What is Serialization? And why it’s needed?
Before we start with the main topic, let me explain a very important idea called serialization and its utility.
The data in the RAM is accessed based on the address that is why the name Random Access Memory but the data in the disc is stored sequentially. In the disc, the data is accessed using a file name and the data inside a file is kept in a sequence of bits. So, there is inherent mismatch in the format in which data is kept in memory and data is kept in the disc. You can watch this video to understand serialization further.

Almost every programming language allows us to define complex data types called classes. If you look closely at an object (which is an instance of a class), it is basically bunch of addresses to the data or the other addresses.
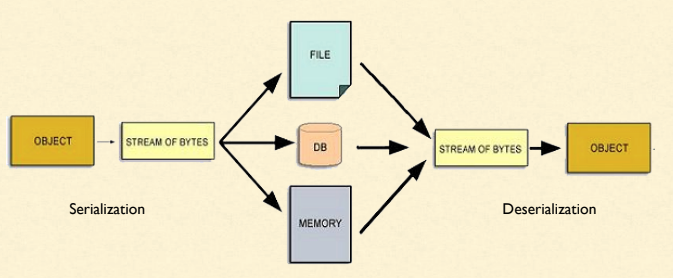
If we need to save an object to a disc or need to transfer it over the wire, we need to convert it into a sequence of bits. This process of converting an object to sequence of bits is called serialization. Since the addresses of memory of one computer will be different from another, therefore saving the addresses does not make sense. Therefore while serializing an object, we need to ensure that it serialized object does not have any memory address.

The serialization has two parts to it: the format of the data and the algorithm to serialize an object.
What is Avro?
There are many serialization formats such as XML, JSON, Thrift, Protocol Buffers, Avro etc.
Avro is a row-oriented remote procedure call and data serialization framework developed within Apache’s Hadoop project. It uses JSON for defining data types and protocols and serialized data in a compact binary. To know more about it check it out at wikipedia. As part of this discussion, we will learn how to handle Avro and other formats using Spark.
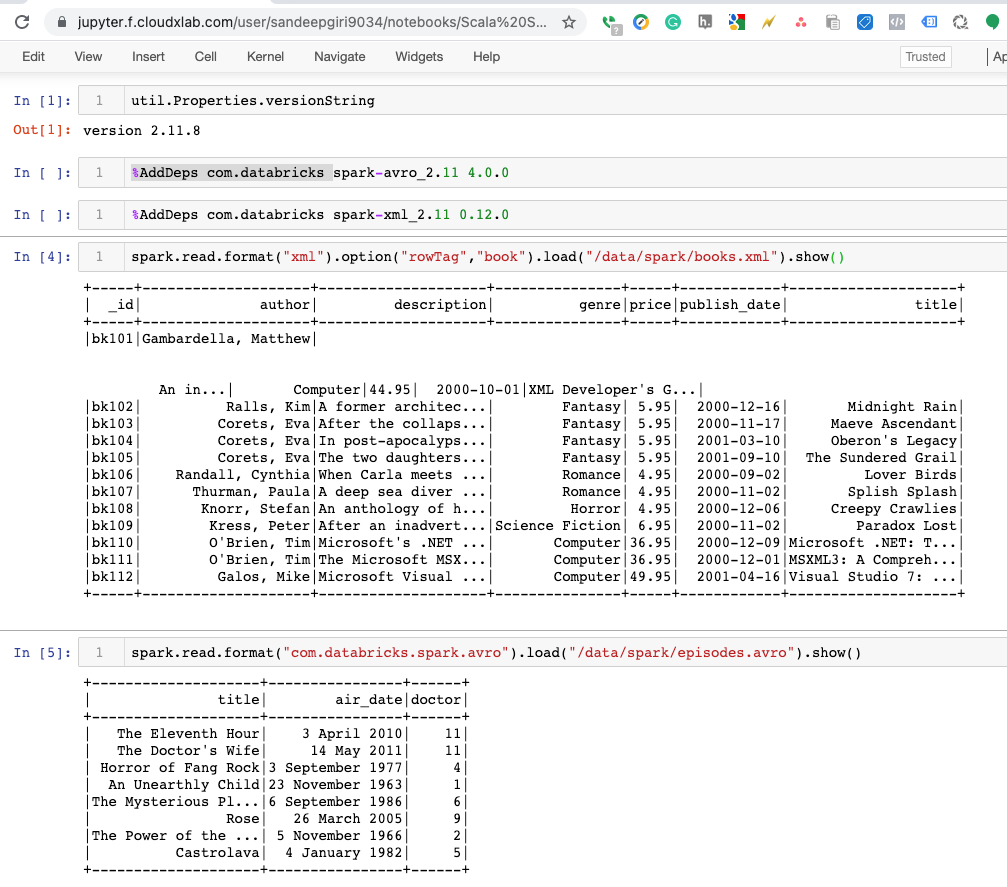
Now, find out the scala version you are using with scala -version
[sandeepgiri9034@cxln4 ~]$ scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
You can find the version of scala from the Apache Toree notebook too using util.Properties.versionString

You can see that we are using the scala version 2.11.8. Please make a note of it.
