
Unless you’ve been living under the rock, you must have heard or read the term – Big Data. But many people don’t know what Big Data actually means. Even if they do then the definition of the same is not clear to them. If you’re one of them then don’t be disheartened. By the time you complete reading this very article, you will have a clear idea about Big Data and its terminology.
What is Big Data?
In very simple words, Big Data is data of very big size which can not be processed with usual tools like file systems & relational databases. And to process such data we need to have distributed architecture. In other words, we need multiple systems to process the data to achieve a common goal.
Generally, we classify the problems related to the handling of Big Data into three buckets:

1. Volume
When the problem we are solving is related to how we would store such huge data, we call it Volume. For example, Facebook stores 600 TB of Data in just one day!
2. Velocity
When we are trying to handle many requests per second, we call this characteristic Velocity. For example, the number of requests received by Facebook or Google per second.
3. Veracity
If the problem at hand is complex or data that we are processing is complex, we call such problems as related to variety. For example, problems involving complex data structures like Maps & Social Graphs.
Data could be termed as Big Data if either Volume, Velocity or Variety becomes impossible to handle using traditional tools.
Why do we need Big Data now?
You will see the answer to this question when we look at the huge transition from Analog storage to Digital storage.
For your information, Paper, Tapes etc are examples of analog storage while CDs, DVDs, hard disk drives are considered digital storage.
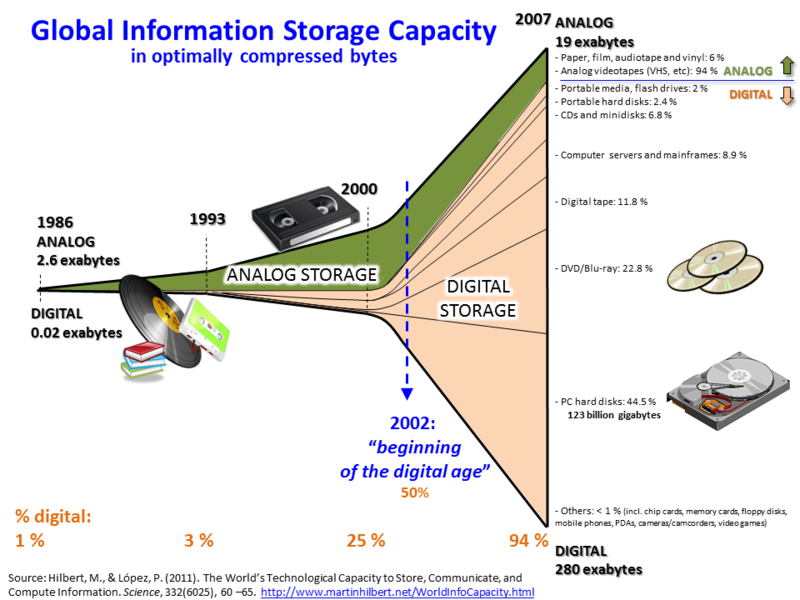
This graph shows that the digital storage has started increasing exponentially after 2002 while analog storage remained practically same.
The year 2002 is called beginning of the digital age. Why so? The answer is twofold: Devices & Connectivity. Devices became cheaper, faster and smaller and on the other hand, the connectivity improved.
This lead to a lot of very useful applications such as a very vibrant world wide web, social networks, and Internet of things leading to huge data generation.
With the huge data generation, it became practically impossible to store & process such humongous data. Let’s go through some basics to better understand the need for multiple systems to process big data.
Roughly, the computer is made of 4 components.
1. CPU – Which executes instructions. CPU is characterized by its speed. More the number of instructions it can execute per second, faster it is considered.
2. RAM – Random access memory. While processing, we load data into RAM. If we can load more data into ram, CPU can perform better. So, RAM has two main attributes which matter: Size and its speed of reading and writing.
3. Storage Disk – To permanently store data, we need hard disk drive or solid-state drive. The SSD is faster but smaller and costlier. The faster and bigger the disk, faster we can process data.
4. Network – Another component that we frequently forget while thinking about the speed of computation is the network. Why? Often our data is stored on different machines and we need to read it over a network to process.
