflow tool that duplicates what the ticketing system already does, the reporting layer that disagrees with both. Organizations defer migrations for years, not because they don’t want the new features, but because nobody can predict what will break.
For twenty years, the human being has been the enterprise’s middleware. That arrangement is now being retired.
The human toll is just as measurable. Industry analyses have found that knowledge workers toggle between applications thousands of times per day, reconstructing context at every system boundary – from the CRM to the ERP to the BI dashboard and back. Employees don’t navigate these systems; they perform archaeology on them.
The deepest problem is architectural. Legacy enterprise apps are systems of record: each excels at storing its slice of what happened. They are poor systems of action: any process that crosses application boundaries – and nearly every real business process does – requires a human to serve as the integration layer, reading from one screen, thinking, and typing into another.
The Agentic Shift: Work as Conversation
Agora inverts the relationship between people and enterprise software. Instead of humans learning to navigate a dozen systems, one system learns to converse with humans. The interface is not a menu tree; it is a messaging surface – deliberately Slack-like – populated by both colleagues and specialized agents.
In this model, the org chart quietly acquires new members:
- An asset-tracking agent answers “where are the fourteen laptops we shipped to Austin?” in seconds – no transaction codes required.
- A leave-management agent handles “I need the last week of August off” – checking balances, routing approval, updating the calendar, notifying the team – as one conversational exchange.
- A payroll agent fields the questions that today generate thousands of HR tickets.
- A reporting agent turns “how did Q2 margin move by region, and why?” into an analysis drawn live from the accounting and sales systems – no dashboard hunting, no stale extract.
- A workflow agent shepherds a contract, a purchase requisition, or an incident through every approval stage, nudging the right people instead of waiting in a queue nobody checks.
The employee’s mental model shrinks from “which system, which screen, which field” to a single verb: ask. Three capabilities make this more than a chatbot veneer.
1. Conversational interfaces as the universal front door
Plain language replaces transaction codes, screen paths, and the tribal knowledge of which of five systems owns the answer. This is not merely convenient – it is democratizing. The power-user advantage dissolves when every employee can express intent directly. Training costs collapse. Adoption stops being a change-management project and becomes a habit.
2. The Creator layer: extensibility by description
Perhaps the most radical element of Agora is the Creator Bot – an agent whose job is to make other agents. A finance manager who needs a monthly P&L variance analysis doesn’t file a ticket with IT and wait a quarter. An operations lead who needs a vendor-onboarding workflow doesn’t buy another point solution. They describe the requirement in conversation; the Creator Bot assembles the workflow, wires it to the semantic data layer, and deploys it – governed, permissioned, and versioned.
System extensibility – historically the most expensive and brittle part of enterprise software ownership – becomes a self-service conversation. This is the moment enterprise software stops being configured and starts being composed. It is also the moment the long tail of niche workflow apps starts to collapse into the layer above them.
3. The system of action: a control plane above the record
Agora does not replace the systems beneath it – it orchestrates them. Sitting atop the application estate as a control plane, it chains multi-app workflows into single intents: “onboard this contractor” becomes one request that fans out across identity, procurement, payroll, and facilities systems – each step executed by an agent, each step logged. The human expresses the what; the layer handles the how and the where.
Agora Across the Enterprise: A Use-Case Tour
Abstractions convince architects; use cases convince everyone else. Here is what Agora looks like across departments – each example is one plain-language request that would today take three systems, two tickets, and a spreadsheet.
The pattern is identical in every cell of that grid: a question or an instruction that today dies in a queue becomes a governed transaction with an answer attached. Here is the reporting case played out in full:
The Architecture Beneath the Conversation
The shift is not cosmetic; it is structural. A conversational skin on a broken data model produces only a faster way to be wrong. Agora’s architecture rests on four commitments.
Semantic data layers. Operational data must be lifted out of siloed applications and normalized into a machine-readable model of what the business means, not just what each system’s tables contain. When “customer,” “invoice,” and “obligation” carry one consistent definition across the ERP, the CRM, and the reporting stack, agents can reason over them safely. The semantic layer is to the agentic enterprise what the relational schema was to the ERP era: the substrate everything else assumes.
Headless operations. As software goes headless, value migrates from the UI to the API and data layer. Agents read and write directly to the operational layer; humans engage through conversation and receive rendered views only when a decision genuinely needs their eyes. The pixel-perfect screen – once the product each vendor competed on – becomes an artifact generated on demand.
Continuous close, continuous truth. AI-native accounting systems such as Rillet gesture at the destination: ledgers that are always reconciled, where the month-end scramble becomes obsolete because there is nothing left to close. The same principle generalizes across the estate – reporting that is never stale, workflows whose status is always current. Business truth stops being a periodic event and becomes a standing condition. The executive’s question changes from “what happened last month?” to “what is happening right now – and what should we do about it?”
Governance by design. Agents in Agora handle payroll, personnel records, customer data, and financial commitments – the most sensitive material an organization holds. Security, permissioning, and audit cannot be bolted on at the edges; they must be embedded at the agent layer itself. Every agent operates within an explicit scope of authority. Every action carries a durable, inspectable trail: who asked, what the agent did, which data it touched, under what policy.
In a well-built Agora, the audit trail is not a burden appended to work – it is a byproduct of how work happens.
The Path Forward: Wrapping, Not Ripping
The endgame is not the wholesale replacement of legacy systems. The ERP, the accounting platform, the HRIS are too deeply embedded – in contracts, in compliance regimes, in the muscle memory of global operations – to be ripped out, and the attempt has bankrupted more transformation budgets than it has ever repaid.
The realistic – and superior – strategy is encapsulation: an AI layer that becomes the primary surface for work while the legacy estate keeps doing what it does well, durably storing the record. Decades of investment in enterprise data are not stranded; they are unlocked. And the organization gains optionality: as AI-native alternatives mature, individual systems can be swapped out beneath the Agora layer – the accounting engine this year, the workflow tool the next – without disturbing the surface where work actually happens. The conversation persists; the plumbing evolves.
The Enterprise That Answers
The trajectory of enterprise software can be told in three sentences. The first era digitized the record: we taught machines to remember. The second era networked the record: we taught machines to share. The third era – the one Agora names – operationalizes the record: we are teaching machines to act, within governance, on our behalf.
The future of enterprise apps is less a portfolio of static databases and more a single operating layer that turns human intent into auditable, governed action. Its interface will look like a conversation because work, at its core, has always been a conversation – interrupted, until now, by the software that was supposed to support it.
Agora simply removes the interruption. The employee of the coming decade will not “use the ERP,” “check the dashboard,” or “file a ticket.” She will state what she needs, in her own words, in the same place she talks to her colleagues – and the enterprise, at last, will answer.
What would your organization ask first, if your enterprise apps could simply answer? Share your take in the comments. And if you want to build the skills behind this future – LLMs, agentic AI, and the data engineering underneath them – explore CloudxLab’s hands-on courses and cloud lab.