In the Hadoop ecosystem, YARN, short for Yet Another Resource negotiator, holds the responsibility of resource allocation and job scheduling/management. The Resource Manager(RM), one of the components of YARN, is primarily responsible for accomplishing these tasks of coordinating with the various nodes and interacting with the client.
To learn more about YARN, feel free to visit here.
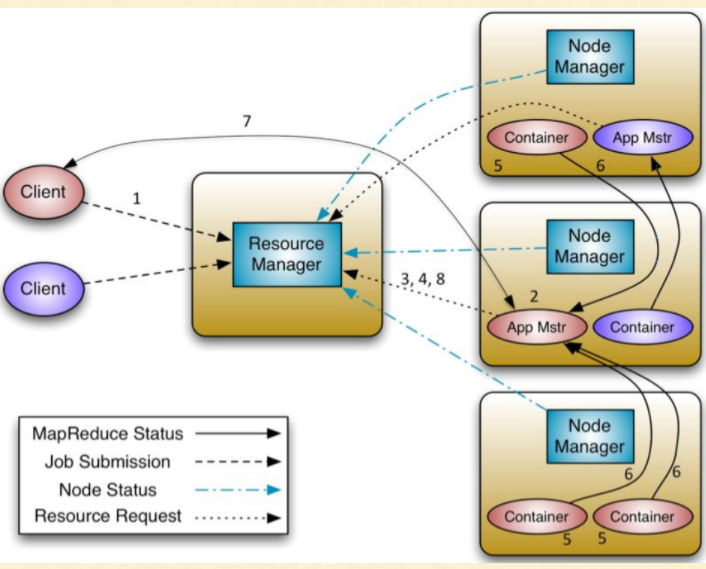
Hence, Resource Manager in YARN is a single point of failure – meaning, if the Resource Manager is down for some reason, the whole of the system gets disturbed due to interruption in the resource allocation or job management, and thus we cannot run any jobs on the cluster.
To avoid this issue, we need to enable the High Availability(HA) feature in YARN. When HA is enabled, we run another Resource Manager parallelly on another node, and this is known as Standby Resource Manager. The idea is that, when the Active Resource Manager is down, the Standby Resource Manager becomes active, and ensures smooth operations on the cluster. And the process continues.
But wait! How does this transition for the Standby RM happen to an active state?
Well, we have two options: manual failover and automatic failover.
Terminology Alert!
Failover: a process in which a system transfers the control to a secondary system, if detected any fault or failure.
Manual failover refers to a process in which the Hadoop administrator manually initiates a failover so that the standby RM becomes active. But this is very costly in this dynamic world, and thus it is not a recommended option.
Automatic failover is another option and is preferred over manual failover. In automatic failover, the system automatically transfers the control from the failed RM to the Standby RM in case of any failure. Also, we always need to ensure that there is no split-brain scenario.
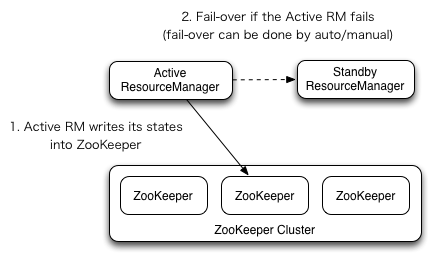
Terminology Alert!
Split-brain scenario: A situation where multiple RMs can potentially assume the Active role. This is undesirable because multiple RMs could proceed to manage some of the nodes of the cluster simultaneously, and this leads to inconsistency in resource management and job scheduling, thereby potentially leading to system failure as a whole.
So, at any given point in time, we want to make sure that there is one and only one RM active in the system; there should be no situation where the active RM and standby RM work parallelly. We can configure Zookeeper to coordinate this functioning.
Elaborately, Zookeeper helps in (1) electing the active RM, (2) handling the system to failover automatically – in case failure of active RM – so that the standby RM becomes active, and (3) coordinating such that there is no split brain scenario.
