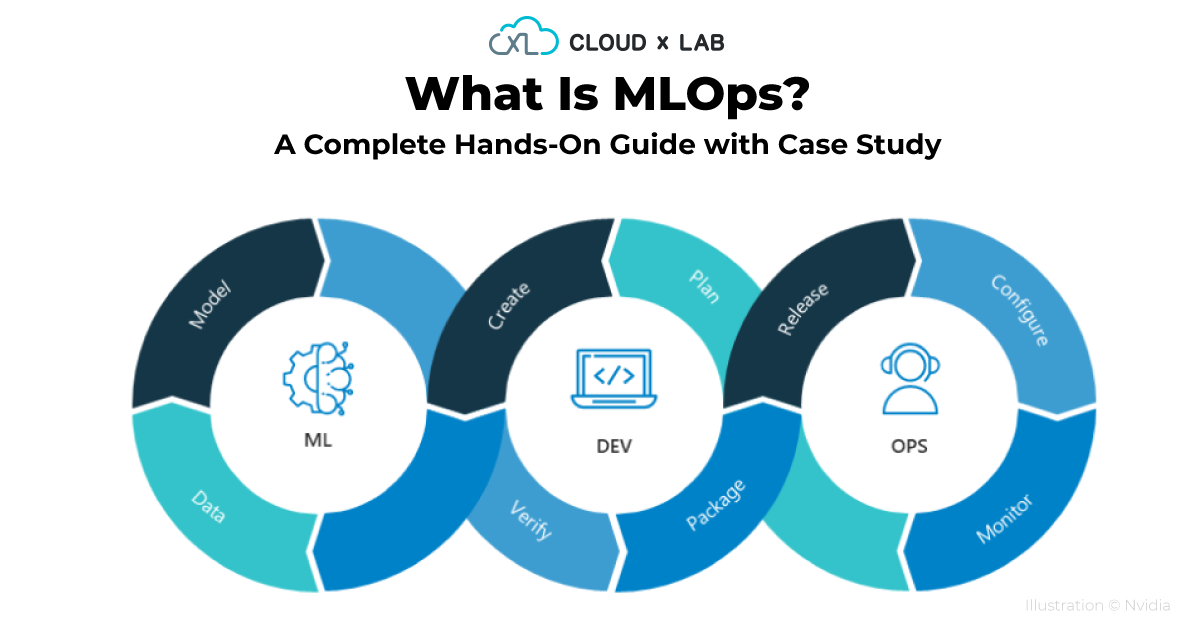
You will learn about MLOps with a case study and guided projects. This will also cover DevOps, Software Engineering, System Engineering in the right proportions to ensure your understanding is complete.
Introduction
As part of this series of blogs, I want to help you understand MLOps. MLOps stands for Machine Learning Ops. It is basically a combination of Machine Learning, Software Development, and Operations. It is a vast topic. I want to first establish the value of MLOps and then discuss the various concepts to learn by way of guided projects in a very hands-on manner. If you are looking for a theoretical foundation on MLOps, please follow this documentation by Google.
Case Study
Objective
When I was working with an organization, we wanted to build and show the recommendation. The main idea was that we need to show something interesting to the users in a small ad space that people would want to use. Since we had the anonymized historical behavior of the users, we settled down to show recommendations of apps that they would also like based on their usage of various apps at the time when the ads were being displayed.
Initial Plan – Team
Earlier, we believed that team composition and roles/responsibilities were very important. So, we defined the team structure based on our understanding of the problem. Initially, our team structure was as follows.
A Data Scientist
A Data Scientist
Whose role was to look at the data and apply various techniques to come up with a model to product recommendations.

A Front End Engineer
Front end engineer was responsible for building the UI for displaying the recommendations to the end user given a Javascript object. The rendering had to be very intuitive and responsive. We also needed to keep a track of user’s response in analytics.

A DevOps Engineer
A DevOps Engineer
Who is responsible for taking the system to production, scale it and monitor it.

Full Stack Engineers / Data Engineers
The engineers were responsible for tying things together. We had two Full Stack Engineers who doubled as Data Engineers. And I was playing the role of Full Stack Engineer and Data Engineer as well as a tech lead.
Test Engineers
We had two test engineers. Their role was to test our recommendations. And then there was a Product Manager, Program Manager and an Engineering manager.
Initial Plan – Architecture
In the beginning life looked pretty simple. The flow I had in mind was like this.
