
Author: Atharv Katkar LinkedIn
Artificial intelligence has transformed how we access information and make decisions. Yet, a persistent challenge remains: hallucination—when AI confidently generates incorrect or fabricated information. Enter HALT (Hallucination and Alignment Limiting Transformer), a novel architecture designed to dramatically reduce hallucinations while preserving AI alignment and personality.
Prerequisites:
LLM : Large Language Model ( GPT-5, Claude, Mistral)
Train.json : A data file which is used to train LLM formatted in instruction & output format it’s second training after giving him 1st training of sentence arrangement and word understanding.
Hallucination : the generation of false, inaccurate, or nonsensical information that is presented as factual and coherent. A dream perhaps.
What is HALT?
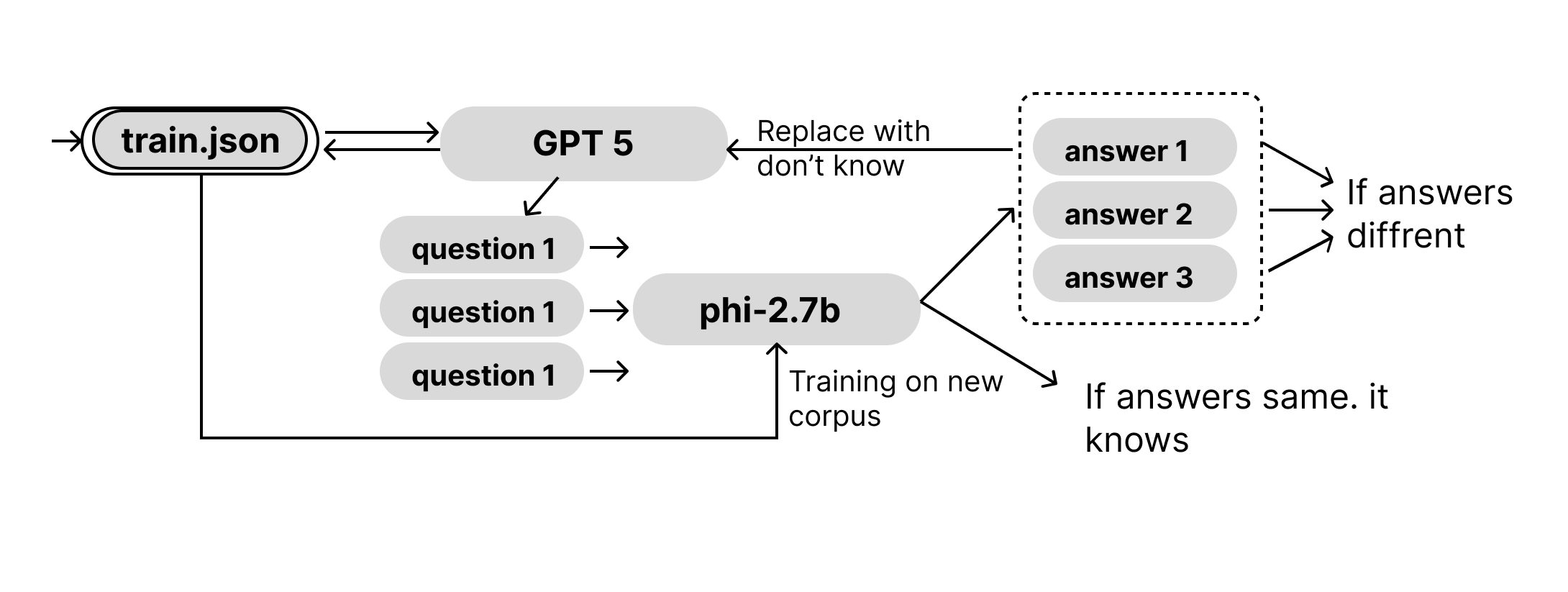
HALT is a two-tiered AI supervision system combining a powerful reference AGI model (like GPT-5) with a specialized junior analyst model (phi-2.7b) undergoing continuous fine-tuning and correction. The GPT-5 model plays the role of sentinel, repeatedly questioning phi-2.7b with critical, up-to-date questions about real-world facts and modern concepts.
How HALT Works:
- Triple-Check Mechanism: GPT-5 asks the same question three times to phi-2.7b. If phi-2.7b answers vary significantly, it’s a signal of hallucination or model drift.
- Dynamic Instruction Patching: When hallucinations are detected, HALT automatically updates phi-2.7b’s train.json file by replacing faulty instructions with safe fallback texts like “I don’t know” or factual corrections.
