Here are the top Apache Spark interview questions and answers. There is a massive growth in the big data space, and job opportunities are skyrocketing, making this the perfect time to launch your career in this space.
Our experts have curated these questions to give you an idea of the type of questions which may be asked in an interview. Hope these Apache Spark interview questions and answers guide will help you in getting prepared for your next interview.

1. What is Apache Spark and what are the benefits of Spark over MapReduce?
- Spark is really fast. If run in-memory it is 100x faster than Hadoop MapReduce.
- In Hadoop MapReduce, you write many MapReduce jobs and then tie these jobs together using Oozie/shell script. This mechanism is very time consuming and MapReduce tasks have heavy latency. Between two consecutive MapReduce jobs, the data has to be written to HDFS and read from HDFS. This is time-consuming. In case of Spark, this is avoided using RDDs and utilizing memory (RAM). And quite often, translating the output of one MapReduce job into the input of another MapReduce job might require writing another code because Oozie may not suffice.
- In Spark, you can basically do everything from single code or console (PySpark or Scala console) and get the results immediately. Switching between ‘Running something on cluster’ and ‘doing something locally’ is fairly easy and straightforward. This also leads to less context switch of the developer and more productivity.
- Spark kind of equals to MapReduce and Oozie put together.
Watch this video to learn more about benefits of using Apache Spark over MapReduce.
2. Is there any point of learning MapReduce, then?
- MapReduce is a paradigm used by many big data tools including Spark. So, understanding the MapReduce paradigm and how to convert a problem into series of MapReduce tasks is very important.
- Many organizations have already written a lot of code in MapReduce. For legacy reasons, it is required.
- Almost, every other tool such as Hive or Pig converts its query into MapReduce phases. If you understand the MapReduce then you will be able to optimize your queries better.
3. What are the downsides of Spark?
Spark utilizes the memory. So, in a shared environment, it might consume little more memory for longer durations.
The developer has to be careful. A casual developer might make following mistakes:
- She may end up running everything on the local node instead of distributing work over to the cluster.
- She might hit some web service too many times by the way of using multiple clusters.
The first problem is well tackled by Hadoop MapReduce paradigm as it ensures that the data your code is churning is fairly small a point of time thus you can make a mistake of trying to handle whole data on a single node.
The second mistake is possible in MapReduce too. While writing MapReduce, a user may hit a service from inside of map() or reduce() too many times. This overloading of service is also possible while using Spark.
4. Explain in brief what is the architecture of Spark?
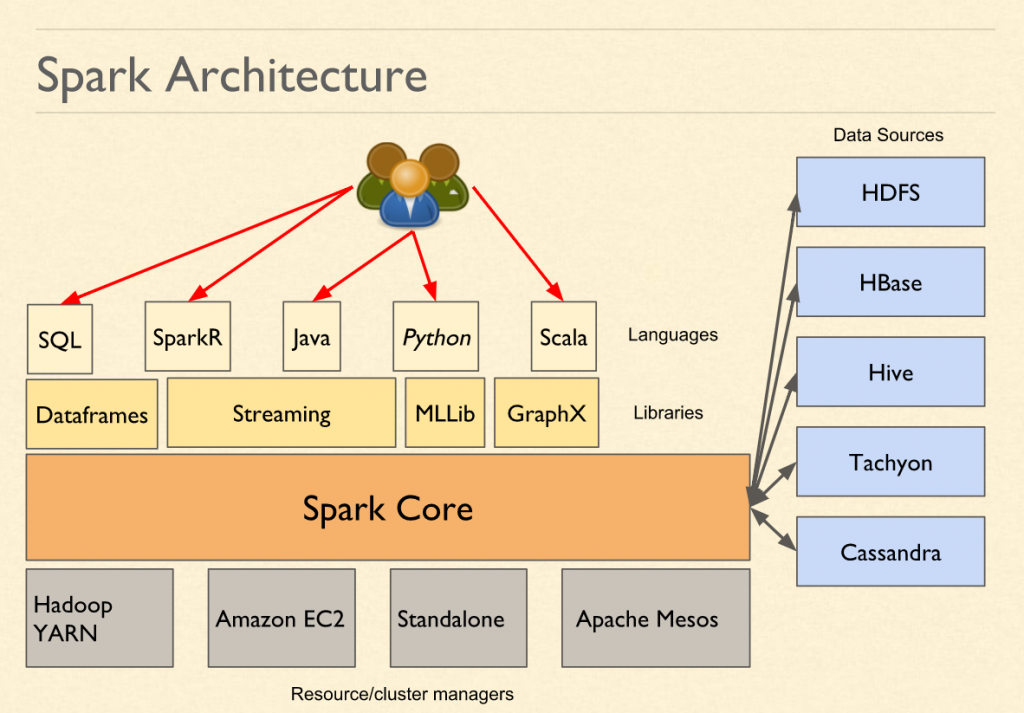
At the architecture level, from a macro perspective, the Spark might look like this:
