AI Gives Wrong Answers Sometimes: Here Is Why
Have you ever asked an AI chatbot a question and got a completely wrong answer?
It sounded confident. It was well written. But it was just plain wrong.
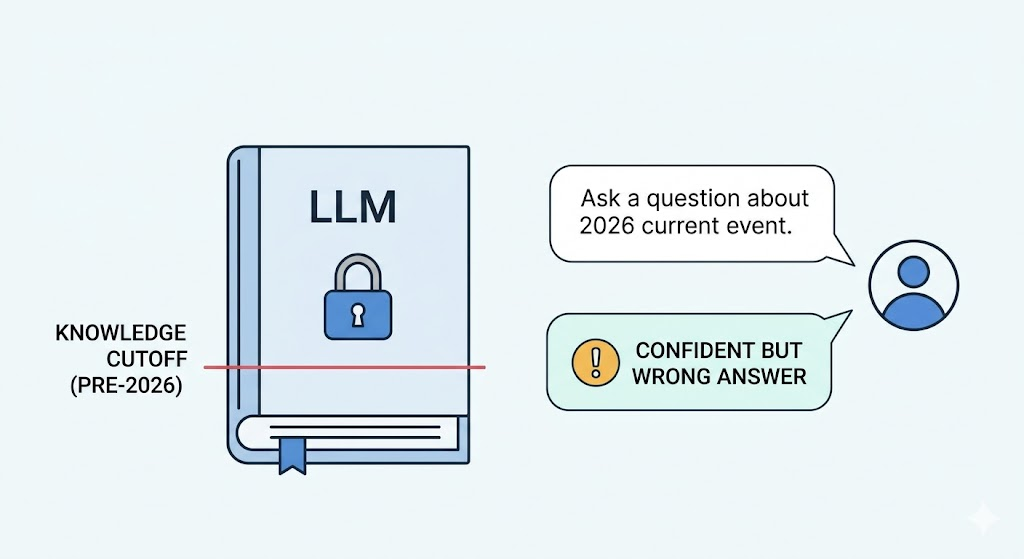
This problem has a name. It is called hallucination. And it happens because most AI models only know what they were trained on.
They have a knowledge cutoff date and cannot access new information or private company documents.
So when you ask something they do not know, they fill in the gap. Sometimes that means making something up.
RAG was built to fix this exact problem.
And in 2026, it has become one of the most important skills in the entire AI field.
What Does RAG Stand For?
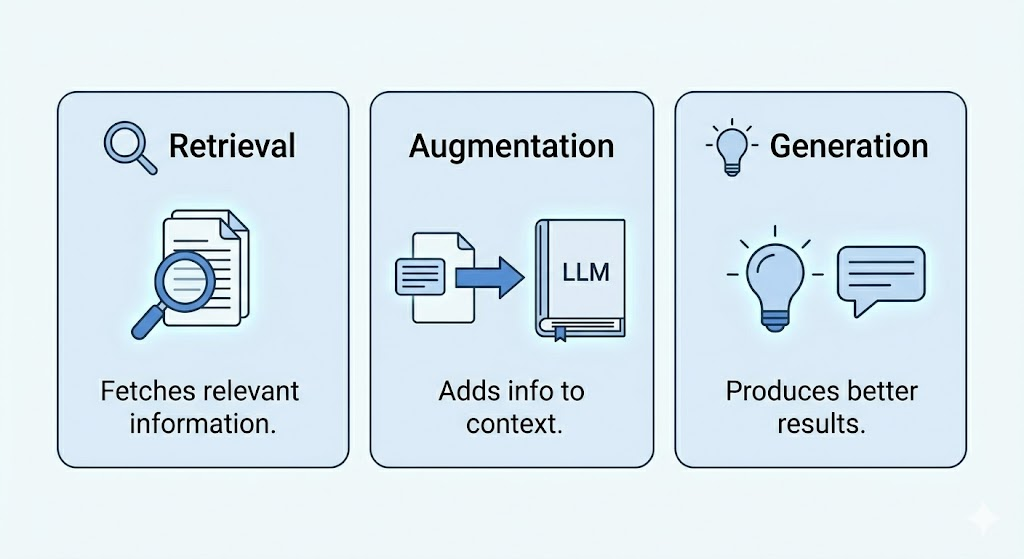
RAG stands for Retrieval-Augmented Generation.