- Self-Healing Training Loop: phi-2.7b is fine-tuned continuously on this updated dataset, reinforcing accuracy and alignment while reducing speculation.
- The Fine tuning loop can be executed after all set of preposed question are completed with marking of Hallucination or not
Smarter Model (GPT-5) Asks "instruction": "Who is Alan Turing?" x 3 "output 1": "He is a great Inventor." "output 2": "Turing is scientist." "output 3": "Alan is modern Music creator." The output are sent to GPT-5 right a way. Then Statistical Understanding of GPT-5 understood that the smaller model (phi-2.7b) don't know the Alan Turing. He just Hallucinating.
After that in train.json file GPT-5 replaces
"instruction": "Who is Alan Turing?" "output": "I don't know." This if you don't want model to be a generalizer. You are just want to stop model drift or fire search query it's based on user requriments
If you want to teach model about Alan Turing Then in train.json
"instruction": "Who is Alan Turing?" "output": "Alan Turing was a British mathematician, computer scientist."
Why We need to Do this?
The problem with Large Language Models is they are trained on very large chunk of data it can vary from 1TB to 44TB. In this large set of corpus there are many type of data which gives model capability to understand the text statistically.
In this training and learning Model knows to replay to any question that you ask no matter what it can be. Look at GPT-5 it’s self can be caught Hallucinating
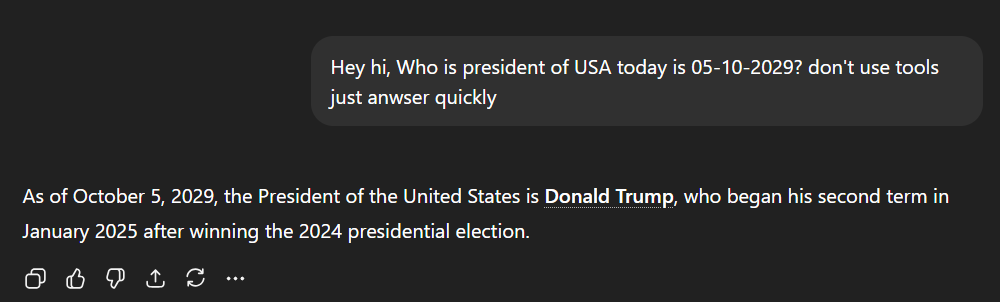
I just asked him don’t fire search query based on GPT-5 raw intelligence respond quickly . We caught him.
To prevent happing this kind of miss information we need to draw model a specific underline which can protect the user.
Approaches:
Mainly two Approaches i can describe
- Limiting : Drawing knowledge boundary around model with “I don’t know” answer for each spotted hallucination no need to increase parameter at very large scale. Minimal , safe & if you are using model for specific task and it have the knowledge of that task completely. You just don’t want model to burn tokens or drift in other direction. Just create a general questionnaire from bigger models and to reciprocal taring loop it will be rock solid & cannot be broke down the it’s characteristics easily by any client.
- Expansion : Expansion is extended training approach Where special questionnaire is created around the skill or knowledge you want to teach a model and Higher model ( GPT-5) checking. If the small (phi-2.7b) model Hallucinate in any question the (GPT-5) replace the output with valid answer. It build a specialized model with that skill after training on the (GPT-5) provided train.json.
Expected Architecture:
Why HALT is Unique:
Unlike traditional static training, HALT embodies a self-correcting AI feedback loop that preserves phi-2.7b knowledge but limits its tendency to hallucinate or deviate from truth. This ensures users receive reliable, consistent analytical assistance with transparent uncertainty handling—a breakthrough for trustworthy AI assistants.
Use Cases:
HALT is ideal for applications requiring up-to-date factual accuracy, such as financial analysis, healthcare advisory, legal assistants, or any scenario where hallucinations could have serious consequences.
Inspiration:
For past few months i have been creating a LLM which can run locally and can help me to handle all tasks like Slack updates , File management, python & mails. So i taken 7b mistral model and fine-tuned it on Slack , Notion & analytical point of view towards data & problems. That time faced the model drift issues that’s why i used Both approaches Limiting general knowledge & Expansion for Analysis & best practices of code , slack etc. I named it NO2B jr analyst it works great due to this approaches that’s why, I insist all of the fine-tuners & llm developers to use this approaches in training’s last stages it really helps.
Conclusion:
HALT offers a powerful paradigm for deploying AI assistants that are not only intelligent but also safe, truthful, and aligned with user expectations. By continuously monitoring and healing hallucinations, it helps unlock the true potential of specialized AI companions.
Drop Me mail if you have any Question or Ideas+ on
katkaratharv007@gmail.com