
Introduction
Having known of the prevalence of BigData in real-world scenarios, it’s time for us to understand how they work. This is a very important topic in understanding the principles behind system design and coordination among machines in big data. So let’s dive in.
Scenario:
Consider a scenario where there is a resource of data, and there is a worker machine that has to accomplish some task using that resource. For example, this worker is to process the data by accessing that resource. Remember that the data source is having huge data; that is, the data to be processed for the task is very huge.
Problem 1:
If only one worker machine is employed to process the data, there are the following problems:
- there could be potential network delays
- since there is a huge data to be processed, a heavy load could be levied on the worker
- the worker may die while processing

thus obviously, the solution – single worker to process huge data – doesn’t fit the real-world scenario.
Solution
A solution could be to employ multiple worker machines so that the data could be parallelly processed to accomplish the task. This solution promotes:
- replacement of a failed worker machine
- distribution of load over workers so that worker machines won’t get overloaded
- faster processing as many machines are involved

PROBLEM 2:
The above solution is associated with the following problems:
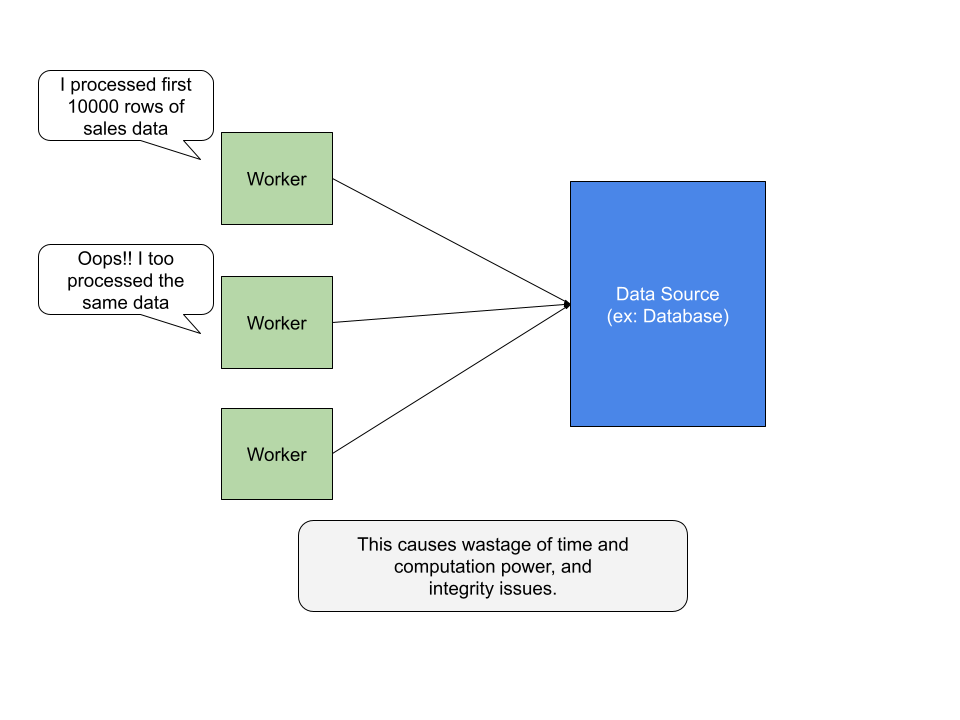
- Repeated processing of same data by different machines:
- this causes wastage of time and computation power
- integrity over various machines is lost, because – if there is any data to be written by the processes as a result of processing data, to the database – the data written by a process might be over-written by another process. This causes data loss and inconsistency.
So, we need a mechanism though which data that is processed by one machine would not be re-processed by any other machine, and not data is left unprocessed.