While processing Big Data at least one of these four components become the bottleneck. In fact, all of the following components can impact the speed of computing – CPU, Memory Size, Memory Read Speed, Disk Speed, Disk Size, and Network Speed.
Which is why we need to move to multiple computers or distributed computing architecture.
Big Data Applications
So far we have tried to establish that while handling humongous data we would need a new set of tools which can operate in a distributed fashion.
But who would be generating such data or who would need to process such humongous data? A quick answer is everyone.
Now, let us try to take few examples.
1. E-Commerce Recommendation
In e-commerce industry, the recommendation is a great example of Big Data processing. The recommendation, also known as collaborative filtering is the process of suggesting someone a product based on their preferences or behavior.
The e-commerce website would gather a lot of data about the customer’s behavior. In a very simplistic algorithm, we would basically try to find similar users and then cross-suggest them the products. So, more the users, better the results.
As per Amazon, a major chunk of their sales happens via recommendations on the website and emails.
As of today, generating recommendations have become pretty simple. The engines such as MLLib or Mahout have made it very simple to generate recommendations on humongous data. All you have to do is format the data in the three column format: user id, movie id, and ratings.
2. A/B Testing
A/B Testing is a process to compare the response of the users with respect to two different variations.

As you can see in the diagram, randomly selected half of the users are shown variation A and other half is shown variation B. We can clearly see that variation A is very effective because it is giving double conversions.
This method is effective only if we have a significant amount of users. Also, the ratio of the users need not be 50-50.
To manage so many variations on such a high number of users, we generally need Big Data platforms.
Big Data Customers
1. Government
Since governments have huge data about the citizens, any analysis would be Big Data analysis. The applications are many.
First is Fraud Detection. Be it antimony laundering or user identification, the amount of data processing required is really high.
In Cyber Security Welfare and Justice, the Big Data is being generated and Big Data tools are getting adopted.
2. Telecom
The telecom companies can use big data in order to understand why their customers are leaving and how they can prevent their customers from leaving. This is known as customer churn prevention.
The data that could help in customer churn prevention is
- How many calls did customers make to the call center?
- For how long were they out of coverage area?
- What was the usage pattern?
The other use-case is Network Performance Optimization. Based on the past history of traffic, the telecoms can forecast the network traffic and accordingly optimize the performance.
Third most common use-case of Big Data in Telecommunication industry is Calling Data Record Analysis. Since there are millions of users of a telecom company and each user makes 100s of calls per day. Analysing the calling Data records is a Big Data problem.
It is very much possible to predict the failure of hardware based on all the data points when previous failures occurred. A seemingly impossible task is possible because of the sheer volume of data.
3. Healthcare
Healthcare inherently has humongous data and complex problems to solve. Such problems can be solved with the new Big Data Technologies as supercomputers could not solve most of these problems.
Few examples of such problems are Health information exchange, Gene sequencing, Healthcare improvements and Drug Safety.

Data Variety
The first term that you must know in Big Data is Data Variety. You will often come across this term as we move forward in the Big Data course. So let’s quickly define different data structures for your quick understanding.
Data is largely classified as Structured, Semi-Structured and Un-Structured.
