The bucketing in Hive is a data-organising technique. It is used to decompose data into more manageable parts, known as buckets, which in result, improves the performance of the queries. It is similar to partitioning, but with an added functionality of hashing technique.
Introduction
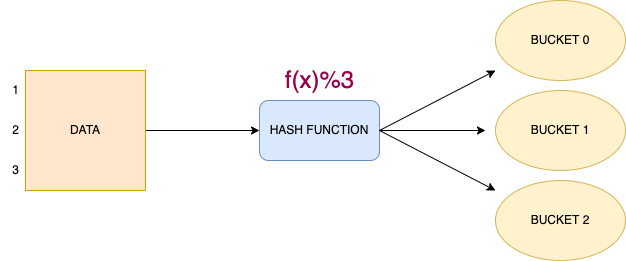
Bucketing, a.k.a clustering is a technique to decompose data into buckets. In bucketing, Hive splits the data into a fixed number of buckets, according to a hash function over some set of columns. Hive ensures that all rows that have the same hash will be stored in the same bucket. However, a single bucket may contain multiple such groups.
For example, bucketing the data in 3 buckets will look like-
How to perform bucketing?
Bucketing is performed by using CLUSTERED BY clause in Hive. You can use it like-
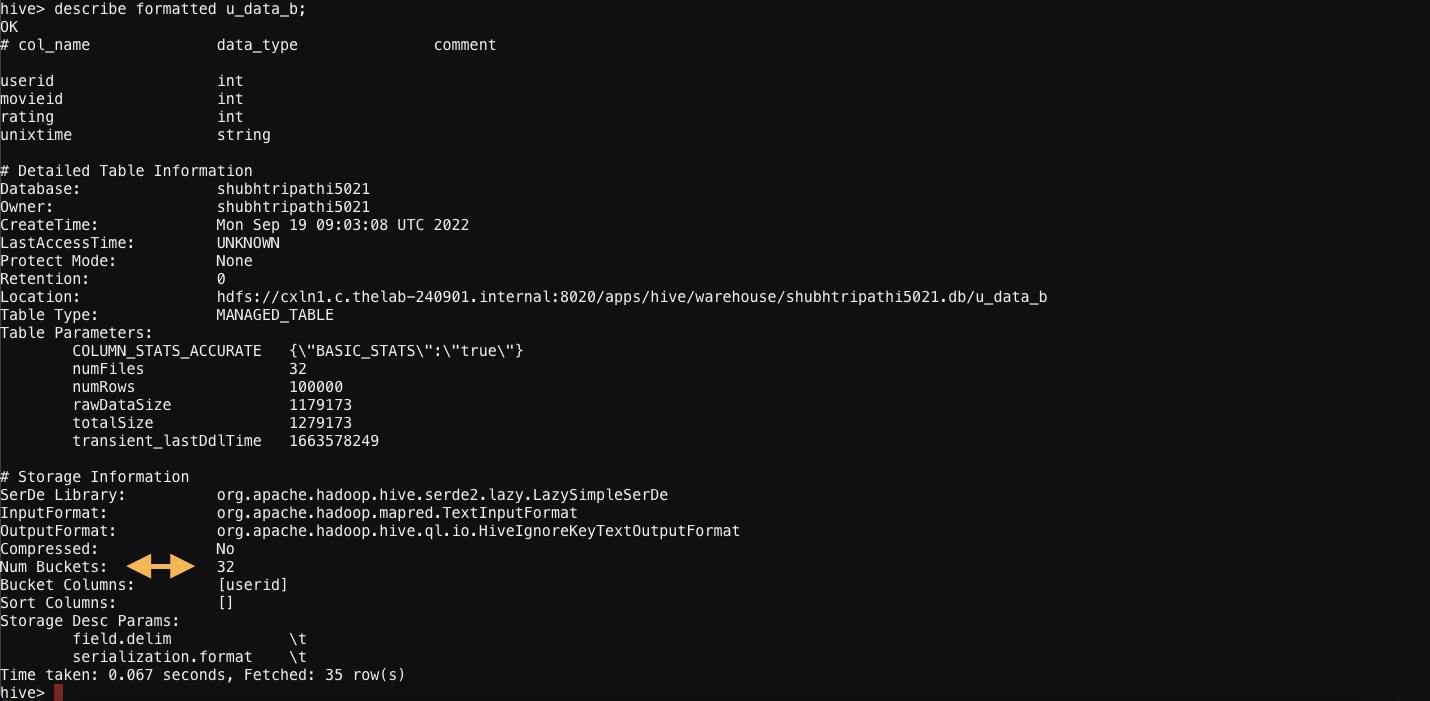
CREATE TABLE u_data_b( userid INT, movieid INT, rating INT, unixtime STRING)
CLUSTERED BY(userid) INTO 32 BUCKETS
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
INSERT OVERWRITE TABLE u_data_b
SELECT * from u_data;
So, the above code will create only 32 buckets irrespective of the fact that how many unique values are in the userid column.