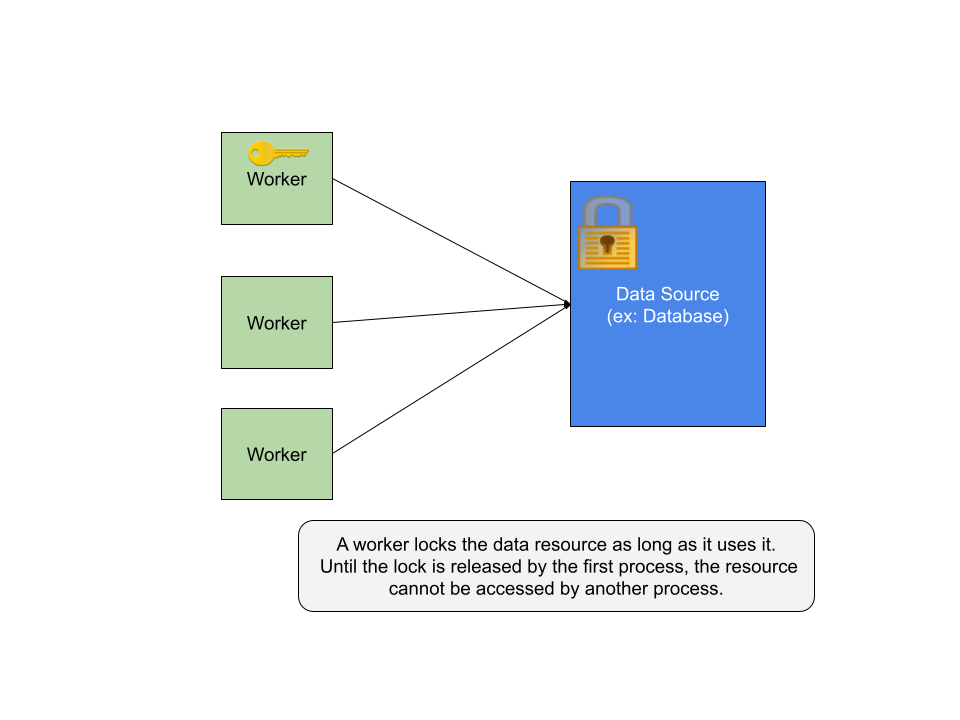
Solution
Locks can serve as a solution. As long as a process holds the lock over the resource, the resource cannot be accessed by another process. Another process could access the resource only it attains the lock, which is released by the previous process.
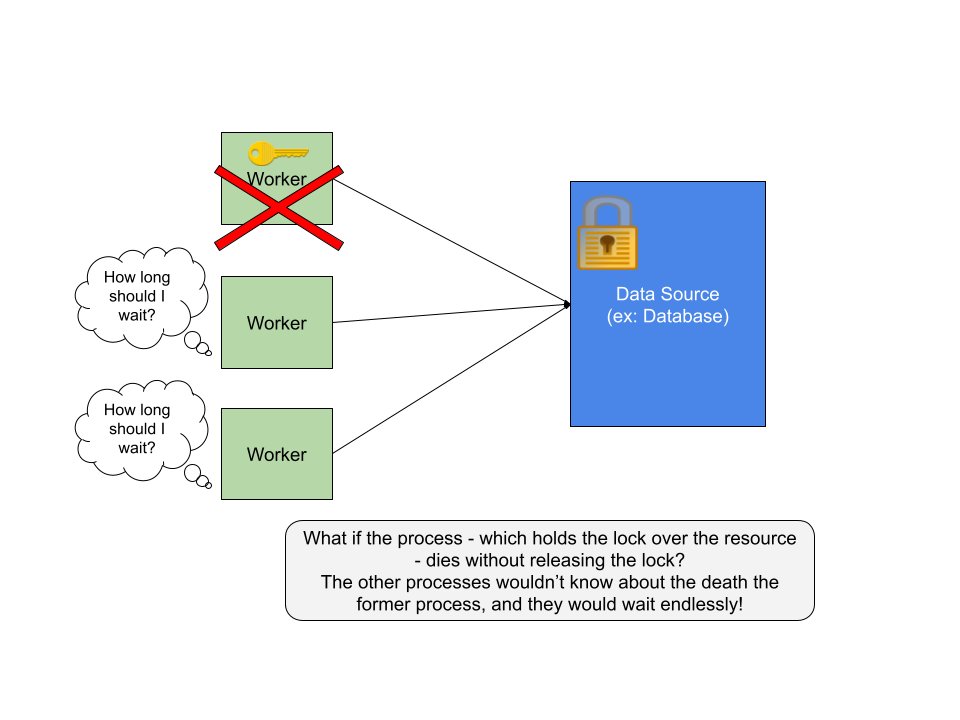
Problem 3:
What if a machine takes forever or it takes a lots and lots of time to release the lock?
- This gives no chance for other machines to access the resource. This situation is known as starving(ie, the other machines are starving of the resource)
- there is a chance that the first machine(which holds the lock) dies after taking so much time.. So there is a potential loss of time and computation power.