Spark Architecture| 5) Interactive Shells or Job Submission Layer |
| 4) API Binding: Python, Java, Scala, R, SQL |
| 3) Libraries: MLLib, GraphX, Spark Streaming |
| 2) Spark Core (RDD & Operations on it) |
| 1) Spark Driver -> Executor |
| 0) Scheduler or Resource Manager |
0) Scheduler or Resource Manager:
At the bottom is the resource manager. This resource manager could be external such YARN or Mesos. Or it could be internal if the Spark is running in standalone mode. The role of this layer is to provide a playground in which the program can run distributively. For example, YARN (Yet Another Resource Manager) would create application master, executors for any process.
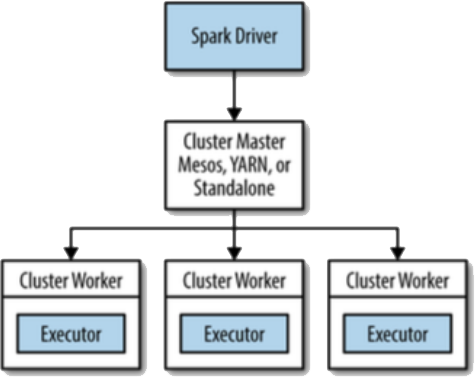
1) Spark Driver -> Executor:
One level above scheduler is the actual code by the Spark which talks to the scheduler to execute. This piece of code does the real work of execution. The Spark Driver that would run inside the application master is part of this layer. Spark Driver dictates what to execute and executor executes the logic.
2) Spark Core (RDD & Operations on it):
Spark Core is the layer which provides maximum functionality. This layer provides abstract concepts such as RDD and the execution of the transformation and actions.
3) Libraries: MLLib,, GraphX, Spark Streaming, Dataframes:
The additional vertical wise functionalities on top of Spark Core is provided by various libraries such as MLLib, Spark Streaming, GraphX, Dataframes or SparkSQL etc.
4) API Bindings are internally calling the same API from different languages.
5) Interactive Shells or Job Submission Layer:
The job submission APIs provide a way to submit bundled code. It also provides interactive programs (PySpark, SparkR etc.) that are also called REPL or Read-Eval-Print-Loop to process data interactively.
Watch this video to learn more about Spark architecture.
5. On which all platform can Apache Spark run?
Spark can run on the following platforms:
- YARN (Hadoop): Since yarn can handle any kind of workload, the spark can run on Yarn. Though there are two modes of execution. One in which the Spark driver is executed inside the container on node and second in which the Spark driver is executed on the client machine. This is the most common way of using Spark.
- Apache Mesos: Mesos is an open source good upcoming resource manager. Spark can run on Mesos.
- EC2: If you do not want to manage the hardware by yourself, you can run the Spark on top of Amazon EC2. This makes spark suitable for various organizations.
- Standalone: If you have no resource manager installed in your organization, you can use the standalone way. Basically, Spark provides its own resource manager. All you have to do is install Spark on all nodes in a cluster, inform each node about all nodes and start the cluster. It starts communicating with each other and run.
6. What are the various programming languages supported by Spark?
Though Spark is written in Scala, it lets the users code in various languages such as:
- Scala
- Java
- Python
- R (Using SparkR)
- SQL (Using SparkSQL)
Also, by the way of piping the data via other commands, we should be able to use all kinds of programming languages or binaries.
