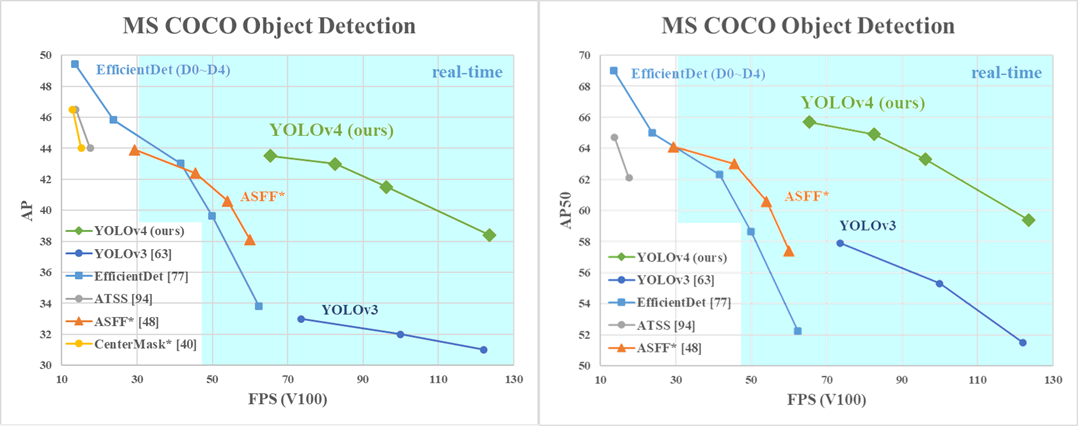
In this blog we will show how to process video with YOLOv4 and tensorflow. YOLOv4 is out and it’s hot. YOLOv4 is significantly better than YOLOv3 as can be seen in the pic below.
YOLO v4 Overview
YOLOv4 uses several of universal features like Weighted-Residual-Connections (WRC), Cross-Stage-Partial-connections (CSP), Cross mini-Batch Normalization (CmBN), Self-adversarial-training (SAT) and Mish-activation. They also use new features: WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, DropBlock regularization, and CIoU loss. A combination of known and new features has enabled them to achieve 43.5%
AP (65.7% AP50) for the MS COCO dataset at a realtime speed of ∼65 FPS on Tesla V100. It is faster and more accurate than YOLOv3 and faster than EfficientDet for similar accuracies.
The authors have tried to design a model that can be trained efficiently on a single GPU. It is optimised to work well in production systems. Users can train and implement YOLOv4 based programs on single GPU systems, keeping the cost low. For more details please see the YOLOv4 paper.
Video processing with YOLO v4 and TensorFlow
We will use this implementation of YOLO in python and Tensorflow in our work. The github project provides implementation in YOLOv3, YOLOv4. It also has methods to convert YOLO weights files to tflite (tensorflow lite models). Tensorflow lite models are smaller and can be implemented for speed at a cost of accuracy. We can also use Tensorflow lite models on edge devices like mobiles, etc.
We will first create a development environment using virtualenv.
mkvirtualenv tf-yoloClone the project.
git clone https://github.com/hunglc007/tensorflow-yolov4-tflite
cd tensorflow-yolo4-tfliteInstall the requirements file.
pip install -r requirements.txtI found an error in the repository, which was fixed by creating an empty __init__.py in the core directory.
touch core/__init__.pyI have made a new file for processing video using the existing code to process image.