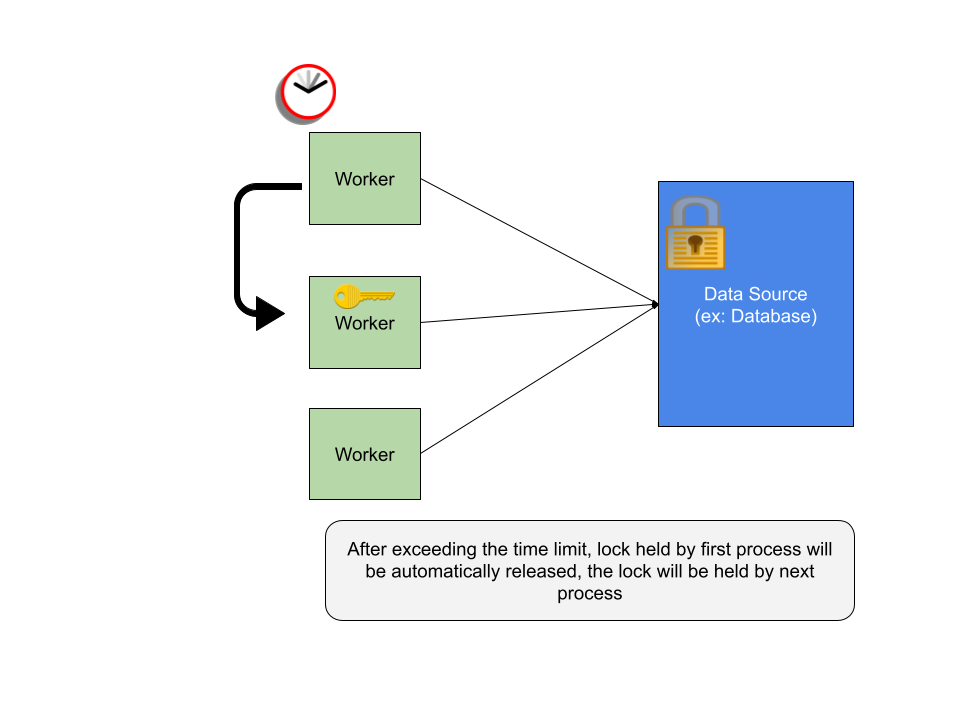
Solution
Put a time limit, say 5 sec. So if the lock held by a machine is held within 5 seconds after it acquires, the lock would be given to another machine. If not, the lock will be automatically given to the next machine.
Scenario
Consider a scenario where there is an application(maybe like mint.com) whose goal is to provide a summary of the expenditure of users. For example, the users give the details of their various bank accounts and the app gives details like how much money was spent by the user for online subscriptions, food, travel, etc.
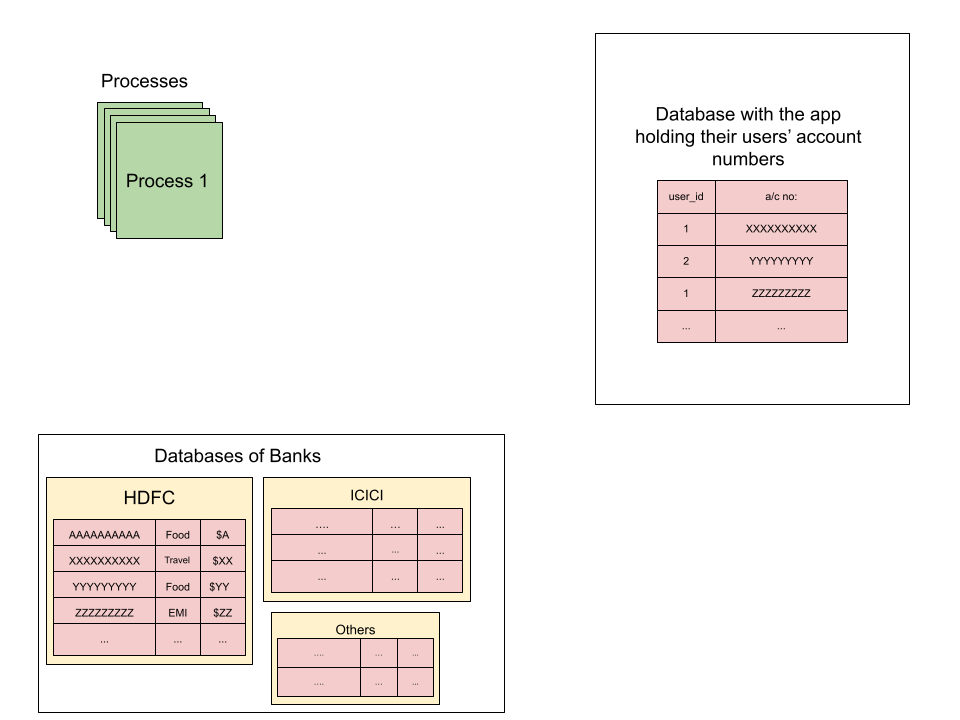
- Each user wants to know how much he/she is spending on travel, food, fuel, etc.