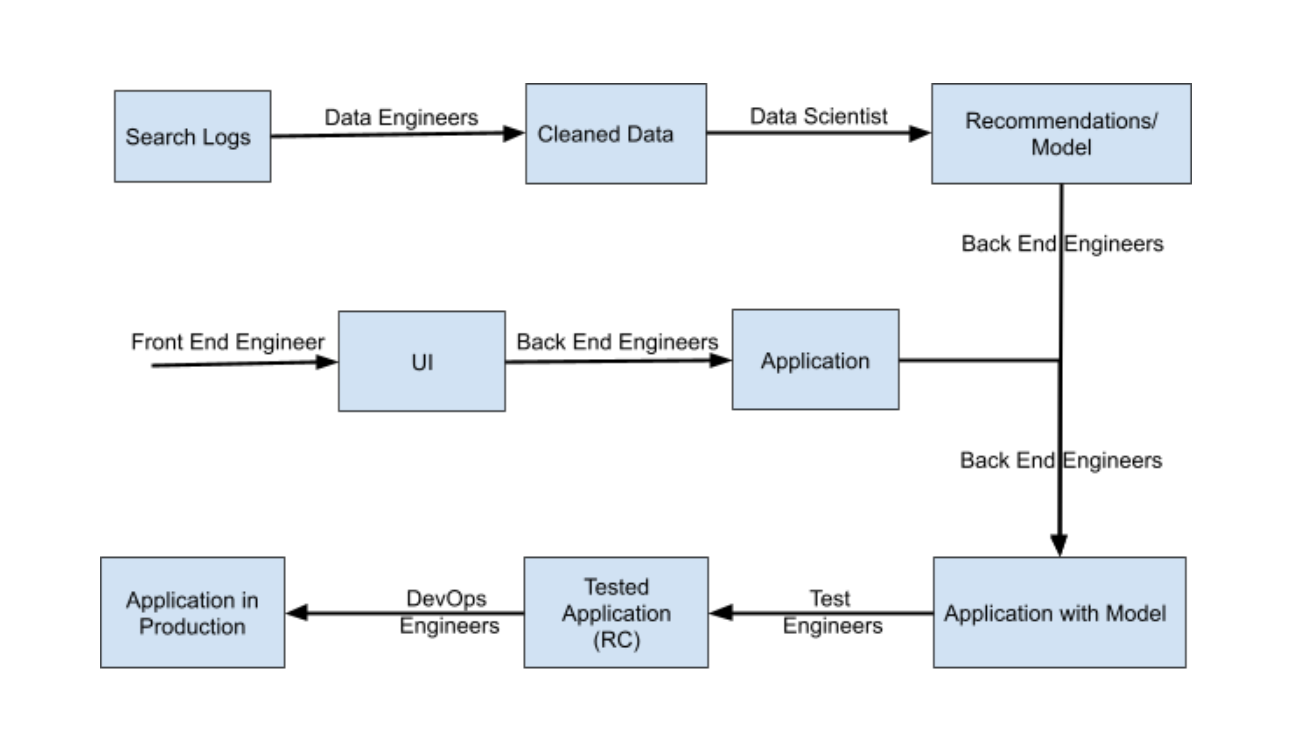
The search logs were humongous, approximately 200 TB. The objective was to provide great recommendations to the user so that the engagement would be better.
Data Engineers would pick the search logs and clean it using Hadoop Cluster and prepare the list of users and the product visited. The Data Scientist would build some python scripts that would run on top of hadoop to build a bunch of models which would be served by the services written by back end engineers after using the frontend by frontend engineers.
The entire pipeline was supposed to have continuous integration, testing and deployment.
The initial focus was to just get a basic recommendation engine out. It should be good enough to be used in production. Our aim was that the first version should not take more than 30 working days.
Learnings Stage
This plan looked perfect in my head but soon enough it started to fall apart. There were all kinds of deviations which we were anticipating anyway.
- Here are those learnings:
- Data Engineers did not know which data to get and what to clean. They needed to be briefed again and again by Data Scientists. The data engineers got a good clarity on how a machine learning model is trained.
- Data Scientists did not know whether he should create the model that would give recommendations on user and query parameters. We decided to break this into two phases. In the first phase, we would only do the recommendations without any user or query parameters. Data Scientists also faced a cold start problem – if we don’t have the information about a user we can not give them any recommendation. In such cases, of new users, we decided that we will show them top products in their country.
