
Introduction
There are many Big Data Solution stacks.
The first and most powerful stack is Apache Hadoop and Spark together. While Hadoop provides storage for structured and unstructured data, Spark provides the computational capability on top of Hadoop.
The second way could be to use Cassandra or MongoDB.
The third could be to use Google Compute Engine or Microsoft Azure. In such cases, you would have to upload your data to Google or Microsoft which may not be acceptable to your organization sometimes.
Note: If you are a good listener and prefer to watch a video rather than read through this post, please check out the corresponding video here.
Alright, so let’s jump in!
Goals
In this post, we will understand basics of:
- Apache Hadoop
- Components of the Hadoop ecosystem
- Overview of Apache Spark ecosystem
Prerequisites
It is highly recommended to go through our previous post on Introduction to Big Data and Distributed Systems, where we have discussed on the basics of Big Data and its applications in various fields.
What is Hadoop?
Hadoop was created by Doug Cutting in order to build his search engine called Nutch. He was joined by Mike Cafarella. Hadoop was based on the three papers published by Google: Google File System, Google MapReduce, and Google Big Table. It is named after the toy elephant of Doug Cutting’s son.
Hadoop is under Apache license which means you can use it anywhere without having to worry about licensing. It is quite powerful, popular, and well supported. It is a framework to handle Big Data. Hadoop is written in Java so that it can run on all kinds of devices.
Started as a single project, Hadoop is now an umbrella of projects. All of the projects under the Apache Hadoop umbrella should follow three characteristics:
1. Distributed – They should be able to utilize multiple machines in order to solve a problem.
2. Scalable – If needed it should be very easy to add more machines.
3. Reliable – If some of the machines fail, they should still work fine. These are the three criteria for all the projects or components under Apache Hadoop.
Components of the Hadoop ecosystem
The Apache Hadoop is a suite of components. Let us take a look at each of these components briefly. We will cover the details in the later series of the posts.
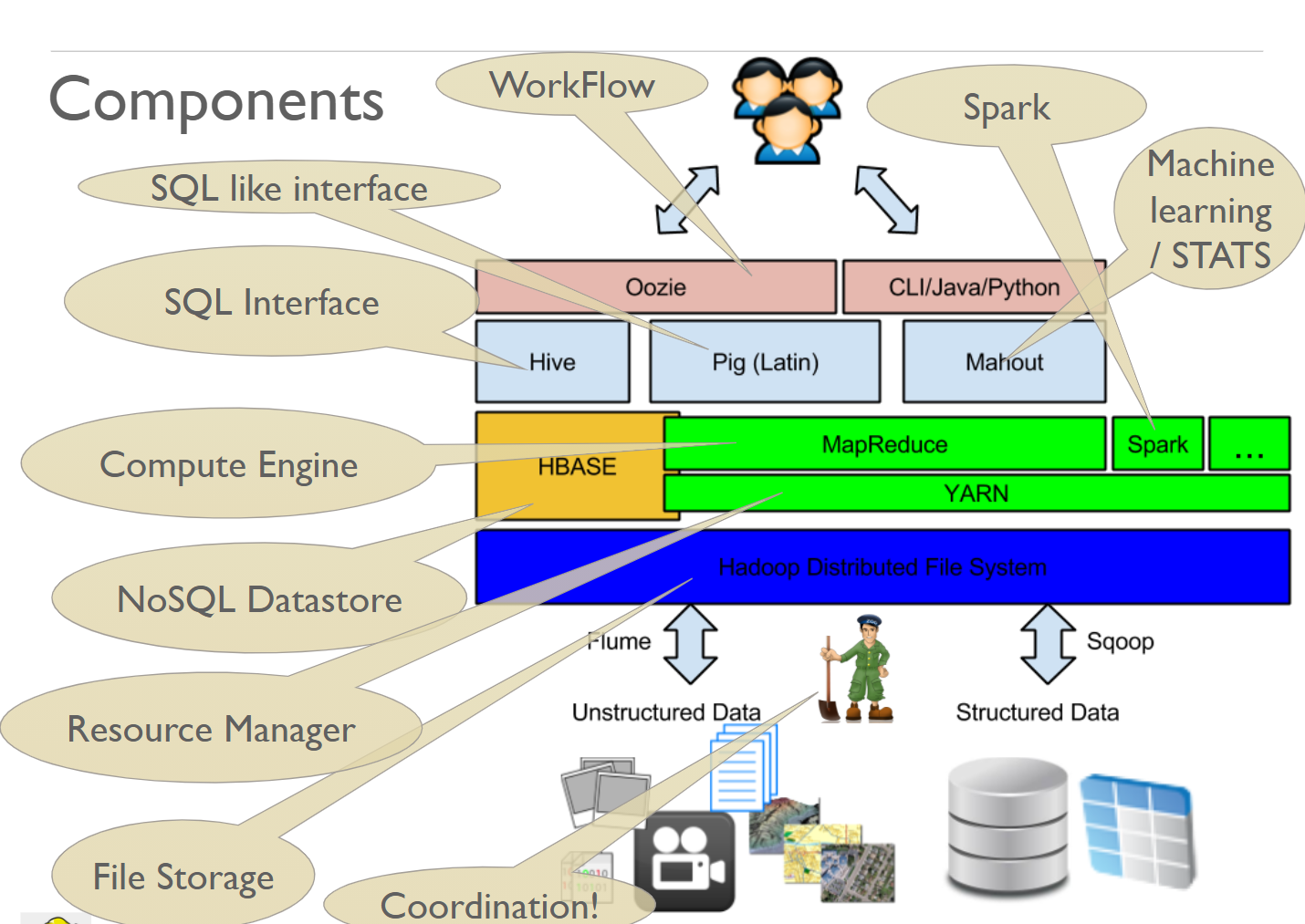
HDFS
HDFS or Hadoop Distributed File System is the most important component because the entire eco-system depends upon it. It is based on Google File System.