Finding the right libary?
As part of this tutorial, we are going to use third party libraries for handling specific format. The Apache Spark is written in scala which is basically a programming language which is Java underneath. In Java, the code is bundled into a jar file which is vaguely similar to zipping multiple files into one. In Apache Spark, the libraries are usually in .jar format. These libraries are hosted on Maven repository. Maven is a build tool as well as an artifact repository service.
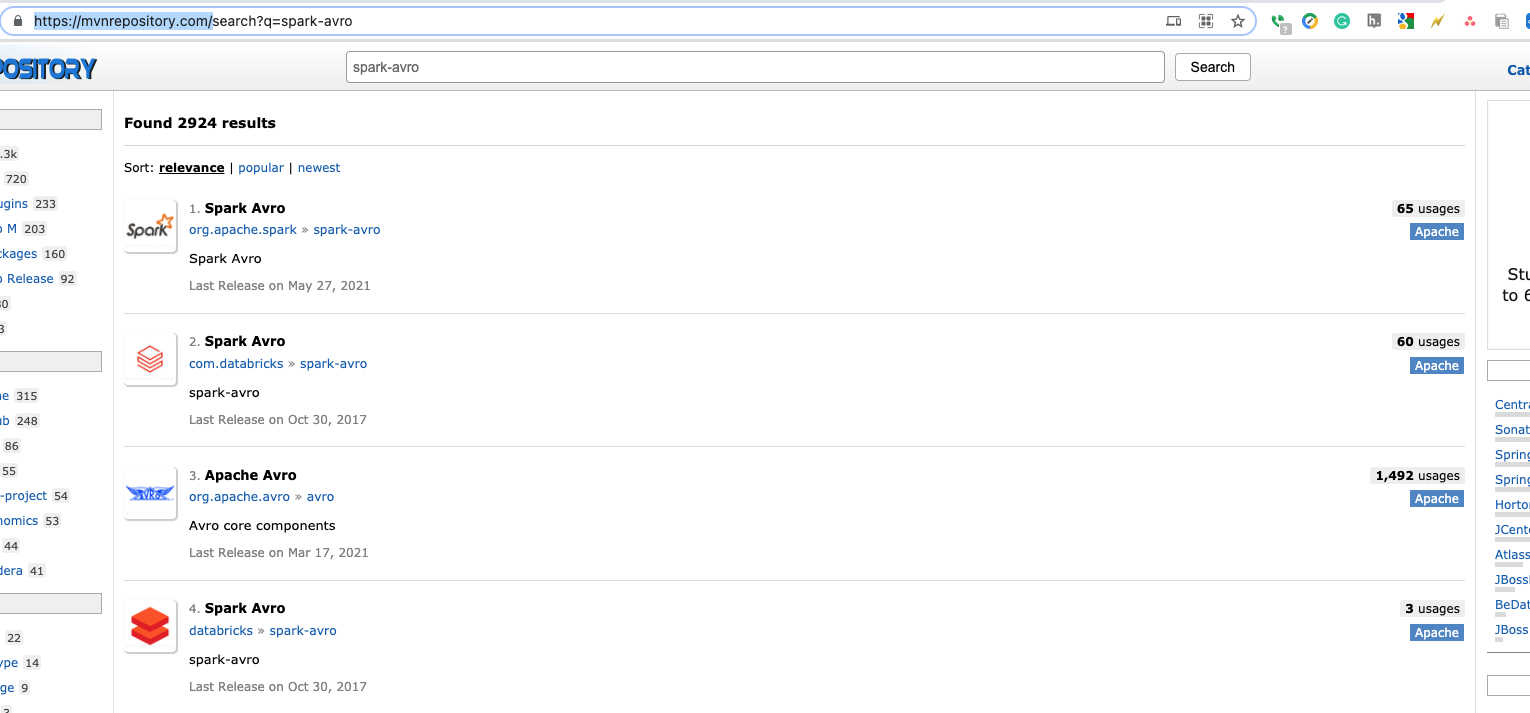
The main battle in handling most of these formats is to find the right binary jar. To find an exact library, we are going to search in maven repository at mvnrepository.com. When we search for “spark-avro”, we found top two libraries: one from “org.spark” and other from “databricks”.