7. What are the various modes in which Spark runs on YARN? (Local vs Client vs Cluster Mode)
Apache Spark has two basic parts:
- Spark Driver: Which controls what to execute where
- Executor: Which actually executes the logic
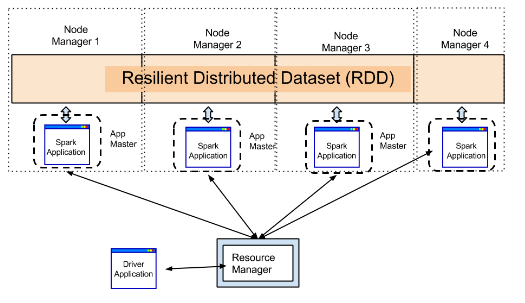
While running Spark on YARN, though it is very obvious that executor will run inside containers, the driver could be run either on the machine which user is using or inside one of the containers. The first one is known as Yarn client mode while second is known as Cluster-Mode. The following diagrams should give you a good idea:
YARN client mode: The driver is running on the machine from which client is connected
YARN cluster mode: The driver runs inside the cluster.
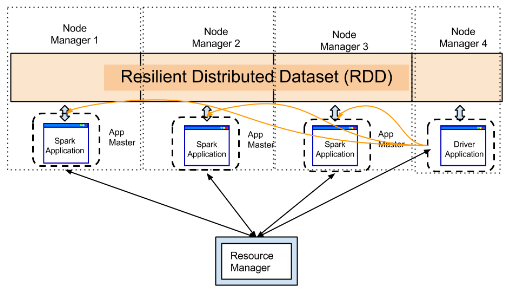
Watch this video to learn more about cluster mode.
Local mode: It is only for the case when you do not want to use a cluster and instead want to run everything on a single machine. So Driver Application and Spark Application are both on the same machine as the user.
Watch this video to learn more about local mode.
8. What are the various storages from which Spark can read data?
Spark has been designed to process data from various sources. So, whether you want to process data stored in HDFS, Cassandra, EC2, Hive, HBase, and Alluxio (previously Tachyon). Also, it can read data from any system that supports any Hadoop data source.
9. While processing data from HDFS, does it execute code near data?
Yes, it does in most cases. It creates the executors near the nodes that contain data.
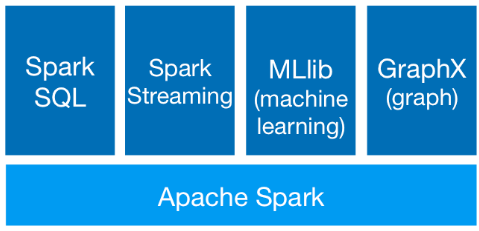
10. What are the various libraries available on top of Apache Spark?
Spark powers a stack of libraries including SQL and DataFrames, MLlib for machine learning, GraphX, and Spark Streaming. You can combine these libraries seamlessly in the same application.
- MLlib: It is machine learning library provided by Spark. It basically has all the algorithms that internal are wired to use Spark Core (RDD Operations) and the data structures required. For example, it provides ways to translate the Matrix into RDD and recommendation algorithms into sequences of transformations and actions. MLLib provides the machine learning algorithms that can run parallelly on many computers.
- GraphX: GraphX provides libraries which help in manipulating huge graph data structures. It converts graphs into RDD internally. Various algorithms such PageRank on graphs are internally converted into operations on RDD.
- Spark Streaming: It is a very simple library that listens on unbounded data sets or the datasets where data is continuously flowing. The processing pauses and waits for data to come if the source isn’t providing data. This library converts the incoming data streaming into RDDs for the “n” seconds collected data aka batch of data and then run the provided operations on the RDDs.
11. Does Spark provide the storage layer too?
No, it doesn’t provide storage layer but it lets you use many data sources. It provides the ability to read from almost every popular file systems such as HDFS, Cassandra, Hive, HBase, SQL servers.
12. Where does Spark Driver run on Yarn?
If you are submitting a job with –master client, the Spark driver runs on the client’s machine. If you are submitting a job with –master yarn-cluster, the Spark driver would run inside a YARN container.
Watch this video to learn more about deployment modes in Spark
13. To use Spark on an existing Hadoop Cluster, do we need to install Spark on all nodes of Hadoop?
See question above: What are the various modes in which Spark runs on YARN? (Client vs Cluster Mode)
Since Spark runs as an application on top of Yarn, it utilizes yarn for the execution of its commands over the cluster’s nodes. So, you do not need to install the Spark on all nodes. When a job is submitted, the Spark will be installed temporarily on all nodes on which execution is needed.