import time
from absl import app, flags, logging
from absl.flags import FLAGS
import core
import core.utils as utils
from core.yolov4 import YOLOv4, YOLOv3, YOLOv3_tiny, decode
from PIL import Image
from core.config import cfg
import cv2
import numpy as np
import tensorflow as tf
import imutils
from imutils.video import FPS
from imutils.video import VideoStream
flags.DEFINE_string('framework', 'tf', '(tf, tflite')
flags.DEFINE_string('weights', '../darknet/yolov4.weights',
'path to weights file')
flags.DEFINE_integer('size', 608, 'resize images to')
flags.DEFINE_boolean('tiny', False, 'yolo or yolo-tiny')
flags.DEFINE_string('model', 'yolov4', 'yolov3 or yolov4')
flags.DEFINE_string('video', './data/road.mp4', 'path to input video')
flags.DEFINE_string('output', 'out.avi', 'path to output video')
def main(_argv):
#FPS calculator enables
if FLAGS.tiny:
STRIDES = np.array(cfg.YOLO.STRIDES_TINY)
ANCHORS = utils.get_anchors(cfg.YOLO.ANCHORS_TINY, FLAGS.tiny)
else:
STRIDES = np.array(cfg.YOLO.STRIDES)
if FLAGS.model == 'yolov4':
ANCHORS = utils.get_anchors(cfg.YOLO.ANCHORS, FLAGS.tiny)
else:
ANCHORS = utils.get_anchors(cfg.YOLO.ANCHORS_V3, FLAGS.tiny)
NUM_CLASS = len(utils.read_class_names(cfg.YOLO.CLASSES))
XYSCALE = cfg.YOLO.XYSCALE
input_size = FLAGS.size
video_path = FLAGS.video
output=FLAGS.output
fps = FPS().start()
#Declaration of output file to save the analysed video
cnt=0
vs = cv2.VideoCapture(video_path)
while True and cnt < 100:
try:
(grabbed, original_image) = vs.read()
original_image_size = original_image.shape[:2]
#print (original_image_size)
except:
break
cnt+=1
if cnt == 1:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
writer = cv2.VideoWriter(output, fourcc, 30, original_image_size[::-1], True)
original_image = cv2.cvtColor(original_image, cv2.COLOR_BGR2RGB)
original_image_size = original_image.shape[:2]
image_data = utils.image_preporcess(np.copy(original_image), [input_size, input_size])
image_data = image_data[np.newaxis, ...].astype(np.float32)
if FLAGS.framework == 'tf':
if cnt == 1:
input_layer = tf.keras.layers.Input([input_size, input_size, 3])
if FLAGS.tiny:
feature_maps = YOLOv3_tiny(input_layer, NUM_CLASS)
bbox_tensors = []
for i, fm in enumerate(feature_maps):
bbox_tensor = decode(fm, NUM_CLASS, i)
bbox_tensors.append(bbox_tensor)
model = tf.keras.Model(input_layer, bbox_tensors)
utils.load_weights_tiny(model, FLAGS.weights)
else:
if FLAGS.model == 'yolov3':
feature_maps = YOLOv3(input_layer, NUM_CLASS)
bbox_tensors = []
for i, fm in enumerate(feature_maps):
bbox_tensor = decode(fm, NUM_CLASS, i)
bbox_tensors.append(bbox_tensor)
model = tf.keras.Model(input_layer, bbox_tensors)
utils.load_weights_v3(model, FLAGS.weights)
elif FLAGS.model == 'yolov4':
feature_maps = YOLOv4(input_layer, NUM_CLASS)
bbox_tensors = []
for i, fm in enumerate(feature_maps):
bbox_tensor = decode(fm, NUM_CLASS, i)
bbox_tensors.append(bbox_tensor)
model = tf.keras.Model(input_layer, bbox_tensors)
utils.load_weights(model, FLAGS.weights)
model.summary()
pred_bbox = model.predict(image_data)
else:
if cnt==1:
# Load TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path=FLAGS.weights)
interpreter.allocate_tensors()
# Get input and output tensors.
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print(input_details)
print(output_details)
interpreter.set_tensor(input_details[0]['index'], image_data)
interpreter.invoke()
pred_bbox = [interpreter.get_tensor(output_details[i]['index']) for i in range(len(output_details))]
if FLAGS.model == 'yolov4':
pred_bbox = utils.postprocess_bbbox(pred_bbox, ANCHORS, STRIDES, XYSCALE)
else:
pred_bbox = utils.postprocess_bbbox(pred_bbox, ANCHORS, STRIDES)
bboxes = utils.postprocess_boxes(pred_bbox, original_image_size, input_size, 0.25)
bboxes = utils.nms(bboxes, 0.213, method='nms')
image = utils.draw_bbox(original_image, bboxes)
image = Image.fromarray(image)
#image.show()
image = cv2.cvtColor(np.array(image), cv2.COLOR_BGR2RGB)
cv2.imshow("output", cv2.resize(image, (800, 600)))
writer.write(image)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
fps.update()
fps.stop()
print("[INFO] elasped time: {:.2f}".format(fps.elapsed()))
print("[INFO] approx. FPS: {:.2f}".format(fps.fps()))
# do a bit of cleanup
cv2.destroyAllWindows()
# release the file pointers
print("[INFO] cleaning up...")
writer.release()
vs.release()
if __name__ == '__main__':
try:
app.run(main)
except SystemExit:
pass
Video processing with YOLOv4 and TensorFlow
python detect.py --weights ./data/yolov4.weights --framework tf --size 608 --video ./data/road.mp4