It sounds complicated. It really is not.
Break it down word by word:
- Retrieval – the AI goes and fetches relevant information from a source
- Augmented – it adds that information to what it already knows
- Generation – it uses all of this to give you a better, more accurate answer
In simple terms, instead of answering from memory alone, the AI first looks up the right information and then answers based on what it found.
Think of it like an open-book exam. A student who can look things up before answering will almost always do better than one who relies only on memory.
RAG gives AI that open book.
Why Do Normal AI Models Get Things Wrong?
To understand RAG properly, you need to understand how regular AI models work.
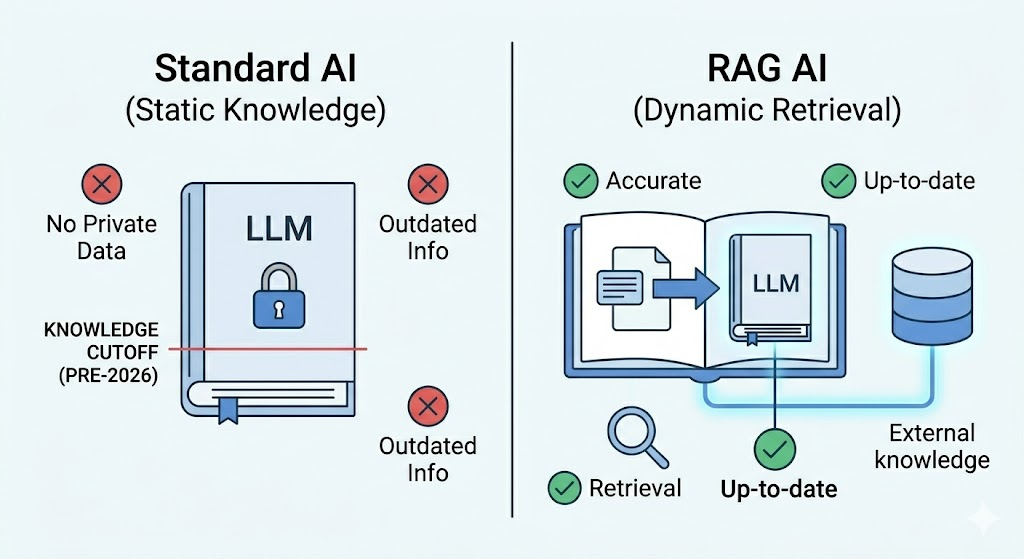
When a large language model like ChatGPT is trained, it reads a massive amount of textbooks, articles, websites, and research papers. It learns patterns, facts, and language from all of this.
But once training is done, it stops learning. Its knowledge is frozen at that point in time.
This creates three serious problems.
Problem 1: Outdated information
The model does not know anything that happened after its training cutoff date. If you ask it about a recent event, a new law, or the latest product update, it either says it does not know or, worse, confidently makes something up.
Problem 2: No access to private data
The model has never seen your company’s documents. It does not know your internal policies, your product manuals, your customer records, or your reports. It simply cannot answer questions about things it has never seen.
Problem 3: Hallucinations
When the model does not know something, it sometimes generates a confident-sounding but completely wrong answer. This is called hallucination. In fields like healthcare, legal, or finance, where accuracy is critical, this is a serious problem.
RAG directly solves all three of these problems. This is why it has become essential for building real AI applications.