14. What is sparkContext?
SparkContext is the entry point to Spark. Using sparkContext you create RDDs which provided various ways of churning data.
15. What is DAG – Directed Acyclic Graph?
Directed Acyclic Graph – DAG is a graph data structure having edges which are directional and do not have any loops or cycles.
People use DAG almost all the time. Let’s take an example of getting ready for office.
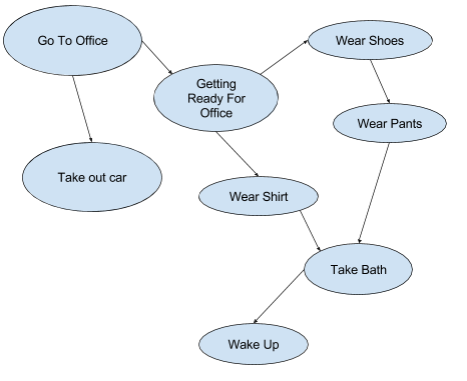
DAG is a way of representing dependencies between objects. It is widely used in computing. The examples where it is used in computing are:
- Build tools such Apache Ant, Apache Maven, make, sbt
- Tasks Dependencies in project management – Microsoft Project
- The data model of Git
16. What is an RDD?
The full form of RDD is a resilient distributed dataset. It is a representation of data located on a network which is
- Immutable – You can operate on the RDD to produce another RDD but you can’t alter it.
- Partitioned / Parallel – The data located on RDD is operated in parallel. Any operation on RDD is done using multiple nodes.
- Resilience – If one of the nodes hosting the partition fails, other nodes takes its data.
You can always think of RDD as a big array which is under the hood spread over many computers which are completely abstracted. So, RDD is made up many partitions each partition on different computers.
RDD provides two kinds of operations: Transformations and Actions.
RDD can hold data of any type from any supported programming language such as Python, Java, Scala. The case where RDD’s each element is a tuple – made up of (key, value) is called Pair RDD. PairRDDs provides extra functionalities such as “group by” and joins.
RDD is generally lazily computed i.e. it is not computed unless an action on it is called. So, RDD is either prepared out of another RDD or it is loaded from a data source. In case, it is loaded from another data source it has a binding between the actual data storage and partitions. So, RDD is essentially a pointer to actual data, not data unless it is cached.
If a machine that holds a partition of RDD dies, the same partition is regenerated using the lineage graph of RDD.
If there is a certain RDD that you require very frequently, you can cache it so that it is readily available instead of re-computation every time. Please note that the cached RDD will be available only during the lifetime of the application. If it is costly to recreate the RDD every time, you may want to persist it to the disc.
RDD can be stored at various data storage (such as HDFS, database etc.) in many formats.
Watch this video to learn more about Spark RDD
17. What is lazy evaluation and how is it useful?
Imagine there are two restaurants I (immediate) and P (patient).
In a restaurant I, the waiters are very prompt – as soon as you utter the order they run to the kitchen and place an order to the chef. If you have to order multiple things, the waiter will make multiple trips to the kitchen.
In P, the waiter patiently hears your orders and once you confirm your orders they go to the chef and place the orders. The waiter might combiner multiple dishes into one and prepare. This could lead to tremendous optimization.
While in the restaurant I, the work appears to happen immediately, in restaurant P the work would be actually fast because of clubbing multiple items together for preparation and serving. Restaurant P is doing we call ‘Lazy Evaluation’.
Examples of lazy evaluations are Spark, Pig (Pig Latin). The example of immediate execution could be Python interactive shell, SQL etc.
Watch this video to learn more about lazy evaluation and lineage graph in Spark.
18. How to create an RDD?
You can create an RDD from an in-memory data or from a data source such as HDFS.
You can load the data from memory using parallelize method of Spark Context in the following manner, in python:
myrdd = sc.parallelize([1,2,3,4,5]);
Here myrdd is the variable that represents an RDD created out of an in-memory object. “sc” is the sparkContext which is readily available if you are running in interactive mode using PySpark. Otherwise, you will have to import the SparkContext and initialize.
And to create RDD from a file in HDFS, use the following:
linesrdd = sc.textFile("/data/file_hdfs.txt");
This would create linesrdd by loading a file from HDFS. Please note that this will work only if your Spark is running on top of Yarn. In case, you want to load the data from external HDFS cluster, you might have to specify the protocol and name node:
linesrdd = sc.textFile("hdfs://namenode_host/data/file_hdfs.txt");
In the similar fashion, you can load data from third-party systems.