Now, let’s select the second one. Click on “2. Spark Avro” in group “com.databricks“. This page would show all versions of this module. The first column lists the major versions and second lists version and the third one lists the scala version. Select the right scala version for your installation. In our case, we are using 2.11 scala so lets select the latest version of module for 2.11 scala version. Click on “2.11“. The latest version is 4.0.0.
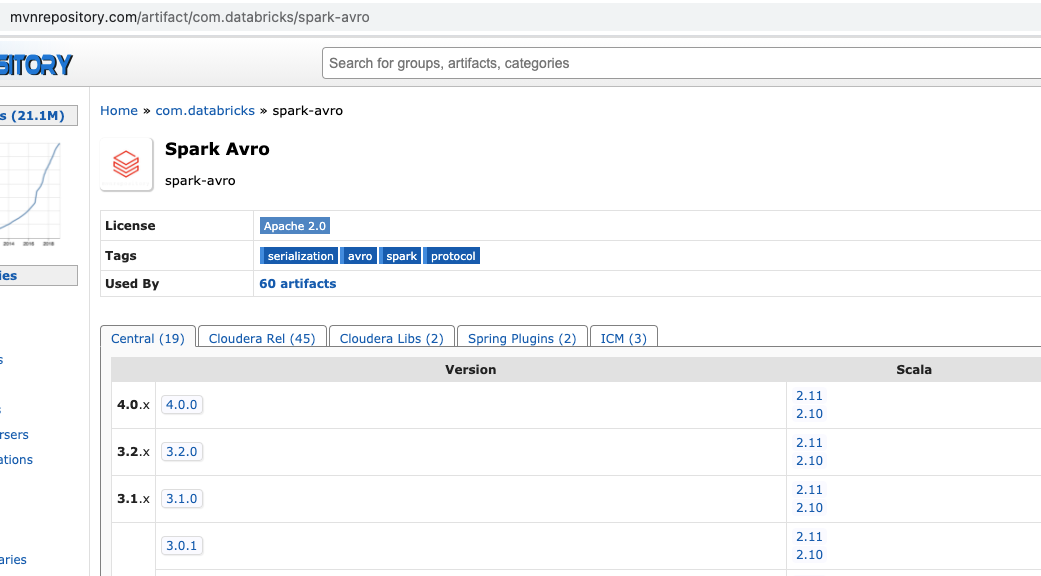
Now, it would show the details of the selected version.