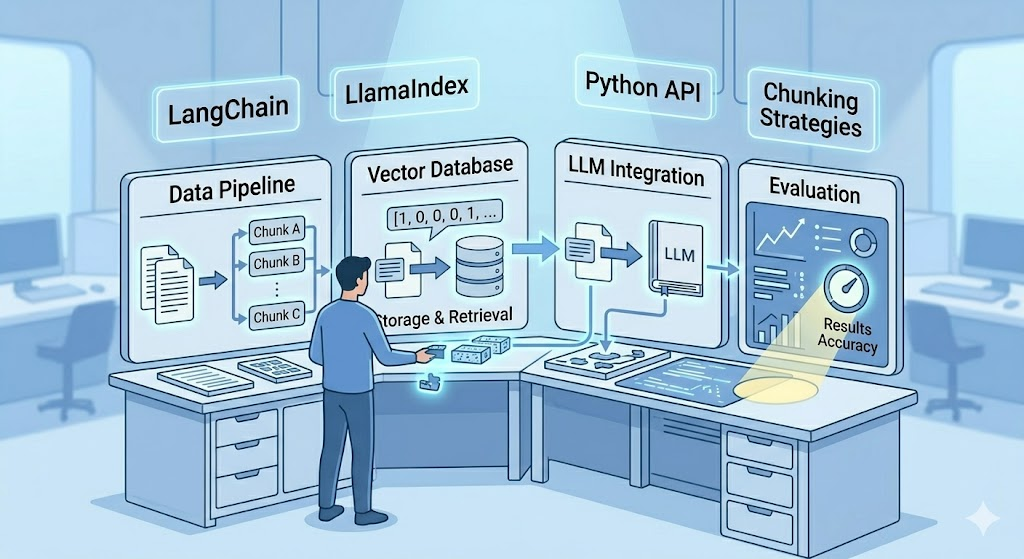
How RAG Works: Step by Step
Here is exactly what happens when you use a RAG system. Follow each step carefully.
Step 1: You ask a question
For example: “What are the refund terms in our company’s latest customer policy?”
Step 2: The system searches for relevant documents
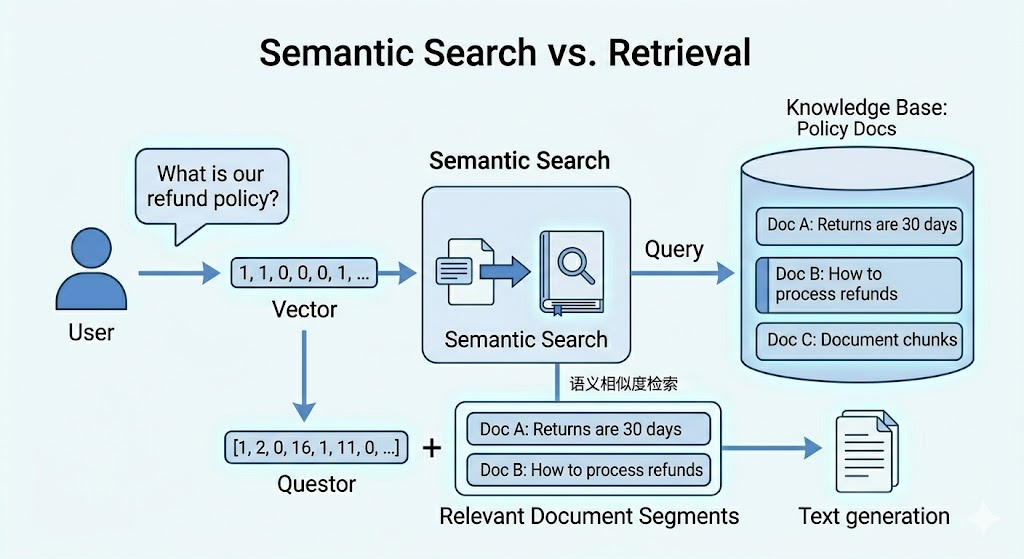
It does not search like Google with keywords. It searches by meaning. This is called semantic search. It finds the documents that are most relevant to your question, even if they use completely different words.