Watch this video to learn more about how to create an RDD in Spark.
19. When we create an RDD, does it bring the data and load it into the memory?
No. An RDD is made up of partitions which are located on multiple machines. The partition is only kept in memory if the data is being loaded from memory or the RDD has been cached/persisted into the memory. Otherwise, an RDD is just mapping of actual data and partitions.
20. If there is certain data that we want to use again and again in different transformations, what should improve the performance?
RDD can be persisted or cached. There are various ways in which it can be persisted: in-memory, on disc etc. So, if there is a dataset that needs a good amount computing to arrive at, you should consider caching it. You can cache it to disc if preparing it again is far costlier than just reading from disc or it is very huge in size and would not fit in the RAM. You can cache it to memory if it can fit into the memory.
Watch this video to learn more about persisting Spark RDD.
21. What happens to RDD when one of the nodes on which it is distributed goes down?
Since Spark knows how to prepare a certain data set because it is aware of various transformations and actions that have lead to the dataset, it will be able to apply the same transformations and actions to prepare the lost partition of the node which has gone down.
22. How to save RDD?
There are few methods provided by Spark:
- saveAsTextFile: Write the elements of the RDD as a text file (or set of text files) to the provided directory. The directory could be in the local filesystem, HDFS or any other file system. Each element of the dataset will be converted to text using toString() method on every element. And each element will be appended with newline character “\n”
- saveAsSequenceFile: Write the elements of the dataset as a Hadoop SequenceFile. This works only on the key-value pair RDD which implement Hadoop’s Writeable interface. You can load sequence file using sc.sequenceFile().
- saveAsObjectFile: This simply saves data by serializing using standard java object serialization.
23. What do we mean by Paraquet?
Apache Paraquet is a columnar format for storage of data available in Hadoop ecosystem. It is space efficient storage format which can be used in any programming language and framework.
Apache Spark supports reading and writing data in Paraquet format.
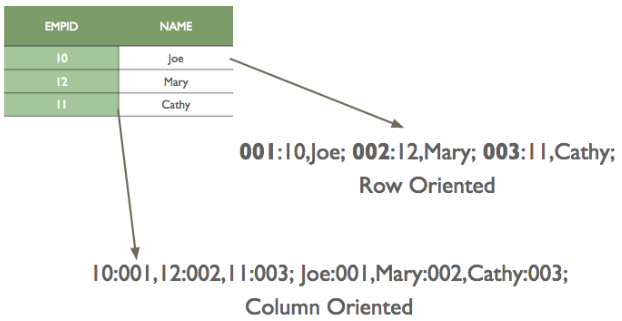
24. What does it mean by Columnar Storage Format?
While converting a tabular or structured data into the stream of bytes we can either store row-wise or we could store column-wise.
In row-wise, we first store the first row and then store the second row and so on. In column-wise, we first store first column and second column.
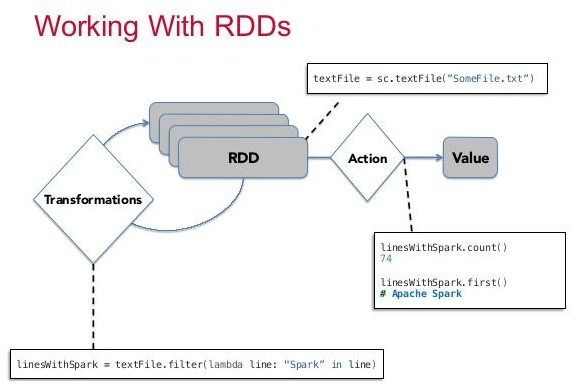
25. When creating an RDD, what goes on internally?
There are two ways to create RDD. One while loading data from a source. Second, by operating on existing RDD. And an action causes the computation from an RDD to yield the result. The diagram below shows the relationship between RDD, transformations, actions and value/result.
- While loading Data from Source – When an RDD is prepared by loading data from some source (HDFS, Cassandra, in-memory), the machines which exist nearer to the data are assigned for the creation of partitions. These partitions would hold the parts of mappings or pointers to the actual data. When we are loading data from the memory (for example, by using parallelize), the partitions would hold the actual data instead of pointers or mapping
- By converting an in-memory array of objects – An in-memory object can be converted to an RDD using parallelize.