How could Zookeeper be used to elect the Active RM?
This scenario of selecting the RM is also referred to as Leader Election. Leader Election is one of the most common use cases of Zookeeper. A user or an application using the Zookeeper could create znode. A znode is an entity (or a construct similar to a directory in any file system) provided by Zookeeper in which we store configuration data of size less than 1MB. A znode can also contain children znodes, and this hierarchy is similar to that of Linux file systems.
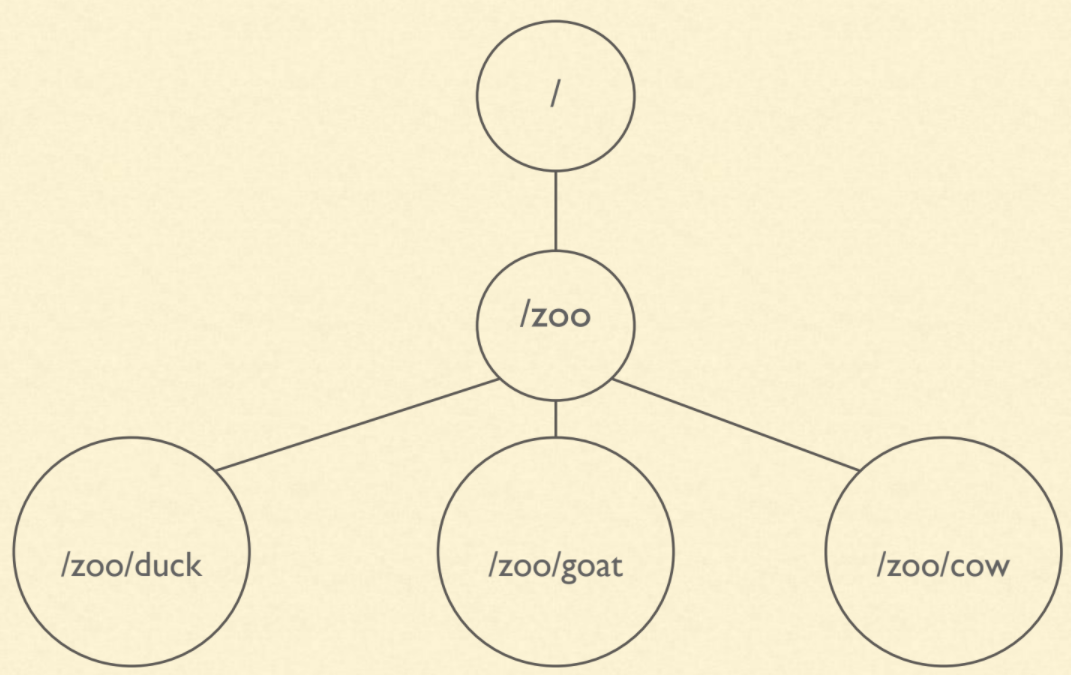
In the above diagram, “/” is the parent znode of “/zoo”. “duck” is a child znode of the znode “zoo”, and it is denoted as “/zoo/duck”. Similarly, “/zoo” is the parent znode of “/zoo/goat” and “/zoo/cow”.
Terminology Alert!
Ephemeral Znode: An ephemeral znode is a type of znode that gets deleted if the session in which the znode was created has disconnected. For example, if RM1 has created an ephemeral znode named eph_znode, this znode gets deleted if the session of RM1 gets disconnected with Zookeeper.
Now coming back, let’s say we have two RMs – RM1, RM2 – competing to become active. This election could be held by Zookeeper. The RM that first succeeds in creating an ephemeral znode named ActiveStandbyElectorLock will be made active RM. It is important to note that only one RM will be able to create the znode named ActiveStandbyElectorLock. Now say the RM1 has first created the znode ActiveStandbyElectorLock. RM2 will no longer be able to create the znode, since it is already created by RM1. So RM1 wins the election and is made active, whereas RM2 goes into standby mode.
