Generally, Machine Learning (or Deep Learning) projects are quite unique and also different from traditional web application projects due to the inherent complexity involved with them.
The goal of this article is, not to go through full project management life cycle, but to discuss a few complexities and finer points which may impact different project management phases and aspects of a Machine Learning(or Deep Learning) project, and, which should be taken care of, to avoid any surprises later.
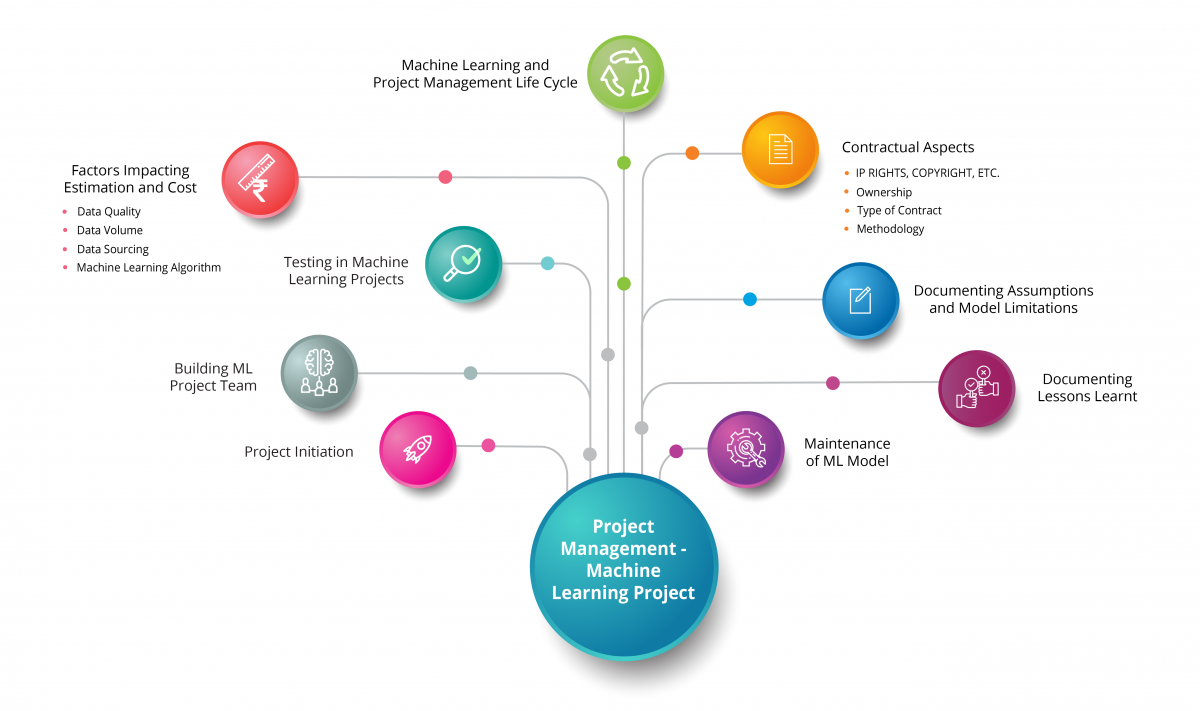
Below is a quick ready reckoner for the topics that we will be discussing in this article.
‘Machine Learning’ term in this article means both – ‘Machine Learning’ and ‘Deep Learning’.
Difference between a Traditional Approach and Machine Learning Approach
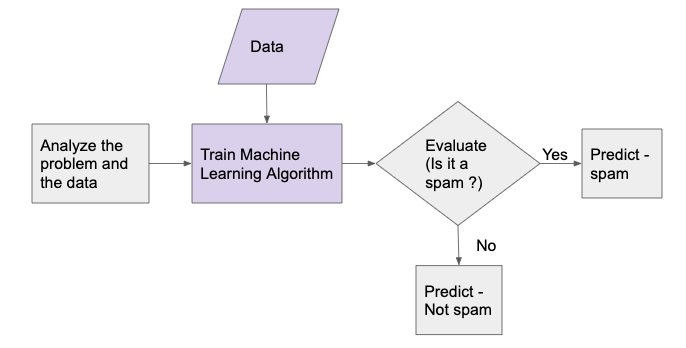
The below diagrams show the difference between the ‘traditional’ and ‘Machine Learning’ approaches for building a spam filter for emails.
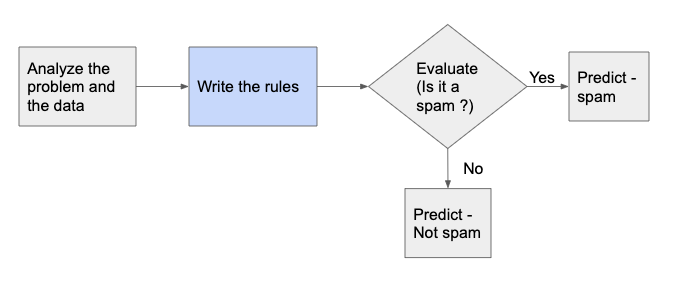
Traditional approach uses the rules (written by developer) to segregate spam and non-spam emails. The system doesn’t have the capability to generate dynamically these rules based on the data.