- By operating on existing RDD – An RDD is immutable. We can’t change an existing RDD. We can only form a new RDD based on the previous RDD by operating on it. When operating on existing RDD, a new RDD is formed. These operations are also called transformations. The operation could also result in shuffling – moving data across the nodes. Some operations that do not cause shuffling: map, flatMap and filter. Examples of the operations that could result in shuffling are groupByKey, repartition, sortByKey, aggregateByKey, reduceByKey, distinct.Spark maintains the relationship between the RDD in the form of a DAG (Directed Acyclic Graph). When an action such reduce() or saveAsTextFile() is called, the whole graph is evaluated and the result is returned to the driver or saved to the location such as HDFS.
26. What do we mean by Partitions or slices?
Partitions (also known as slices earlier) are the parts of RDD. Each partition is generally located on a different machine. Spark runs a task for each partition during the computation.
If you are loading data from HDFS using textFile(), it would create one partition per block of HDFS(64MB typically). Though you can change the number of partitions by specifying the second argument in the textFile() function.
If you are loading data from an existing memory using sc.parallelize(), you can enforce your number of partitions by passing the second argument.
You can change the number of partitions later using repartition().
If you want certain operations to consume the whole partitions at a time, you can use map partition().
27. What is meant by Transformation? Give some examples.
The transformations are the functions that are applied on an RDD (resilient distributed dataset). The transformation results in another RDD. A transformation is not executed until an action follows.
Some examples of transformation are:
- map() – applies the function passed to it on each element of RDD resulting in a new RDD.
- filter() – creates a new RDD by picking the elements from the current RDD which pass the function provided as an argument
Watch this video to learn more about transformations in Spark.
28. What does map transformation do? Provide an example.
Map transformation on an RDD produces another RDD by translating each element. It translates each element by executing the function provided by the user.
29. What is the difference between map and flatMap?
Map and flatMap both functions are applied to each element of RDD. The only difference is that the function that is applied as part of the map must return only one value while flatMap can return a list of values.So, flatMap can convert one element into multiple elements of RDD while map can only result in an equal number of elements.
So, flatMap can convert one element into multiple elements of RDD while map can only result in an equal number of elements.
So, if we are loading RDD from a text file, each element is a sentence. To convert this RDD into an RDD of words, we will have to apply using flatMap a function that would split a string into an array of words. If we have just to clean up each sentence or change case of each sentence, we would be using the map instead of flatMap. See the diagram below.
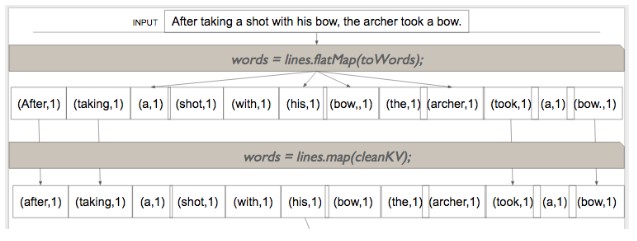
Watch this video to learn more about differences between the map and flatMap transformations in Spark.
30. What are Actions? Give some examples.
An action brings back the data from the RDD to the local machine. Execution of an action results in all the previously created transformation. The example of actions are:
- reduce() – executes the function passed again and again until only one value is left. The function should take two arguments and return one value.
- take() – take all the values back to the local node from RDD.
Watch this video to learn more about actions in Spark.
31. What does reduce action do?
A reduce action converts an RDD to a single value by applying recursively the provided (in argument) function on the elements of an RDD until only one value is left. The provided function must be commutative and associative – the order of arguments or in what way we apply the function should not make difference.
The following diagram shows the process of applying “sum” reduce function on an RDD containing 1, 2, 3, 4.
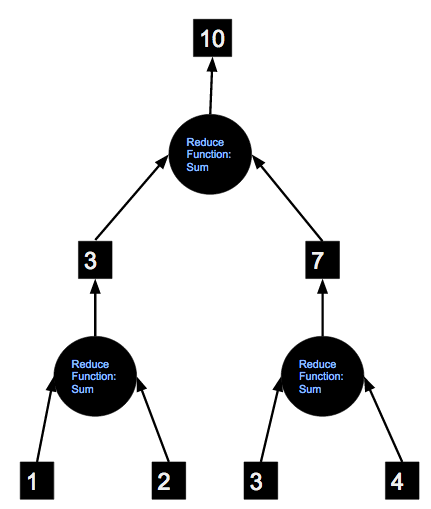
Watch this video to learn more about the reduce action in Spark.