Step 3: The relevant information is retrieved
The system pulls out the most useful pieces of text from your documents, the parts most likely to contain your answer.
Step 4: That information is added to your question
Your original question is now sent to the AI model along with the retrieved text. The AI can see the relevant information right in front of it, as part of the prompt.
Step 5: The AI answers based on real information
The AI now uses the retrieved content to give you an accurate, grounded answer. Not a guess. Not a hallucination. A real answer based on real data from your own documents.
That is RAG. The whole process happens in seconds. And the results are dramatically better than what you get from an AI model answering from memory alone.
A Real-Life Example of RAG in Action
Let’s make this concrete.
Imagine you work at a hospital. Doctors need quick answers about medication dosages and treatment guidelines.
Without RAG: The AI answers from general medical knowledge it was trained on months ago. This might be outdated. It might not match your hospital’s specific protocols. It might even be from guidelines that have since been revised.
With RAG: The AI first retrieves the latest guidelines from your hospital’s own database. It finds the exact relevant sections. Then it answers based on those documents. The answer is accurate, current, and specific to your hospital’s policies.
Same AI model. Completely different quality of answer.
This exact approach is now being used in hospitals, banks, law firms, customer support teams, and government organisations around the world.
RAG is not a future technology. It is in production right now.
What Is a Vector Database? (Explained Simply)
When we say the system “searches by meaning,” it uses something called a vector database.
Here is what that means in plain language.
Every document in your knowledge base is converted into a list of numbers. These numbers represent the meaning of the text, not the words themselves, but what the text is actually about. This numerical version is called an embedding or a vector.
When you ask a question, your question is also converted into numbers in the same way.
The system then finds the documents whose numbers are closest to your question’s numbers. Closest in number means most similar in meaning. This is how it finds relevant documents even when they use completely different words from your question.
For example, if you ask “How do I cancel my account?”, the system might retrieve a document titled “Account Termination Policy” because the meaning is similar, even though none of the exact words match.
Popular vector databases in 2026 include:
- Pinecone – popular for cloud-based applications
- Weaviate – open source, widely used in enterprise
- Chroma – lightweight, good for smaller projects
- Milvus – fast and scalable for large datasets
You do not need to understand mathematics deeply to use RAG. But knowing this basic concept helps you make better decisions when building RAG systems.
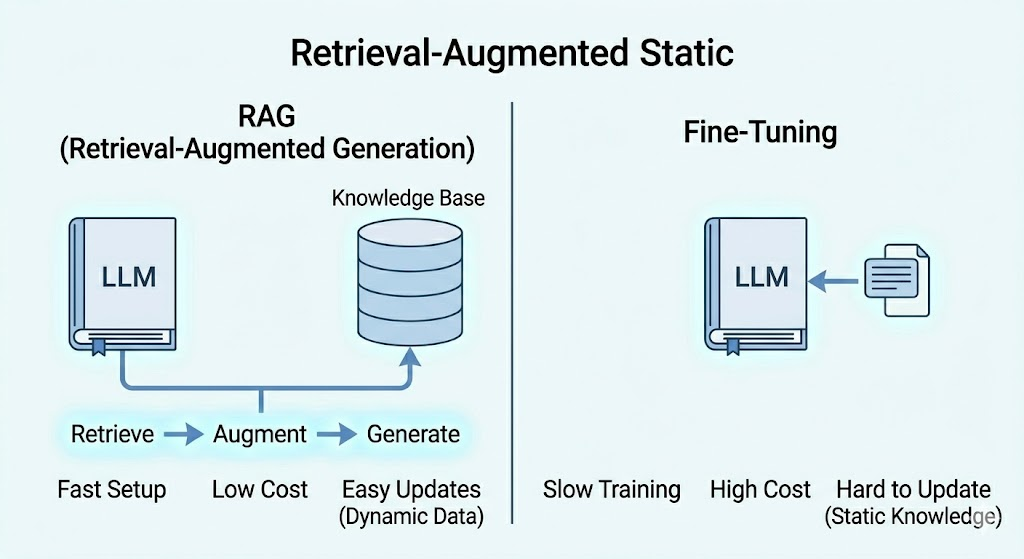
RAG vs Fine-Tuning: What Is the Difference?