- Backend engineers had a big mental block on what kinds of magic is a recommendation. Does it change per user? Is it static? After discussing with Data Scientists, we decided that the first version will have two kinds of recommendations. For the users whose behaviour we know, we will prepare the static list of recommendations using the collaborative filtering methods. For the users who are coming for the first time (meaning we don’t have any characteristic of these users), we would just show the top suggestion for their region.
- Test Engineers didn’t know how to test such an application? How would we say, is it a good recommendation or bad? So, we decided to move one engineer to test just the model and taught her how to test a model. One engineer was testing the application independently.
- We had to teach everyone what Machine Learning is and a typical machine learning project workflow.
After much back and forth and lots of ambiguity resolution, in a couple of months, we were able to create a release candidate. But soon enough, we were hit by a major blockade, the model was too big to be deployed in production. Our model was taking 4GB of RAM but we were only allowed 200 MB of memory in production. At this point, deploying to production looked imposible. The DevOps team had no clue about what’s there in the application and believed that it is the back end engineering team’s role. The back end engineering team had no clue about the secret sauce inside the model so they had also turned a blind eye. The data scientists were of the opinion that it is something to do with the engineering or deployment team because the model is giving perfect results in staging and development environments.
This was a no-go situation. At this point of time, I along with other engineers started studying the machine learning model code. Also, we started studying the various machine learning models used in our projects. Afterwards, we figured out the bottleneck and were able to successfully deploy the machine learning.
Conclusion
The simple conclusion was everyone in the team must know machine learning basics and the process. Now, we call it MLOps. Rest of the blog is focussed on learning MLOps.
MLOps Learning Path
A. Foundations
1. Linux/Unix or Command Line

When you are planning a career in a stream such as ML Engineer, you must make yourself comfortable with the basics of Linux or Unix or the command line (You will find the terminal in the Mac OS too). This helps you automate the various tasks as well as understand the various ideas of networking etc.
At CloudxLab, you can learn this for free in a hands-on way here.
2. Python (Or a programming language)

There are many tools such as AzureML, that let you do machine learning without using any coding but honestly, if you are planning a career as an engineer, it would be better to learn to program. It not only helps in machine learning, but it helps you in various automation.
Also, once you know how to program, you will be able to think better. You can learn Python for free here at CloudxLab in a very hands-on manner. Also, finish at least one project such as Churn Emails Inbox with Python.
B. Getting Started into Machine Learning
This is your first step into machine learning. The objective should be to get started in machine learning instead of learning nuances of the underlying algorithms. This would solve the problems using machine learning.
1. Basic concepts of ML
You should learn about the different kinds of machine learning problems such as supervised, unsupervised, reinforcement learning. Also, you should learn the difference between the rule-based approach and the machine learning-based approach. This is discussed in Introduction to ML.
If we have to prepare a model using a dataset having labels along with images and this model has to predict the label given an image, it is called Supervised machine learning. If we are only given a set of images (and not the labels) and we have to group the images based on some similarity criteria, it is called Unsupervised learning.
If we have to build a model which acts in an environment to accomplish a goal it is called Reinforcement Learning. So, a robot roaming around in an environment to accomplish something is an example of reinforcement learning.
2. Build End-to-End machine learning projects
This is the most critical part of machine learning. Learning to build an end-to-end project first, specifically via a guided project. This would make you very confident. Usually, people do the project last in courses, but I recommend doing it the first as it covers the End-to-End Project.
Once you build a machine learning model, you will understand Analytics and the machine learning process. You would also learn the underfitting and overfitting by now. At this point, you may not understand the exact workings of various models, which you will learn in the following chapters.
Just after this, you should try more regression projects such as Forecast Bike Rentals.
C. Evolution of an AI Application
Once you have gone through the basics of computing and machine learning as outlined above. The next step is to understand how an AI Application evolves. Here are the set of projects that would help you understand the entire flow.