32. What is broadcast variable?
Quite often we have to send certain data such as a machine learning model to every node. The most efficient way of sending the data to all of the nodes is by the use of broadcast variables.
Even though you could refer an internal variable which will get copied everywhere but the broadcast variable is far more efficient. It would be loaded into the memory on the nodes only where it is required and when it is required not all the time.
It is sort of a read-only cache similar to distributed cache provided by Hadoop MapReduce.
Watch this video to learn more about broadcast variables in Spark.
33. What is accumulator?
An accumulator is a good way to continuously gather data from a Spark process such as the progress of an application. The accumulator receives data from all the nodes in parallel efficiently. Therefore, only the operations in order of operands don’t matter are valid accumulators. Such functions are generally known as associative operations.
An accumulator a kind of central variable to which every node can emit data.
Watch this video to learn more about accumulators in Spark.
34. Say I have a huge list of numbers in RDD(say myRDD). And I wrote the following code to compute average:
def myAvg(x, y):
return (x+y)/2.0;
avg = myrdd.reduce(myAvg);
What is wrong with it and how would you correct it?
The average function is not commutative and associative. I would simply sum it and then divide by count.
def sum(x, y):
return x+y;
total = myrdd.reduce(sum);
avg = total / myrdd.count();
The only problem with the above code is that the total might become very big thus overflow. So, I would rather divide each number by count and then sum in the following way.
cnt = myrdd.count();
def devideByCnd(x):
return x/cnt;
myrdd1 = myrdd.map(devideByCnd);
avg = myrdd.reduce(sum);
The problem with above code is that it uses two jobs – one for the count and other for the sum. We can do it in a single shot as follows:
myrdd = sc.parallelize([1.1, 2.4, 5, 6.0, 2, 3, 7, 9, 11, 13, 10]) sumcount_rdd = myrdd.map(lambda n : (n, 1)) (total, counts) = sumcount_rdd.reduce(lambda a,b: (a[0]+b[0], a[1]+b[1])) avg = total/counts
Again, it might cause a number overflow because we are summing a huge number of values. We could instead keep the average values and keep computing the average from the average and counts of two parts getting reduced.
myrdd = sc.parallelize([1.1, 2.4, 5, 6.0, 2, 3, 7, 9, 11, 13, 10])
sumcount_rdd = myrdd.map(lambda n : (n, 1))
def avg(A, B):
R = 1.0*B[1]/A[1]
Ri = 1.0/(1+R);
av = A[0]*Ri + B[0]*R*Ri
return (av, B[1] + A[1]);
(av, counts) = sumcount_rdd.reduce(avg)
print(av)
If you have two parts having average and counts as (a1, c1) and (a2, c2), the overall average is:
total/counts = (total1 + total2)/ (count1 + counts2) = (a1*c1 + a2*c2)/(c1+c2)
If we mark R = c2/c1, It can be re-written further as a1/(1+R) + a2*R/(1+R)
If we further mark Ri as 1/(1+R), we can write it as a1*Ri + a2*R*Ri
myrdd = sc.parallelize([1.1, 2.4, 5, 6.0, 2, 3, 7, 9, 11, 13, 10])
sumcount_rdd = myrdd.map(lambda n : (n, 1))
def avg(A, B):
R = 1.0*B[1]/A[1]
Ri = 1.0/(1+R);
av = A[0]*Ri + B[0]*R*Ri
return (av, B[1] + A[1]);
(av, counts) = sumcount_rdd.reduce(avg)
print(av)
Watch this video to learn more about computing average in Spark.
35. Say I have a huge list of numbers in a file in HDFS. Each line has one number and I want to compute the square root of the sum of squares of these numbers. How would you do it?