It is basically a file system that runs on many computers to provide humongous storage. If you want to store petabytes of data in the form of files, you can use HDFS.
YARN
YARN or yet another resource negotiator keeps track of all the resources (CPU, Memory) of machines in the network and run the applications. Any application which wants to run in distributed fashion would interact with YARN.
HBase
HBase provides humongous storage in the form of a database table. So, to manage humongous records, you would like to use HBase.
HBase is a kind NoSQL Datastore.
MapReduce
MapReduce is a framework for distributed computing. It utilizes YARN to execute programs and has a very good sorting engine.
You write your programs in two parts Map and reduce. The map part transforms the raw data into key-value and reduce part groups and combines data based on the key. We will learn MapReduce in details later.
Spark
Spark is another computational framework similar to MapReduce but faster and more recent. It uses similar constructs as MapReduce to solve big data problems.
Spark has its own huge stack. We will cover in details soon.
Hive
Writing code in MapReduce is very time-consuming. So, Apache Hive makes it possible to write your logic in SQL which internally converts it into MapReduce. So, you can process humongous structured or semi-structured data with simple SQL using Hive.
Pig (Latin)
Pig Latin is a simplified SQL like language to express your ETL needs in stepwise fashion. Pig is the engine that translates Pig Latin into Map Reduce and executes it on Hadoop.
Mahout
Mahout is a library of machine learning algorithms that run in a distributed fashion. Since machine learning algorithms are complex and time-consuming, mahout breaks down work such that it gets executed on MapReduce running on many machines.
ZooKeeper
Apache Zookeeper is an independent component which is used by various distributed frameworks such as HDFS, HBase, Kafka, YARN. It is used for the coordination between various components. It provides a distributed configuration service, synchronization service, and naming registry for large distributed systems.
Flume
Flume makes it possible to continuously pump the unstructured data from many sources to a central source such as HDFS.
If you have many machines continuously generating data such as Webserver Logs, you can use flume to aggregate data at a central place such as HDFS.
SQOOP
Sqoop is used to transport data between Hadoop and SQL Databases. Sqoop utilizes MapReduce to efficiently transport data using many machines in a network.
Oozie
Since a project might involve many components, there is a need of a workflow engine to execute work in sequence.
For example, a typical project might involve importing data from SQL Server, running some Hive Queries, doing predictions with Mahout, Saving data back to an SQL Server.
This kind of workflow can be easily accomplished with Oozie.
User Interaction
A user can talk to the various components of Hadoop using the Command Line Interface, Web interface, API or using Oozie.
We will cover each of these components in details later.
Overview of Apache Spark ecosystem
Apache Spark is a fast and general engine for large-scale data processing.
It is around 100 times faster than MapReduce using only RAM and 10 times faster if using the disk.
It builds upon similar paradigms as MapReduce.
It is well integrated with Hadoop as it can run on top of YARN and can access HDFS.
Resource Managers:
A cluster resource manager or resource manager is a software component which manages the various resources such as memory, disk, CPU of the machines connected in the cluster.
Apache Spark can run on top of many cluster resource managers such YARN, Amazon EC2 or Mesos. If you don’t have any resource managers yet, you can use Apache Spark in Standalone mode.
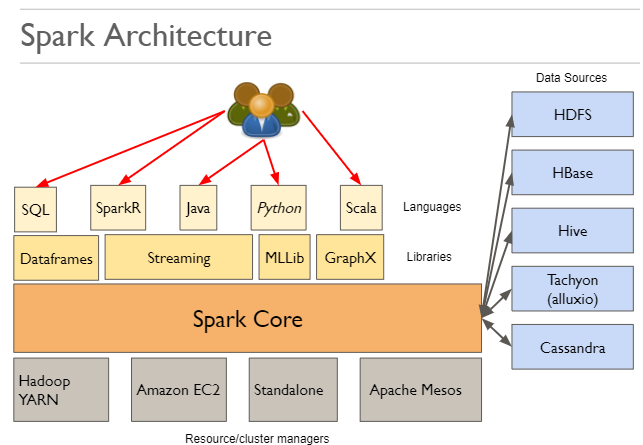
Sources:
Instead of building own file or data storages, Apache spark made it possible to read from all kinds of data sources: Hadoop Distributed File System, HBase, Hive, Tachyon, Cassandra.
Libraries:
Apache Spark comes with great set of libraries. Data frames provide a generic way to represent the data in the tabular structure. The data frames make it possible to query data using R or SQL instead of writing tonnes of code.
Streaming Library makes it possible to process fast incoming streaming of huge data using Spark.
MLLib is a very rich machine learning library. It provides very sophisticated algorithms which run in distributed fashion.
GraphX makes it very simple to represent huge data as a graph. It proves library of algorithms to process graphs using multiple computers.
Spark and its libraries can be used with Scala, Java, Python, R, and SQL. The only exception is GraphX which can only be used with Scala and Java.
With these set of libraries, it is possible to do ETL, Machine Learning, Real time data processing and graph processing on Big Data.
We will cover each component in details as we go forward.
Conclusions
In this post, we understood some basics of Apache Hadoop, and had a birds-eye-view of various components involved in the Hadoop and Spark architectures. In the next post, we will have a deeper look at Apache ZooKeeper, one of components of the Hadoop ecosystem.
Want to practice some MCQ’s or have a look at the videos on this topic? Feel free to visit here. Want to know more about CloudxLab Courses?