What is a Rate Limiter?
Rate limiting refers to preventing the frequency of an operation from exceeding a defined limit. In large-scale systems, rate limiting is commonly used to protect underlying services and resources. In distributed systems, Rate limiting is used as a defensive mechanism to protect the availability of shared resources. It is also used to protect APIs from unintended or malicious overuse by limiting the number of requests that can reach our API in a given period of time.
In this blog, we’ll see how will tackle the question of designing a rate limiter in a system design interview.
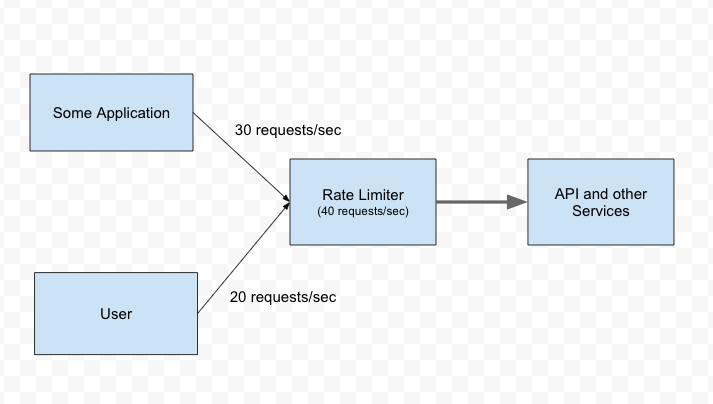
Examples of Rate Limiter
Amazon EC2 throttles EC2 API requests for each AWS account on a per-Region basis.
It uses the token bucket algorithm to implement API throttling.
- Stripe API (https://stripe.com/docs/rate-limits)
For most APIs, Stripe allows up to 100 read operations per second and 100 write operations per second in live mode, and 25 operations per second for each in test mode.
Twitter has various rate limits to manage tweets and search tweets
Why Rate Limiter is required?
Rate limiting is a very important part of any large-scale system and APIs and it can be used to accomplish the following:
- Preventing resource starvation
It can happen when a large number of requests come in a very short period of time or due to Denial of Service (DoS) attacks.
- Managing policies and quotas
To allow access to only authenticated users to allow usage to them based on their quota
- Controlling flow
In complex systems, it can be used to control the flow between linked services to stop one service from accumulating all the resources
- Avoiding excess cost
If the resources can auto scale, rate limiting is used to control the excess cost if something goes out of control
Algorithms used in Rate Limiter
- Leaky Bucket
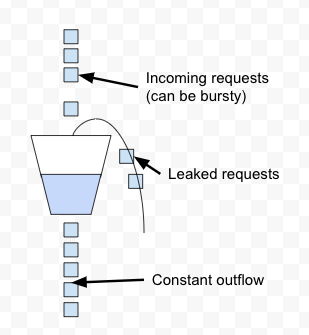
Leaky Bucket is a simple and intuitive way to implement rate limiting using a queue. It is a simple first-in, first-out queue (FIFO). Incoming requests are appended to the queue and if there is no room for new requests they are discarded (leaked).
It maintains a constant near uniform flow to the server as it processes the requests at a constant rate. It is easy to implement on a load balancer and is memory efficient for each user.
- Token Bucket
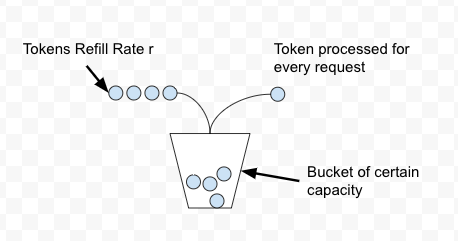
In the Token Bucket algorithm, we process a token from the bucket for every request. New tokens are added to the bucket with rate r. The bucket can hold a maximum of b tokens. If a request comes and the bucket is full it is discarded.
- Fixed Window
We keep a counter for a given duration of time and increment it for every incoming request. Once the limit is reached, the next requests are discarded until the counter is reset after the time has passed.
- Sliding Log
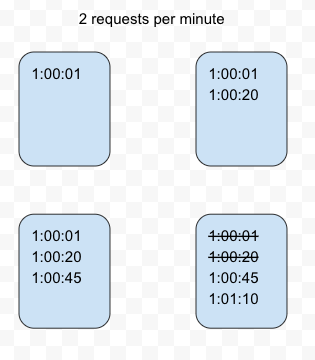
The sliding Log algorithm maintains a time-stamped log for each request on the user level. The system stores these logs in a time-sorted hash set or table. Logs with timestamps beyond a threshold are discarded. We look for older requests and discard them. Then we calculate the sum of logs to determine the request rate. If the request is below the threshold rate, it is processed else it is held.
- Sliding Window
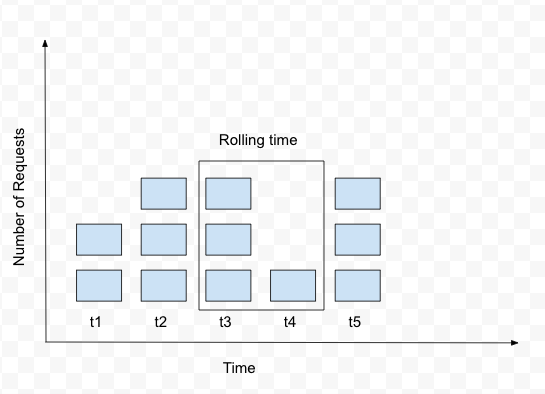
It is more memory efficient than sliding log algorithm. It combines the fixed window algorithm’s low processing cost and the sliding log’s improved boundary conditions. We keep a sliding window of our time duration and only service requests in our window for the given rate. If the sum of counters is more than the given rate of the limiter, then we take only the first sum of entries equal to the rate limit.
How will you design a rate limiter for your API?
Suppose you are asked a question to design a rate limiter. You should first know the requirements by asking various questions to the interviewer.
Candidate: What kind of rate limiter are we going to design? Will it be client side or server side?
Interviewer: We will be designing server-side rate limiter for our API.
Candidate: Will we throttle the API based on requests per second, IP or anything else?
Interviewer: We will throttle the API based on requests per second.
Candidate: Suppose this is an asynchronous job. So, we have a couple of options:
Option 1: Throttle on the API level
Option 2: Throttle after Request Queue
Here are popular algorithms for rate limiting
- Leaky Bucket
- Token Bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
You can describe pros and cons of these algorithms as above.