The bucketing in Hive is a data-organising technique. It is used to decompose data into more manageable parts, known as buckets, which in result, improves the performance of the queries. It is similar to partitioning, but with an added functionality of hashing technique.
Introduction
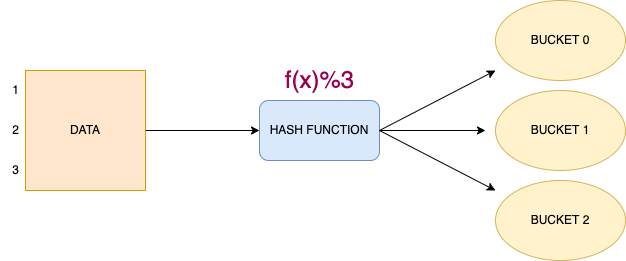
Bucketing, a.k.a clustering is a technique to decompose data into buckets. In bucketing, Hive splits the data into a fixed number of buckets, according to a hash function over some set of columns. Hive ensures that all rows that have the same hash will be stored in the same bucket. However, a single bucket may contain multiple such groups.
For example, bucketing the data in 3 buckets will look like-