# We would first load the file as RDD from HDFS on Spark
numsAsText = sc.textFile("hdfs:////user/student/sgiri/mynumbersfile.txt");
# Define the function to compute the squares
def toSqInt(str):
v = int(str);
return v*v;
#Run the function on Spark rdd as transformation nums = numsAsText.map(toSqInt); #Run the summation as reduce action total = nums.reduce(sum) #finally compute the square root. For which we need to import math. import math; print math.sqrt(total);
36. Is the following approach correct? Is the sqrtOfSumOfSq a valid reducer?
numsAsText = sc.textFile("hdfs:///user/student/sgiri/mynumbersfile.txt");
def toInt(str):
return int(str);
nums = numsAsText.map(toInt);
def sqrtOfSumOfSq(x, y):
return math.sqrt(x*x+y*y);
total = nums.reduce(sum)
import math;
print math.sqrt(total);
Yes. The approach is correct and sqrtOfSumOfSq is a valid reducer.
37. In a very huge text file, you want to just check if a particular keyword exists. How would you do this using Spark?
lines = sc.textFile("hdfs:///user/student/sgiri/bigtextfile.txt");
def isFound(line):
if line.find("mykeyword") > -1:
return 1;
return 0;
foundBits = lines.map(isFound);
sum = foundBits.reduce(sum);
if sum > 0:
print “FOUND”;
else:
print “NOT FOUND”;
38. Can you improve the performance of the code in the previous answer?
Yes. The search is not stopping even after the word we are looking for has been found. Our map code would keep executing on all the nodes which is very inefficient.
We could utilize accumulators to report whether the word has been found or not and then stop the job. Something on these lines.
import thread, threading
from time import sleep
result = "Not Set"
lock = threading.Lock()
accum = sc.accumulator(0)
def map_func(line):
#introduce delay to emulate the slowness
sleep(1);
if line.find("Adventures") > -1:
accum.add(1);
return 1;
return 0;
def start_job():
global result
try:
sc.setJobGroup("job_to_cancel", "some description")
lines = sc.textFile("hdfs:///user/student/sgiri/wordcount/input/big.txt");
result = lines.map(map_func);
result.take(1);
except Exception as e:
result = "Cancelled"
lock.release()
def stop_job():
while accum.value < 3 :
sleep(1);
sc.cancelJobGroup("job_to_cancel")
supress = lock.acquire()
supress = thread.start_new_thread(start_job, tuple())
supress = thread.start_new_thread(stop_job, tuple())
supress = lock.acquire()
This concludes our Spark interview questions guide. I hope these Spark interview questions will help you in preparing for your next interview.
At CloudxLab, we provide free projects on Spark to all our learners so that they can learn by doing. These projects will help you to apply your Spark knowledge in real-world scenarios. Please find the lists of Spark projects below
- Building Real-time Analytics Dashboard – In this project, you will build a real-time analytics dashboard for an e-commerce company using Spark, Kafka, Node.js, Socket.IO and Highcharts.
- Writing Spark Applications – In this project, you will learn how to write Spark project on your local machine, unit test it, commit it using Git, build on the production and deploy it. This is an end-to-end project to help you understand how to deploy a Spark project in production following the best practices.
- Apache Log Parsing – In this project, you will parse Apache logs using Spark to generate meaningful insights from logs.
Below is the list of our free topics on Scala, Linux, Java and Spark. We highly recommend our learners to go through these free topics before your next Spark interview
Please feel free to leave your comments in the comment box so that we can improve the guide and serve you better. Also, Follow CloudxLab on Twitter to get updates on new blogs and videos.
If you wish to learn Spark technologies such as RDD, Spark Streaming, Kafka, Dataframes, SparkSQL, SparkR, MLlib, GraphX and build a career in BigData and Spark domain then check out our signature course on Apache Spark which comes with
- Online instructor-led training by professionals having years of experience in building world-class BigData products
- High-quality learning content including videos and quizzes
- Automated hands-on assessments
- 90 days of lab access so that you can learn by doing
- 24×7 support and forum access to answer all your queries throughout your learning journey
- Real-world projects
- Certificate which you can share on LinkedIn
About author

Seasoned hands-on technical architect with years of experience in building world-class software products at Amazon and InMobi
Great stuff!
Very Impressive Spark tutorial. The content seems to be pretty exhaustive and excellent and will definitely help in learning Spark Project. I’m also a learner taken up Spark Tutorial and I think your content has cleared some concepts of mine. While browsing for Spark Training on YouTube i found this fantastic video on Spark Tutorial. Do check it out if you are interested to know more.:-https://www.youtube.com/watch?v=dMDQz82FCqE