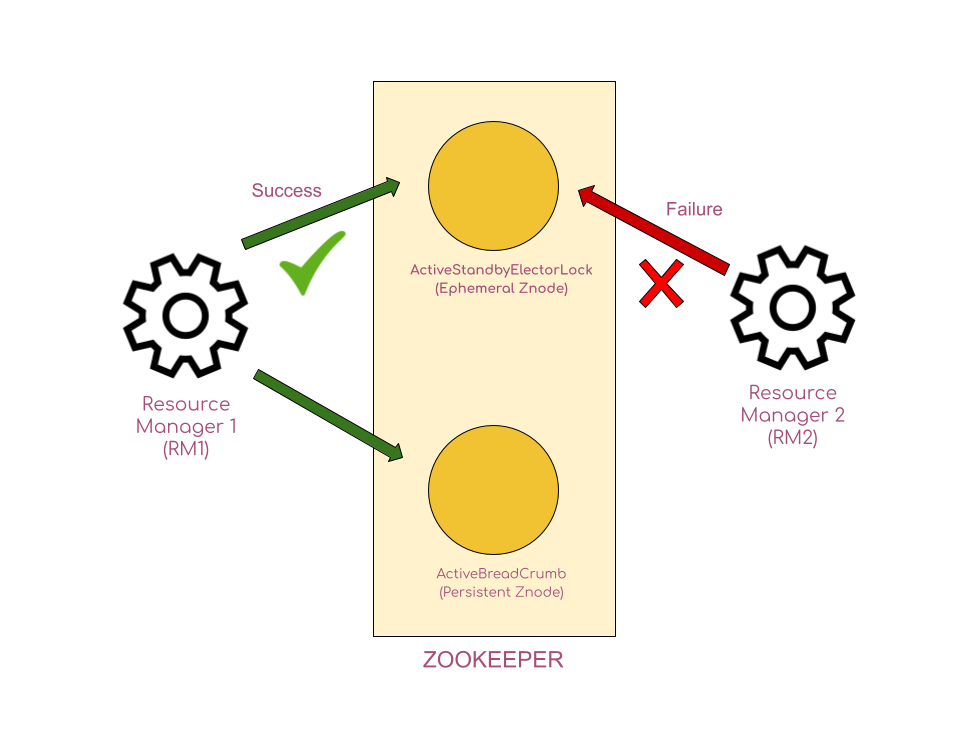
It is important to note that the ActiveStandbyElectorLock is an ephemeral znode. Now recollect our example where RM1 succeeds in creating the ephemeral znode named ActiveStandbyElectorLock. If RM1 goes down, the ActiveStandbyElectorLock znode(which was created by RM1) gets deleted automatically.
Persistent Znode:
Along with the ActiveStandbyElectorLock znode, RM1 will also create a persistent znode named ActiveBreadCrumb.
Terminology Alert!
Persistent Znode: A persistent znode exists with Zookeeper till deleted. Unlike the ephemeral znodes, a persistent znode is not affected by the existence/absence of the process that has created it. That is, if RM1 creates a persistent znode and even if RM1 session gets disconnected with Zookeeper, the persistent znode created by RM1 still persists and doesn’t get deleted upon RM1 going down. This znode gets removed only when it is deleted explicitly.
In this persistent znode ActiveBreadCrumb, the RM1 writes some config data about itself, such as the host name and port of RM1, so that at any given point of time, one could find out who the active RM is.
How does Zookeeper help YARN in handling automatic failover?
So far in the story, RM1 has become the active RM by winning over the RM2 in creating the ephemeral znode ActiveStandbyElectorLock. So far so good. Now what if one day the RM1 goes down, be it due to hardware failure or software issue? We now expect the standby RM to become active. Let’s see how this is done:
With Zookeeper, a process can watch any znode and get notifications whenever that znode gets updated or deleted. In our example, RM1 has created the ActiveStandbyElectorLock ephemeral znode. When RM2 tried to create the ephemeral znode, it was not able to do so, since it was already created by RM1. The RM2, before going to standby mode, places a watch on this ActiveStandbyElectorLock ephemeral znode created by RM1. This watch notifies RM2 everytime any update/delete occurs to the znode.