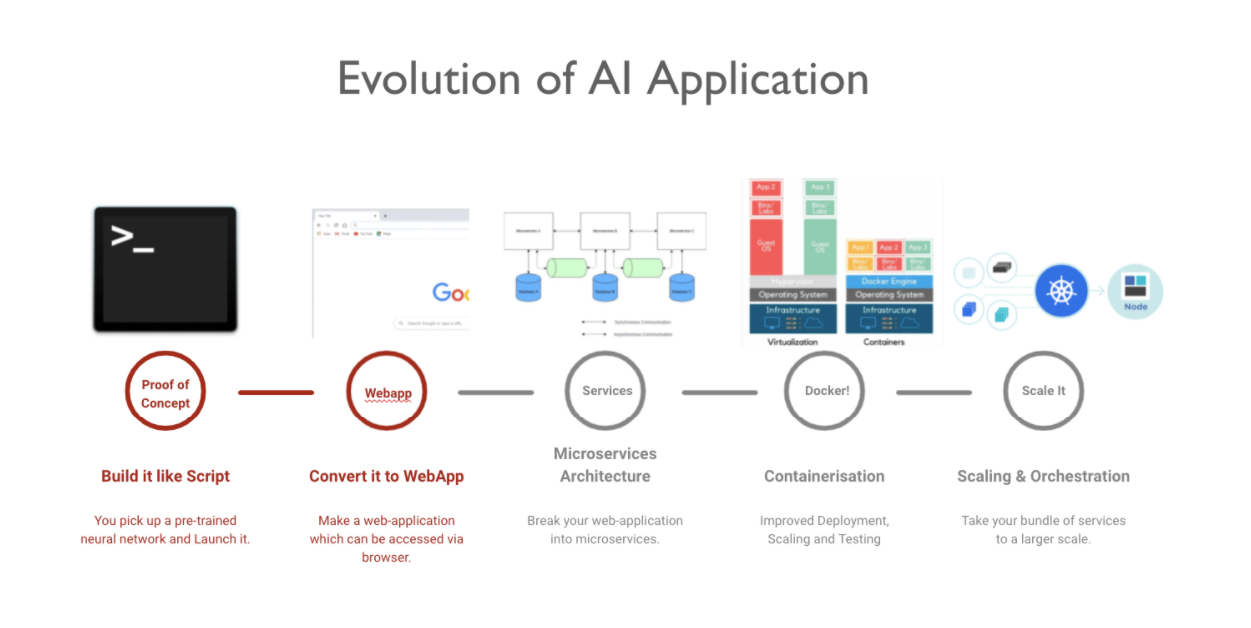
Step 1 : Build it like Script

This is a great way to start using a pre-trained model. This is useful for building Proofs-of-Concept. Once you go through the machine learning process, you would understand what a pre-trained model is. You have many pre-trained models, such as Model Zoo, to download the various models and use them.
Here is a project that can help you understand how to use a pre-trained model: Project – Image Classification with Pre-trained InceptionV3 Network
Step 2 : Convert it to WebApp

The previous step is not very useful. A more practical application is a web application. You would be able to access the application via any browser.
Make sure to follow this project: Project – How to Deploy an Image Classification Model using Flask.
Web applications are complex, and it is mandatory to know how to build an essential website because that helps us understand various moving parts.
Step 3 : Microservices Architecture
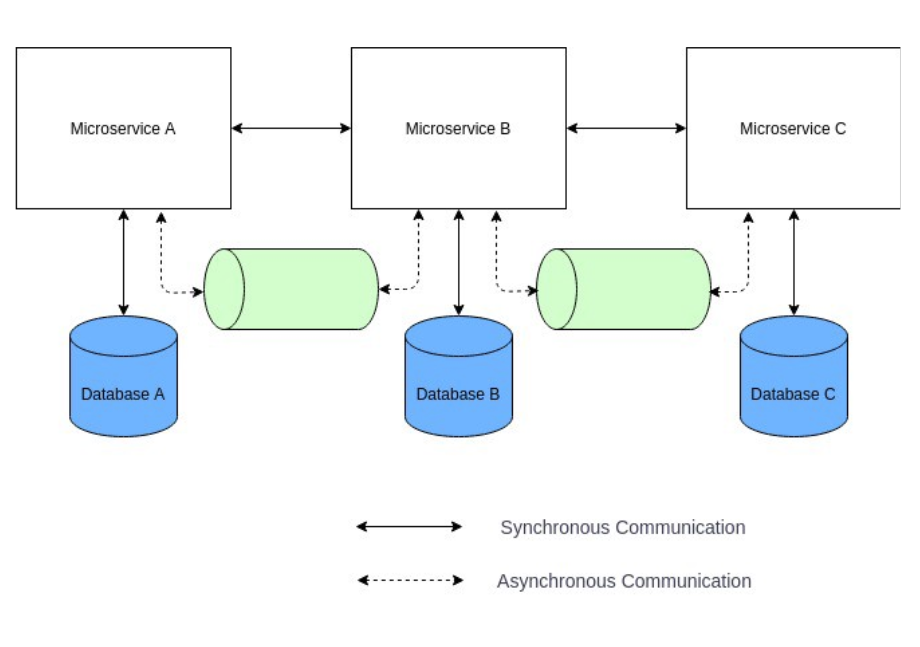
The next step to building a web application is to break down a monolithic application into small services. This improves the performance and scalability of your application.