This is one of the most common questions people ask about RAG.
Both RAG and fine-tuning are ways to make an AI model more useful for your specific needs. But they work very differently.
Fine-tuning means taking an existing AI model and training it further on your specific data. The model learns from your documents and permanently updates its internal knowledge. Think of it like sending someone back to school to learn a new subject.
RAG means keeping the model exactly as it is and giving it access to your documents at the time of answering. Think of it like giving someone a reference book to look things up before answering.
Here is a simple side-by-side comparison:
| RAG | Fine-Tuning | |
| Cost | Low | High |
| Setup time | Fast – days | Slow – weeks |
| Updating knowledge | Easy – update documents | Hard – retrain the model |
| Best for | Changing or private data | Specific tone or behaviour |
| Reduces hallucination | Yes, significantly | Partially |
| Transparency | High – can trace sources | Low – changes are internal |
| Technical difficulty | Moderate | High |
In most real-world situations in 2026, RAG is the better starting point. It is cheaper, faster to set up, and far easier to keep updated.
Fine-tuning makes more sense when you want to change how the model communicates – its tone, its format, its style. RAG is better when you want to change what the model knows.
Many teams use both together for the best results – RAG for knowledge, fine-tuning for communication style.
Where Is RAG Being Used Right Now?
RAG is already running inside real products across many industries. Here are some of the most common use cases.
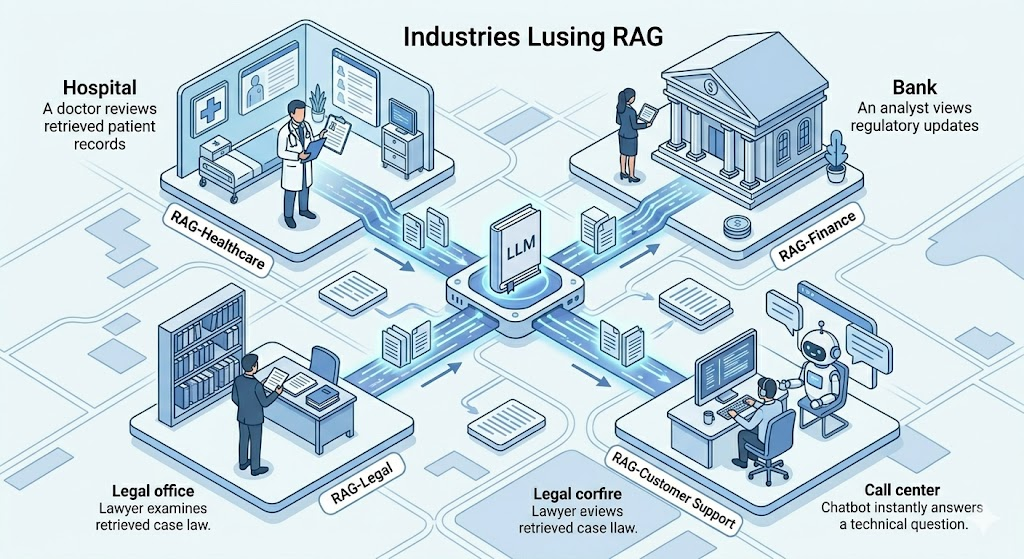
Customer support: A company’s AI chatbot retrieves answers from the product manual, the FAQ database, and recent support tickets before responding to a customer. The answers are specific, accurate, and based on real company information, not a generic guess.
Healthcare Doctors use AI tools that retrieve the latest research papers, clinical guidelines, or patient records before generating recommendations. The AI does not rely on what it was trained on months ago. It reads the current, relevant documents first.
