Author: Atharv Katkar Linkedin
Directed by: Sandeep Giri
OVERVIEW:
In Natural Language Processing (NLP), embeddings transform human language into numerical vectors. These are usually arrays of multiple dimensions & have schematic meaning based on their previous training text corpus The quality of these embeddings directly affects the performance of search engines, recommendation systems, chatbots, and more.
But here’s the problem:
Not all embeddings are created equal.
So how do we measure their quality?
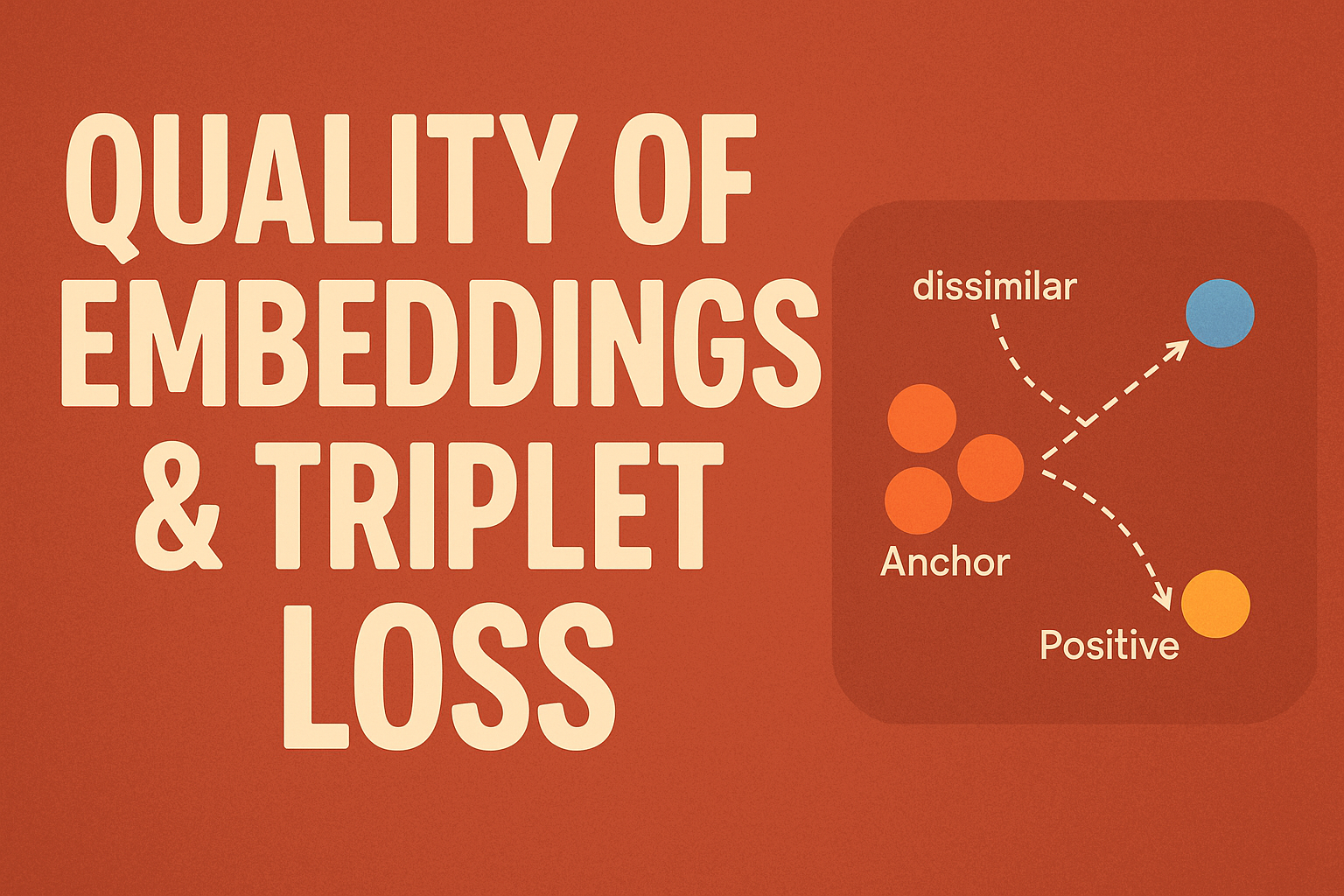
To Identify the quality of embeddings i conducted one experiment:
I took 3 leading (Free) Text → Embedding pretrained models which worked differently & provided a set of triplets and found the triplets loss to compare the contextual importance of each one.
Continue reading “Quality of Embeddings & Triplet Loss”