Here is a guided project to achieve the same: How to build low-latency deep-learning-based flask app
Step 4 : Containerization
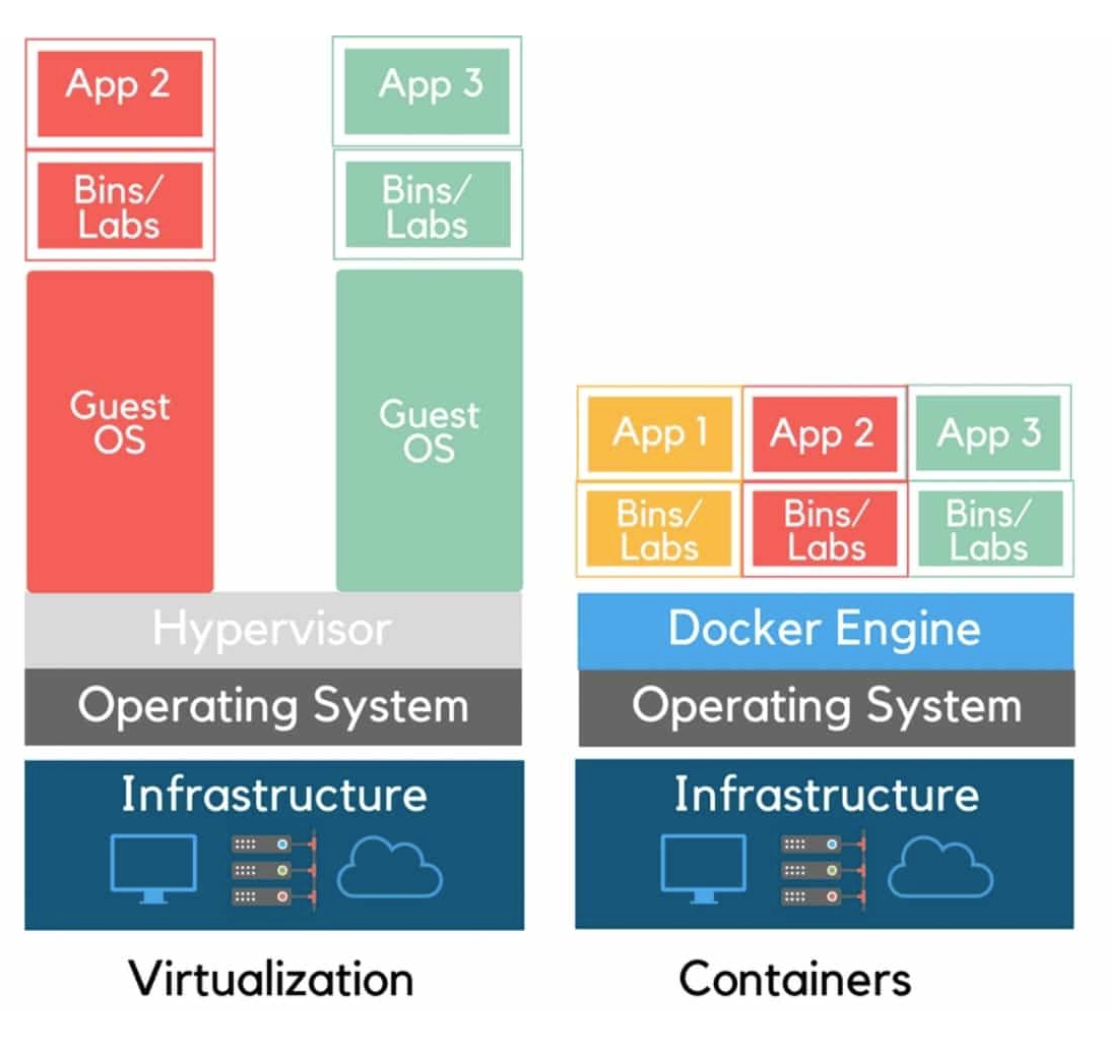
Containerisation is the excellent magic of the last five years. Earlier, there were just too many issues in installations due to the conflicts between libraries and processes. Containerisation solved it by providing each application with complete isolation.