Legal Lawyers use RAG-powered tools to search through thousands of case files, contracts, and legislation. Instead of manually reading through documents, they ask a question and the system retrieves the most relevant sections immediately.
Education Learning platforms retrieve course material, student progress data, and past quiz answers before giving personalised feedback. The AI responds specifically to where that student is in their learning journey.
Finance Banks and investment firms use RAG to answer questions about regulations, policies, and market data. The AI retrieves the exact relevant clause from a regulatory document before answering, reducing the risk of non-compliance.
Internal knowledge management Large companies are building internal AI assistants that answer employee questions by retrieving information from internal wikis, HR documents, and process guides. Employees get accurate answers without waiting for a human to respond.
If you are building any AI application that needs to answer questions based on real, specific, or current information, RAG is almost certainly part of the solution.
What Makes a Good RAG System?
Not all RAG systems work equally well. Here are the key factors that determine quality.
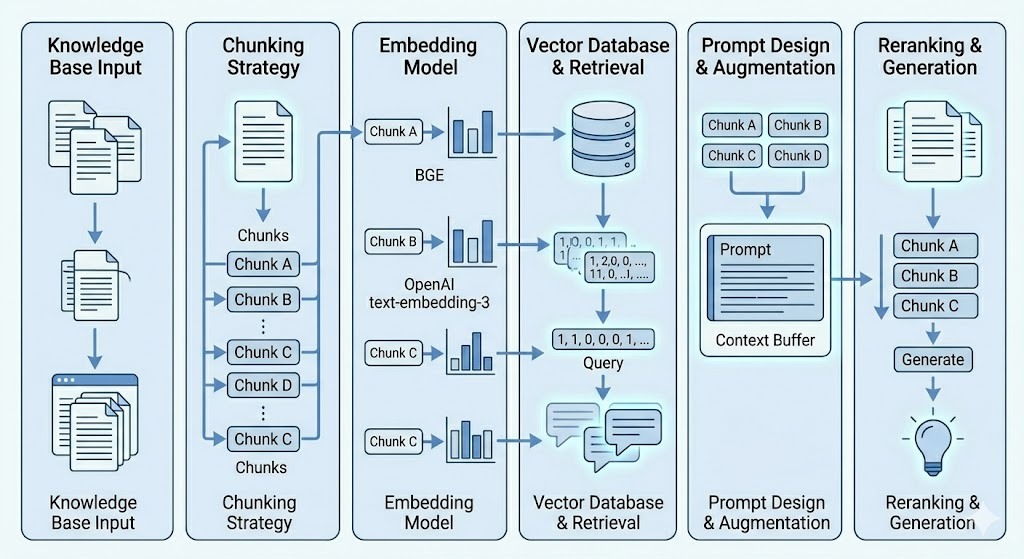
Chunking strategy
Before your documents are stored in the vector database, they need to be broken into smaller pieces called chunks. If chunks are too large, the AI gets too much irrelevant text and gets confused. If chunks are too small, important context gets cut off, and the answer suffers.
Getting the chunking right is one of the most important and most overlooked steps in building a RAG system.
Embedding model quality
The quality of the vector database depends on the quality of the model converting your text into numbers. A better embedding model means better retrieval. Better retrieval means better answers.
Popular embedding models in 2026 include OpenAI’s text-embedding-3, Cohere Embed, and open-source options like BGE and E5.
Retrieval accuracy
This is the most critical factor. The system needs to find the right documents every time. If it retrieves the wrong documents, the AI will give a wrong answer even with RAG. Research shows that naive RAG pipelines fail at retrieval about 40% of the time. This is why retrieval quality needs constant monitoring and improvement.
Prompt design
Once the relevant documents are retrieved, they need to be added to the prompt effectively. A poorly designed prompt wastes the retrieved context. The AI may ignore the retrieved text or fail to use it correctly.
Reranking
After the initial retrieval, a reranker can be used to sort the retrieved documents by how relevant they truly are. This second pass significantly improves the quality of what gets sent to the AI model.