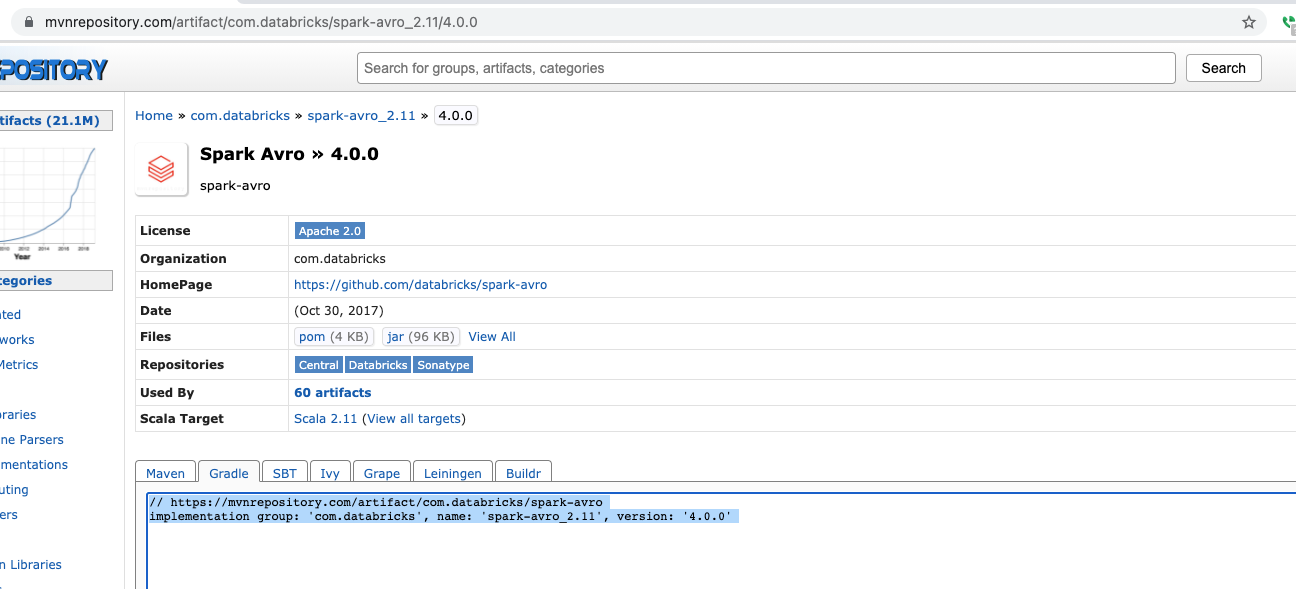
Make note of the group, name and version. In our case, group is ‘com.databricks’, artifact name is ‘spark-avro_2.11’ and version is ‘4.0.0’.
Similarly, when we search for spark-xml, we found group ‘com.databricks’, name ‘spark-xml_2.11’, version ‘0.12.0’.
If you are building an scala standalone application using sbt, please add the instruction from ‘sbt’ tab into `build.sbt` file.
If you are using the spark from spark-shell interactively. Then you can launch the spark-shell with ‘–package’ option. The full name of package is in the format <group>:<name>:<version>. Our command is:
spark-shell --packages com.databricks:spark-avro_2.11:4.0.0This would launch spark-shell and install the spark-avro package in this session. It might take a bit of time.
Similarly, for XML, you can launch with XML package:
spark-shell --packages com.databricks:spark-xml_2.11:0.12.0Also, you can launch with both packages like this:
spark-shell --packages com.databricks:spark-avro_2.11:4.0.0,com.databricks:spark-xml_2.11:0.12.0Once “scala>” prompt appears you can use the library installed. In our case, we can test if the Avro is being read or not.
spark.read.format("com.databricks.spark.avro").load("/data/spark/episodes.avro").show()
This would read the data from a file location in HDFS at /data/spark/episodes.avro. Please note that at CloudxLab we have already installed the Spark and also updated a file with Avro format at “/data/spark/episodes.avro“. It would display the contents after loading the dataframe.
scala> spark.read.format("com.databricks.spark.avro").load("/data/spark/episodes.avro").show()
21/06/15 20:44:51 WARN DataSource: Error while looking for metadata directory.
+--------------------+----------------+------+
| title| air_date|doctor|
+--------------------+----------------+------+
| The Eleventh Hour| 3 April 2010| 11|
| The Doctor's Wife| 14 May 2011| 11|
| Horror of Fang Rock|3 September 1977| 4|
| An Unearthly Child|23 November 1963| 1|
|The Mysterious Pl…|6 September 1986| 6|
| Rose| 26 March 2005| 9|
|The Power of the …| 5 November 1966| 2|
| Castrolava| 4 January 1982| 5|
+--------------------+----------------+------+Similarly, you can process an XML file once you have installed spark-xml library:
spark.read.format("xml").option("rowTag","book").load("/data/spark/books.xml").show()If you are using the Spark with Jupyter Notebook via Apache Toree kernel, you can add a jar using %AddDeps magic command. The format is:
`%AddDeps my.company artifact-id version`
In our case, it translates to:
%AddDeps com.databricks spark-avro_2.11 4.0.0Once, it is loaded you can access the AVRO files just like above using .
spark.read.format("com.databricks.spark.avro").load("/data/spark/episodes.avro").show()You can follow the same process while reading the XML file or installing any other library. The entire code would look like the following in the notebook.