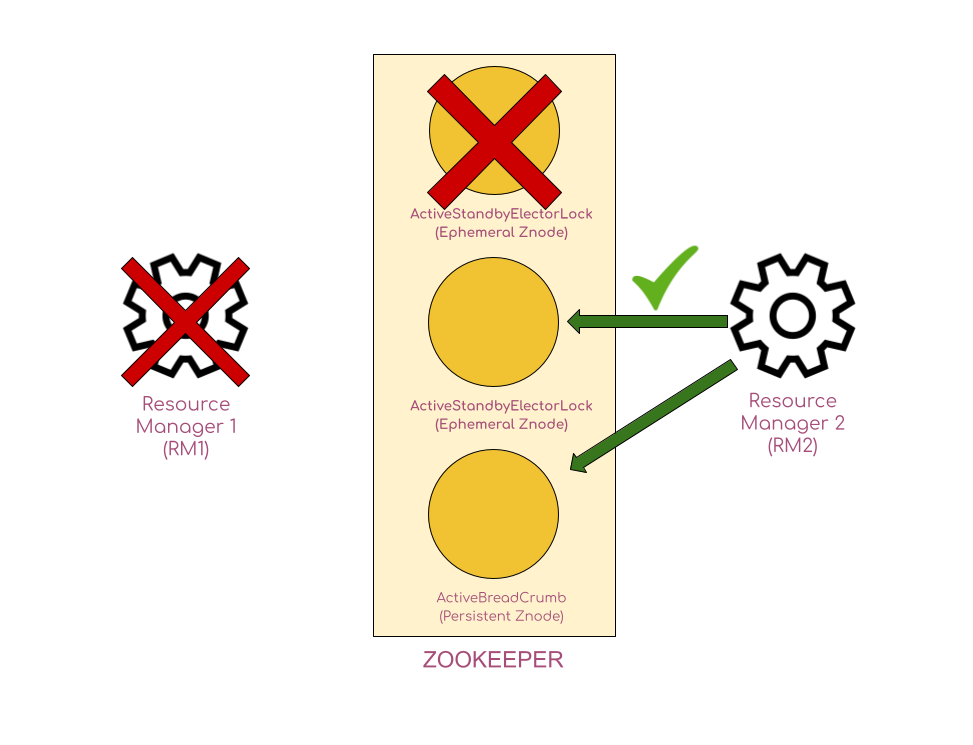
Let’s suppose that some unrecoverable issue – such as some hardware failure – has occurred, which led RM1 to go down. Then the following would happen sequentially:
- When RM1 goes down, its session ends with Zookeeper.
- As soon as RM1 gets disconnected with Zookeeper, the ActiveStandbyElectorLock znode gets deleted since it is an ephemeral znode created RM1 which is now out of contact with Zookeeper.
- Since RM2 is watching the ActiveStandbyElectorLock ephemeral znode, RM2 will be immediately notified when the znode gets deleted.
- RM2 now tries to create the ActiveStandbyElectorLock znode and it now succeeds as there is no other competitor to RM2 now. The standby RM now becomes the active one!
How does the Zookeeper help YARN ensure that there would be no split-brain?
Temporary connection issues are different from hardware failure. At the time of hardware failure in RM, there is a definite necessity for another RM in another node. But sometimes, RMs get temporarily disconnected, and will try to connect back to Zookeeper. But Zookeeper will not be able to differentiate the cause of RM disconnection, and hence it deletes the ephemeral znodes created by the RM.