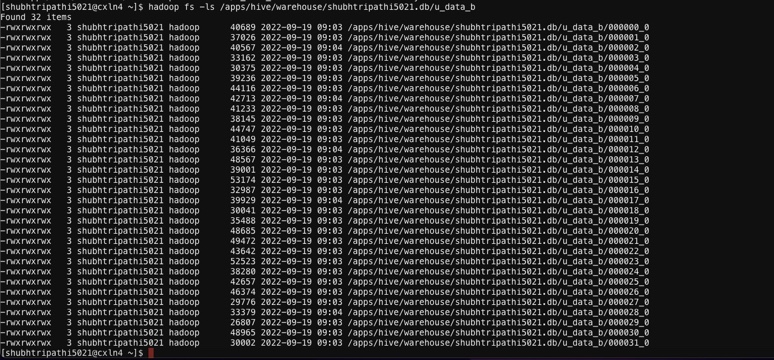
That further means, 32 sub-directories will be created which we can also see in the below figure:
Note that bucketing is preferred in case of a column having high cardinality because in such case, partitioning can create too many partitions. Furthermore, partitioning will result in multiple Hadoop files which will increase the load on the same node as it has to carry the metadata of each of the partitions.
CLUSTERED BY is often confused with the CLUSTER BY clause as they both sound the same. But, in reality, it is much different. Let’s understand the CLUSTER BY clause for more clarity.
CLUSTER BY
CLUSTER BY is a shortcut for both DISTRIBUTE BY and SORT BY. It first, distributes the input rows among reducers as per DISTRIBUTE BY clause and then ensures the sorting order of values present in multiple reducers, giving global ordering, as per the SORT BY clause.
CLUSTER BY is used mainly with the Transform/Map-Reduce Scripts. It is also sometimes useful in SELECT statements if there is a need to partition and sort the output of a query for subsequent queries.
It’s syntax is:
CLUSTER BY colName (',' colName)*
For example,
SELECT * FROM u_data WHERE userid < 5 AND movieid < 20 CLUSTER BY userid;
So, the above example will give the output as:
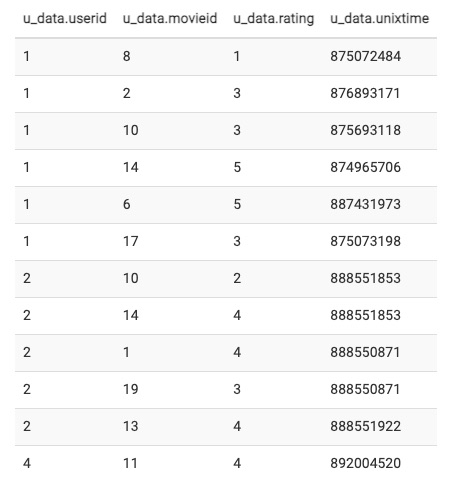
As we can see above, the output is sorted in ascending order of the column userid.
I hope it’s clear to all that in CLUSTER BY and CLUSTERED BY, the only thing common is that they sound the same.
Happy Learning!!