 1. Structured Data
1. Structured Data
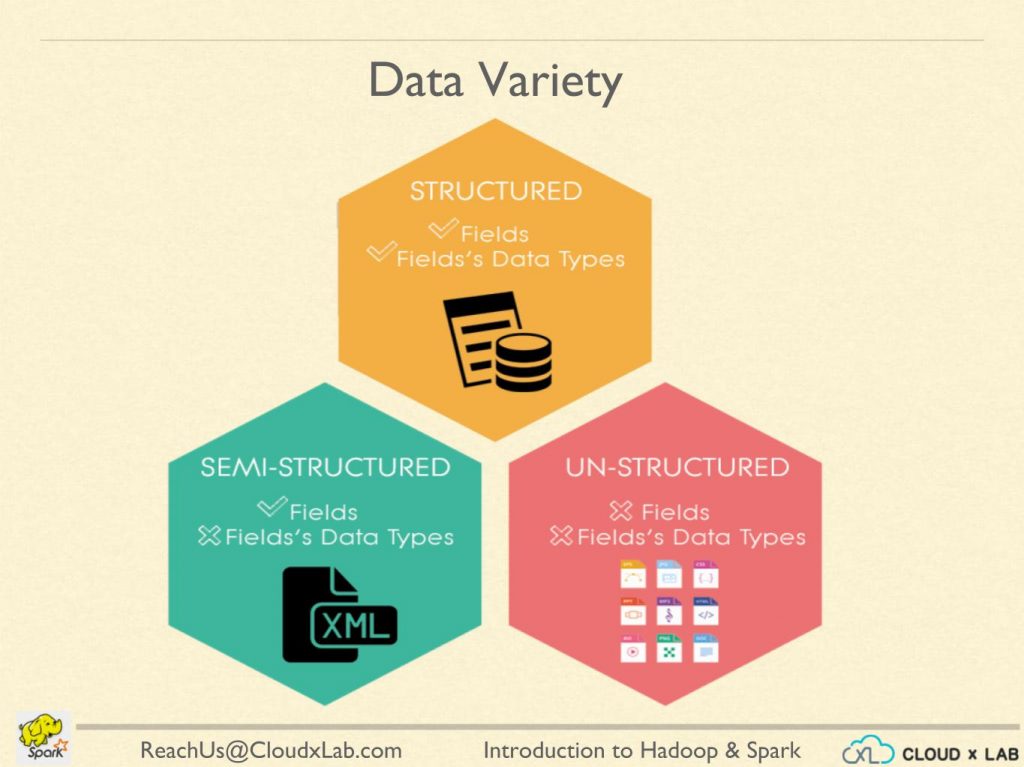
If we clearly know the number of fields as well as their datatype, then we call it structured. More often than not, you will find structured data in the tabular form. The data in relational databases such as MySQL, Oracle or Microsoft SQL is an example of structured data.
2. Semi-Structured Data
The data in which we know the number of fields or columns but we do not know their datatypes, we call such data as semi-structured data. For example, data in CSV which is comma separated values is known as semi-structured data.
3. Unstructured Data
If the data doesn’t contain columns or fields, we call it unstructured data. The data in the form of plain text files or logs generated on a server are examples of unstructured data.
Now that we know the data variety we can discuss one of the significant problems in Big Data – ETL
ETL stands for Extract, Transform and Load. It is the process of translating unstructured data into structured data.
ETL is a big problem in Big Data. Which is why Data engineers spend a significant amount of their time on ETL. We will learn more about it in the later articles.
Distributed Systems
The second term that you will see a lot while learning Big Data technologies is Distributed system.
When networked computers are utilized to achieve a common goal, it is known as a distributed system. The work gets distributed amongst many computers.
Please note that distributed systems doesn’t mean that systems are just connected. The networked computers must work together to solve a problem and only then can it be called distributed system. It is also important to note that Big Data is largely about Distributed systems.
The branch of computing that studies distributed systems is known as distributed computing.
The purpose of distributed computing is to get the work done faster by utilizing many computers. Most but not all the tasks can be performed using distributed computing.
Big Data Solutions
There are many Big Data Solution stacks. Some popular stacks are listed below.
- Apache Hadoop
- Apache Spark
- Cassandra
- MongoDB
- Google Compute Engine
- Microsoft Azure
The first and most powerful stack is Apache Hadoop and Spark together. While Hadoop provides storage for structured and unstructured data, the Spark provides the computational capability on top of Hadoop.
The second way would be to use Cassandra or MongoDB. These are NoSQL Databases which run on multiple computers to provide huge volume, handle high velocity and the data in the complex structure.
Third could be to use Google Compute Engine or Microsoft Azure. In such cases, you would have to upload your data to Google or Microsoft which may not be acceptable to your organization sometimes.
Next Steps
If you like the article and love to know more about Big Data, then you can see our Big Data course. CloudxLab provides both self-paced & online instructor-led training in Big Data technologies.
The course comes with the free lab subscription which comes handy in practicing Big Data technologies.