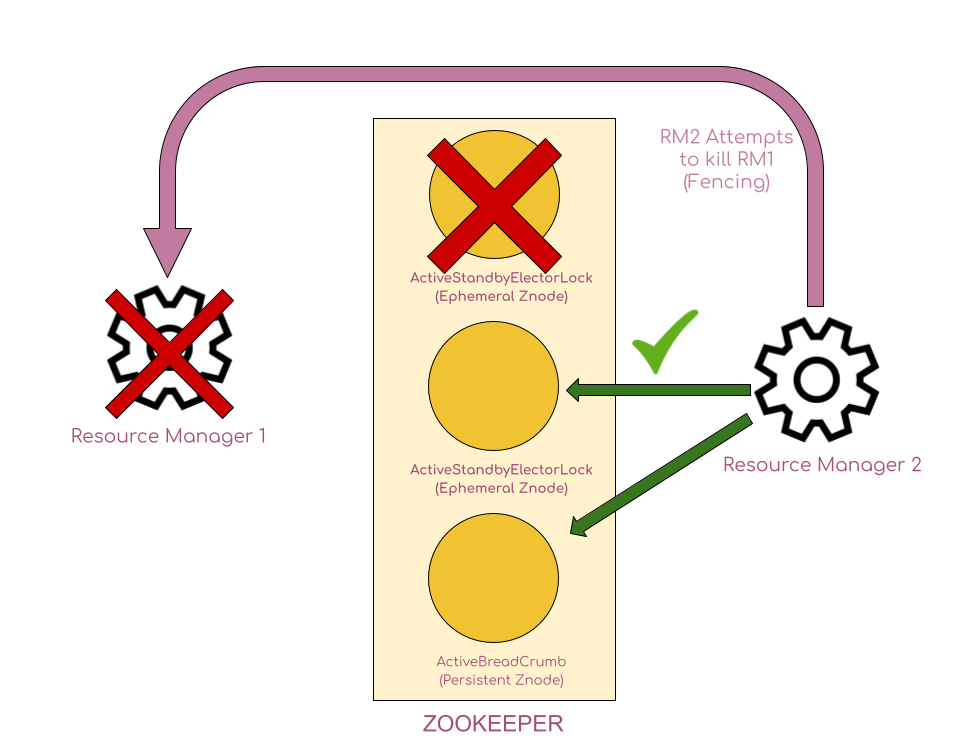
In our example, if RM – which is the active RM – gets temporarily disconnected, then the ActiveStandbyElectorLock znode gets disconnected. This triggers the standby RM to create the ActiveStandbyElectorLock znode. But RM1 thinks that it is still active. We need to efficiently handle this situation since we don’t want a split-brain scenario to occur, where both the RMS act as active RMs.
To avoid the split-brain scenario, RM2 works proactively. Before assuming the status of active RM, the RM2 reads the information about the active RM from the ActiveBreadCrumb (recollect that RM1 has written its information – such as hostname and port – as the data in the ActiveBreadCrumb persistent znode) and realises that RM1 was active. RM2 then attempts to kill the process of RM1. This phenomenon is technically known as fencing. After that, RM2 overwrites the data(in the ActiveBreadCrumb persistent znode) to its own configuration such as the hostname and port of RM2, since RM2 is now the active RM.
Similarly, in order to provide the high availability HBase, HDFS, Kafka and many other distributed systems use Zookeeper. In HBase, the selection of master happens using zookeeper. In zookeeper at CloudxLab, you can find the ephemeral znode “/hbase-unsecure/master” created by the master using the following commands:
[zk: localhost:2181(CONNECTED) 11] get /hbase-unsecure/master
master:16000N
cxln2.c.thelab-240901.internal
cZxid = 0xfd0003cd5f
ctime = Sat Jun 19 09:57:50 UTC 2021
mZxid = 0xfd0003cd5f
mtime = Sat Jun 19 09:57:50 UTC 2021
pZxid = 0xfd0003cd5f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x57a1011b5470037
dataLength = 78
numChildren = 0