Here is a guided project that would you build your containers for the microservices discussed in the previous step: How to Dockerize an Image Classification App
Step 5 : Scaling & Orchestration
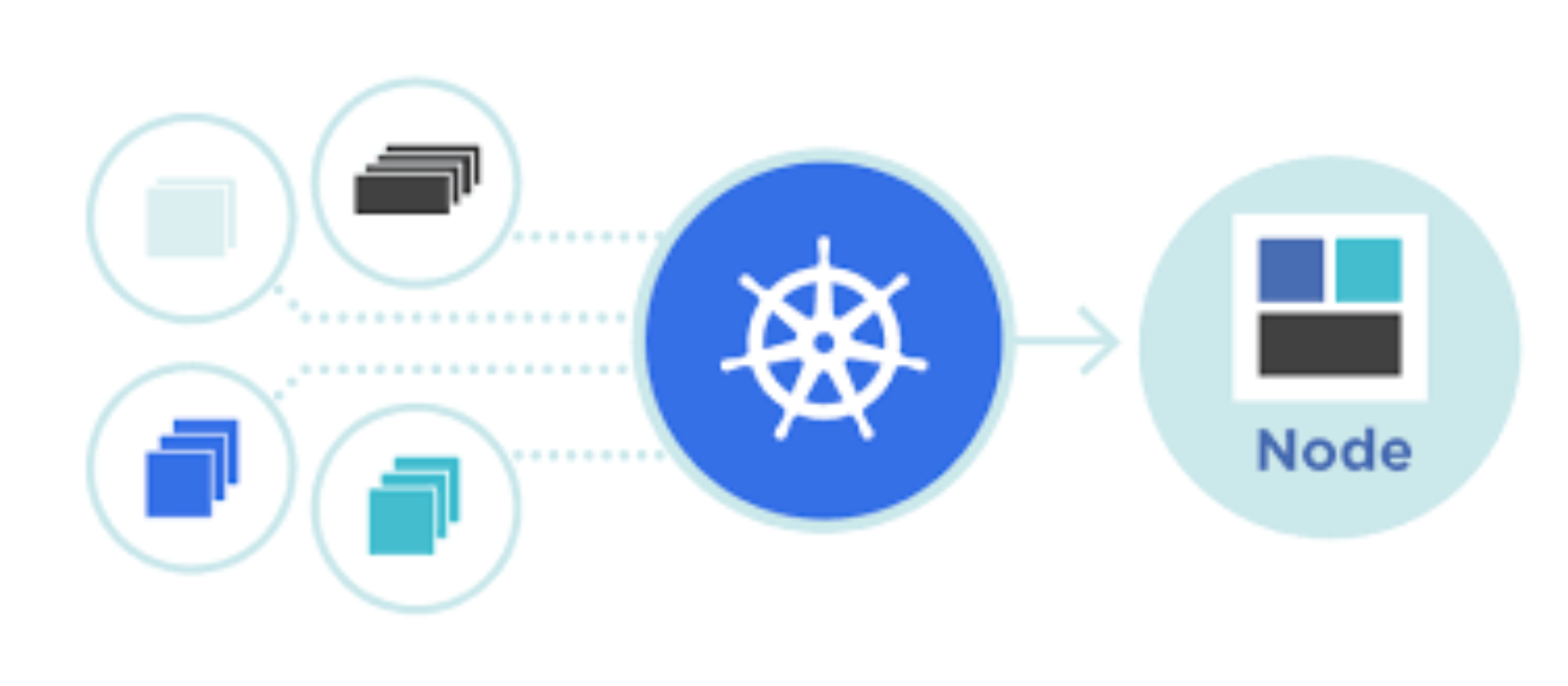
Once you have learned the application’s containerization, the next important aspect of learning is how to deploy the containers onto a cloud and scale and orchestrate the various services of the application. Here are the beneficial projects that would help you understand the Scaling and Orchestration: Deploying Multi Container Flask App with Docker & Travis CI on AWS Elastic Beanstalk and Deploying Single Container Static App on Google Kubernetes Engine
Once you follow these projects, you will be ready to lead the MLOps teams. Also, do apply to the jobs here
Checkout the MLOps Certificate Course Offered by CloudxLab here.