In this post, we will learn how to configure tools required for CloudxLab’s Python for Machine Learning course. We will use Python 3 and Jupyter notebooks for hands-on practicals in the course. Jupyter notebooks provide a really good user interface to write code, equations, and visualizations.
Please choose one of the options listed below for practicals during the course.
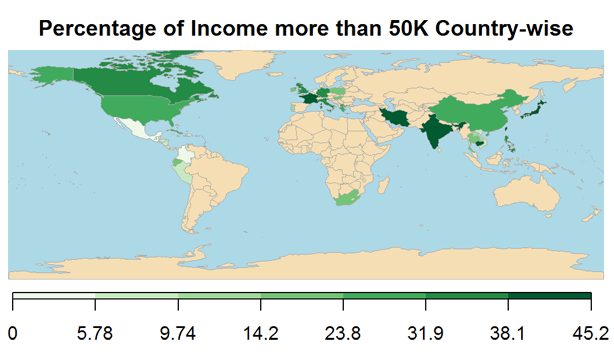
In this data analytics case study, we will use the US census data to build a model to predict if the income of any individual in the US is greater than or less than USD 50000 based on the information available about that individual in the census data.
The dataset used for the analysis is an extraction from the 1994 census data by Barry Becker and donated to the public site http://archive.ics.uci.edu/ml/datasets/Census+Income. This dataset is popularly called the “Adult” data set. The way that we will go about this case study is in the following order:
Describe the data- Specifically the predictor variables (also called independent variables features) from the Census data and the dependent variable which is the level of income (either “greater than USD 50000” or “less than USD 50000”).
Acquire and Read the data- Downloading the data directly from the source and reading it.
Clean the data- Any data from the real world is always messy and noisy. The data needs to be reshaped in order to aid exploration of the data and modeling to predict the income level.
Explore the independent variables of the data- A very crucial step before modeling is the exploration of the independent variables. Exploration provides great insights to an analyst on the predicting power of the variable. An analyst looks at the distribution of the variable, how variable it is to predict the income level, what skews it has, etc. In most analytics project, the analyst goes back to either get more data or better context or clarity from his finding.
Build the prediction model with the training data- Since data like the Census data can have many weak predictors, for this particular case study I have chosen the non-parametric predicting algorithm of Boosting. Boosting is a classification algorithm (here we classify if an individual’s income is “greater than USD 50000” or “less than USD 50000”) that gives the best prediction accuracy for weak predictors. Cross validation, a mechanism to reduce over fitting while modeling, is also used with Boosting.
Validate the prediction model with the testing data- Here the built model is applied on test data that the model has never seen. This is performed to determine the accuracy of the model in the field when it would be deployed. Since this is a case study, only the crucial steps are retained to keep the content concise and readable.
Buoyed by the success of our previous webinar and excited by the unending curiosity of our audience, we at CloudxLab decided to conduct another webinar on “Big Data & AI” on 24th August. Mr Sandeep Giri, founder of CloudxLab, was the lead presenter in the webinar. A graduate from IIT Roorkee with more than 15 years of experience in companies such as DE Shaw, Inmobi & Amazon, Sandeep conducted the webinar to the appreciation of all.
Artificial Intelligence (AI) is the buzzword that is resounding and echoing all over the world. While large corporations, organizations & institutions are publicly proclaiming and publicizing their massive investments toward development and deployment of AI capabilities, people, in general, are feeling perplexed regarding the meaning and nuances of AI. This blog is an attempt to demystify AI and provide a brief introduction to the various aspects of AI to all such persons, engineers, non-engineers & beginners, who are seeking to understand AI. In the forthcoming discussion, we will explore the following questions:
What is AI & what does it seek to accomplish?
How will the goals of AI be accomplished, through which methodologies?
Understanding the current scenario of tremendous interest of students and professionals regarding “Big Data & AI”, CloudxLab conducted a webinar on July 12, 2017 to introduce and explain the many nuances of this upcoming field to all the enthusiasts. Mr Sandeep Giri, founder of CloudxLab with more than 15 years of experience in the industry with companies such as Amazon, InMobi, DE Shaw etc., was the lead presenter in the webinar.
We recently had a heart warming moment – one of our subscribers had been made an offer by Tata Consultancy Services. His thank you note to us made our day. Meara Laxman had subscribed to CloudxLab to practice his Big Data skills and as per him got more than he expected. Here is our interview with him.
CxL: How did CloudxLab help you learn Big Data tools better?
Laxman: Cloudxlab helped me a lot in learning all the Bigdata eco system components. I had gained enough theoretical knowledge on big data tools from the internet but I ran into trouble trying to practice due to my incompatible system requirements and configurations. That is when I found Cloudxlab and subscribed to it. I got good exposure to the practical aspects as Cloudxlab provided some sample lab session video material which are very clear and easy to practice and understand. Moreover, the Cloudxlab team helped me every time I had an issue and clarified all my queries.
In this blog post, we will learn how to install Python packages on CloudxLab.
Step 1-
Create the virtual environment for your project. A virtual environment is a tool to keep the dependencies required by different projects in separate places, by creating virtual Python environments for them. Login to CloudxLab web console and create a virtual environment for your project.
First of all, let’s switch to python3 using:-
export PATH=/usr/local/anaconda/bin:$PATH
Now let’s create a directory and the virtual environment inside it.
It is really a great site. As a 37-year-old with a masters
in mechanical engineering, I decided to switch careers
and get another masters. One of my courses was
Big Data and, at the beginning, I was completely lost
& I was falling behind in my assignments and after
searching the internet for a solution, finally found CloudxLab.
Not only do they have any conceivable Big Data
technology on their servers, they have superb
customer support. Whenever I have had a doubt,
even in debugging my own programs, they have
answered me with the correct solution in a few hours.
How does CloudxLab help with preparing for Cloudera, Hortonworks, and related certifications? Here is an interview with one of our users who
has successfully completed the ‘Cloudera Certified Associate for Spark and Hadoop Developer‘ (CCA175) certification using CloudxLab for hands-on practice. Having completed the certification, Senthil Ramesh who is currently working with Accenture, gladly discussed his experience with us.
CxL: How did CloudxLab help you with the Cloudera certification and help you learn Big Data overall?
Senthil: CloudxLab played an important part in the hands on experience for my big data learning. As soon as I understood that my laptop may not be able to support all the tools necessary to work towards the certification, I started looking for a cloud based solution and found CloudxLab. The sign up was easy and everything was setup in a short time. I must say, without doing hands on it would have been harder to crack the certification. Thanks to CloudxLab for that.
CloudxLab is proud to announce its partnership with TechMahindra’s UpX Academy. TechM’s e-learning platform, UpX Academy, delivers courses in Big Data & Data Sciences. With programs spanning over 6-12 weeks and covering in-demand skills such as Hadoop, Spark, Machine Learning, R and Tableau, UpX has tied up with CloudxLab to provide the latest to its course takers.
Run by an excellent team, we at CloudxLab are in awe of the attention UpX pays to the users needs. As Sandeep (CEO at CloudxLab) puts it, “We were not surprised when UpX decided to come on board. Their ultimate interest is in keeping their users happy and we are more than glad to work with them on this.”





 Hadoop Developer‘ (CCA175) certification using CloudxLab for hands-on practice. Having completed the certification,
Hadoop Developer‘ (CCA175) certification using CloudxLab for hands-on practice. Having completed the certification,