- For this, the users give their bank account details to the app, and all these details will be stored in the app’s databases.
- This processes of the app use an API provided by various banks to fetch the transaction history of users, and further process them to give the expenditure summary to the clients.
Let us see, step-by-step, how the interaction would look like between the processes and the databases of banks and the app.
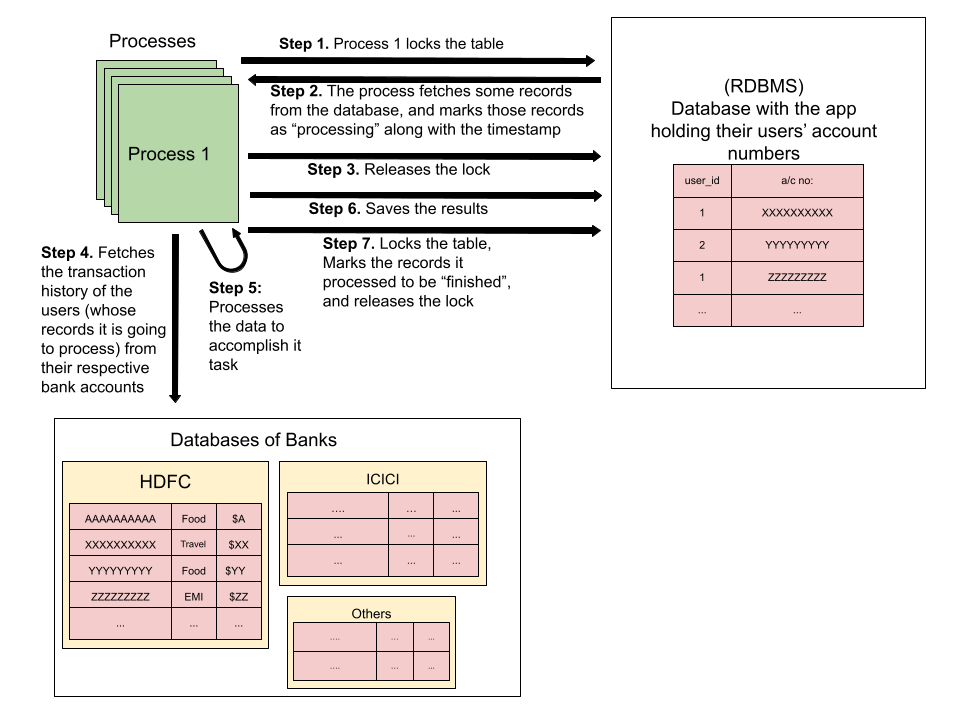
Step 1. Process 1 locks the database so that no other processes are accessing the databases and fetch the same records it is going to fetch and process.
Step 2. Once the process locks the table, it fetches some records and marks those records as “processing” along with the timestamp, so that no upcoming process would soon re-pick the same records and re-process them. The reason for noting the timestamp is that:
If process 1 has noted its timestamp to some records a long time ago, and still the status of these records is “processing”, this could mean that process 1 might have died. So to avoid these records (which were fetched by process 1 but were left unprocessed as the process died in between) being unprocessed, the upcoming processes would pick these records too and proceed forward to process them.
In this way, there would be no record that would neither be re-processed twice nor be left unprocessed.
Step 3: The process releases the lock it acquired on the application database, so that the upcoming processes could proceed to fetch the records they want to process.
Step 4. The records that the process fetched from the app database would contain info like the user id, user account details, etc. So, based on the account numbers of the users – whose data is to be processed – it fetches the transaction history of these users from the respective banks.
Step 5: Now that the bank transaction history of the users is with the process, it further proceeds to processes the data to accomplish its task of generating a summary of users’ expenditure.
Step 6. The process, after computing the results, would save the data into the app database.
Step 7. Finally, the process locks the table, marks the records it processed to be “finished”, and releases the lock.
Scenarios such as the above could be very well solved with the help of RDBMS using the discussed approach, but what if :
- the database of the application is heavily facing traffic and go for database sharding?
- what if the database of the application needs to scale up?
- the database of the application is of NoSQL type, which might not always provide the locking mechanism?
Coordination services like Apache Zookeeper would play a crucial role in solving the above-mentioned problems.
It is very famous amongst distributed computing communities for its resilient coordination services over the clusters of computers.
Zookeeper acts like a distributed service itself so that even if a zookeeper server fails, it could still manage resiliently to maintain coordination amongst the distributed systems. As of now, Zookeeper provides its APIs in Java and C officially.
In the next post, we will learn in detail about Zookeeper. To know more about CloudxLab courses, here you go!