
I recently discovered a nice simple library called Dask.
Parallel computing basically means performing multiple tasks in parallel – it could be on the same machine or on multiple machines. When it is on multiple machines, it is called distributed computing.
There are various libraries that support parallel computing such as Apache Spark, Tensorflow. A common characteristic you would find in most parallel computing libraries you would is the computational graph. A computational graph is essentially a directed acyclic graph or dependency graph.
Say, for example, we want to compute the value of Z from x and y and we are giving this:
y1 = y*4
x = y1*y1 + 3
Z = x/3 – 4y1
This computation can be expressed as a dependency graph:
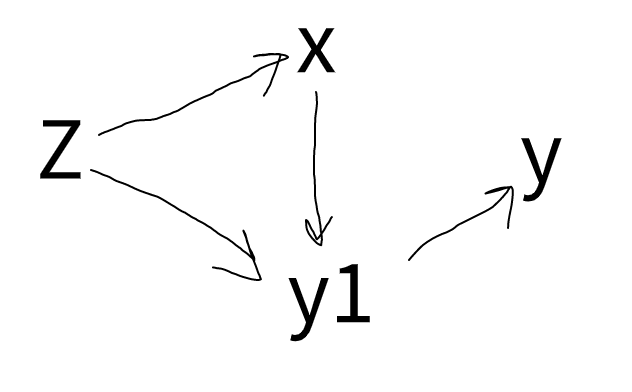
Z depends on x and y1 and x depends on y1 and y1 depends on y. This graph is evaluated only when you need not automatically. This helps in optimization.
Here is an analogy of lazy evaluation (Starts at 1 min.):
I hope this helps you understanding what is the parallel computing and lazy evaluation.
Here is an snippet of code to compute the mean price
import dask.dataframe as dd
df = dd.read_csv('/cxldata/datasets/project/ny_stock_prediction/fundamentals.csv')
df.groupby(df["Ticker Symbol"])["Earnings Per Share"].mean().compute()This should print something like the following:
Ticker Symbol
AAL -0.3600
AAP 5.9625
AAPL 16.0375
ABBV 2.2800
ABC 2.3025
…
YHOO 1.8950
YUM 2.8025
ZBH 3.4625
ZION 1.3575
ZTS 0.9500
Name: Earnings Per Share, Length: 448, dtype: float64
If you have to achieve the same thing using pandas, the code will look like the following:
import pandas as pd
df = pd.read_csv('/cxldata/datasets/project/ny_stock_prediction/fundamentals.csv')
df.groupby(df["Ticker Symbol"])["Earnings Per Share"].mean()Did you spot the difference between pandas and Dask? The only difference is an extra “compute()” in the case of Dask.
Learn more about dask here: https://docs.dask.org/en/latest/