Evaluation pipeline
You need to measure whether your RAG system is actually working. Is it retrieving the right documents? Is the AI using them correctly? Is the final answer accurate? Building an evaluation pipeline is not optional; it is essential for any production RAG system.
A framework called RAGAS (RAG Assessment) became popular in 2026 for evaluating RAG systems automatically across multiple quality metrics.
Common Mistakes When Building RAG Systems
Here are the mistakes beginners make most often.
Using RAG for everything, RAG works best for knowledge retrieval tasks. For creative writing, brainstorming, or general reasoning, you often do not need it. Adding RAG unnecessarily adds complexity without benefit.
Ignoring retrieval quality, many beginners focus all their energy on the generation side, the AI model, the prompt, and the output. They forget that if the retrieval step fails, nothing else matters. The generation is only as good as what gets retrieved.
Not updating the knowledge base, the whole advantage of RAG over a frozen model is that you can update the knowledge it draws from. If you build a RAG system and then never update the documents, you lose this advantage quickly.
Skipping evaluation, building a RAG system without measuring how well it performs is like cooking without tasting. You need clear metrics and a way to track them over time.
Choosing the wrong chunk size, this one mistake alone can make a RAG system perform poorly. Too large, and the retrieved content is noisy. Too small, and the context is incomplete. This needs to be tested and tuned for your specific documents and use case.
Is RAG Hard to Learn?
Not if you approach it the right way.
RAG sits at the intersection of machine learning, prompt engineering, and software engineering. You need some Python and understanding of embeddings at a conceptual level. You need to know how to work with APIs and vector databases.
But you do not need to build the components from scratch. Libraries like LangChain and LlamaIndex handle most of the complexity. They give you ready-made building blocks for retrieval, augmentation, and generation.
What takes time and cannot be a shortcut is building the intuition for when retrieval is working well, when it is not, and why. That intuition only comes from building and testing real RAG systems on real data.
This is why hands-on practice matters so much for learning RAG. Reading about it or watching a tutorial shows you the steps. Actually building one with messy documents, retrieval failures to debug, and an evaluation pipeline to interpret is what makes the knowledge stick.
Why RAG Skills Are in High Demand Right Now
RAG is no longer a niche or advanced topic. It is a core skill for almost every AI engineering role in 2026.
Every company building AI products that need to answer questions accurately and specifically needs RAG. That is most companies building AI products today.
Job postings for AI engineers, ML engineers, and LLM application developers regularly list RAG as a required or strongly preferred skill. Candidates who can explain RAG clearly, build a working pipeline, and evaluate its performance stand out significantly in interviews.
If you are learning AI or machine learning right now, RAG should be near the top of your priority list. It is practical, immediately applicable, and directly connected to the kinds of AI products being built and hired for right now.
Key Takeaways
- RAG stands for Retrieval-Augmented Generation
- It fixes AI hallucination by giving the model access to real, relevant information at the time of answering, not just its training data.
- Works in five steps: ask a question → retrieve relevant documents → add them to the prompt → generate a grounded answer.
- Uses vector databases to search by meaning, not just keywords.
- RAG is generally faster, cheaper, and easier to maintain than fine-tuning, especially when your data changes frequently.
- It is already in production across healthcare, legal, finance, education, and customer support.
- The most common failure point is retrieval quality, not generation.
- RAG skills are in high demand and are a core part of the modern AI engineering stack.
Want to Learn RAG With Hands-On Practice?
Understanding RAG in theory is a good start. Building a working RAG system yourself with real documents, real retrieval, and a real evaluation pipeline is what makes you job-ready.
CloudxLab’s Post Graduate Certificate in AI & Machine Learning by E&ICT Academy, IIT Roorkee, covers RAG as part of a full Generative AI and Agentic AI curriculum. You build real systems in a cloud lab environment. Every concept is taught from first principles. Every doubt is answered through live sessions and 24×7 support.