Whereas the Machine Learning approach uses the ML model (which contains rules generated dynamically by machine/computer based on input data) to segregate the spam and non-spam emails.
Project Initiation
When we are starting a project, it is very important that all the stakeholders are aligned and are on same page in terms of understanding of the project objectives and expectations from the project.
Few of the important questions, to ask at this stage are –
-
-
- Do all stakeholders understand the very nature of Machine Learning (or Deep Learning) process and projects ?
- Do all stakeholders have the same understanding of definitions of various ML performance metrics like – Accuracy, Precision, F1 Score, etc. ?
- Is the acceptance criteria well defined (quantitatively) ?
-
For successful completion of a Machine Learning project, the answers for all the above questions should be – yes.
We need to have good understanding of the business case and ask right questions to the stakeholders to
-
-
- choose right ‘target’ dataset (list of features)
- choose right performance metrics(accuracy, precision, etc.)
- decide the trade-offs
-
In acceptance criteria, the target metrics values should be a range (instead of a fixed value).
You may like to consider the below additional non-functional requirements (NFRs) for a Machine Learning project, along with the performance measures (like accuracy, precision, etc.):
-
-
- Model training and prediction time
- Frequency of refreshing (updating) the model in production
-
We must also be aware of the performance of the existing system, so that we can rightly access the challenges ahead in achieving the NFRs for the current project.
For example, the acceptance criteria may be defined as – we need to achieve 5% improvement in accuracy for the ML model. If the accuracy of the existing ML model (say Random Forest) is 85%, then, to improve the accuracy further, either, we may choose a different ML algorithm, or, we may decide to go for one of the Deep Neural Networks (DNN) for the current project.
It would also be good idea to know, what has not worked in the past (lessons learnt), so that we can avoid trying the same approach/algorithm/model in the current project.
Building ML Project Team
Below are the roles (and responsibilities) which are required for a typical Machine Learning project. Some roles may be removed or added depending on the size of the project.
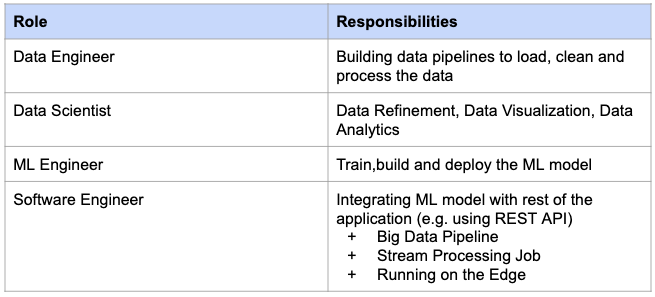
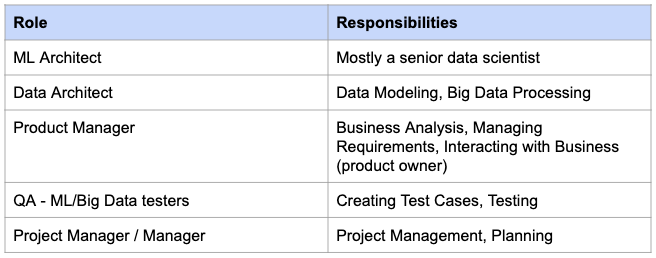
Some companies may have Engineering Manager / Technical Project Manager role instead of Project Manager role.
Engineering Manager / Technical Project Manager has both – Management as well as Technical – responsibilities.
Testing in Machine Learning Projects
Unlike traditional projects, Machine Learning projects don’t have fixed target values against which the model is tested.
The predicted (performance metrics) values in Machine Learning are generally not fixed, but have a range instead, hence, we test the model (and compare the performance metrics values) against a range instead of a fixed value.
The testers should have at least basic knowledge of Statistics and Machine Learning, and, they should know how to execute a data pipeline.
Factors Impacting Estimation and Cost
Data Quality
Data quality includes, data format, incomplete data (missing values), noise (erroneous data), unscaled data, etc.
Poor data quality may increase cost of Data Engineering (data cleaning, data analysis and visualization, etc.) and cost of model maintenance in production.
Data Volume
Large dataset may need Big Data processing and infrastructure (say Spark cluster, high end GPUs, etc.), which may need a Big Data team setup. Also, it may increase ML model training effort.
Small (insufficient) dataset may increase data collection effort (like web crawling, data augmentation, etc.)
Data Sourcing
Sourcing data from multiple sources may increase the effort, as different sources may require us to connect to and setup different interfaces which may be time consuming process.
Also, multiple data sources may require Master Data Management kind of setup.
Machine Learning Algorithm
The selection of ML algorithm may have impact on model training and fine-tuning time (hyperparameter tuning).
For example, XGBoost and CNN are highly computation intensive algorithms, and need more time to train and fine-tune the model.
With some of these kind of highly computation intensive algorithms, we may need to use say a Spark cluster or high end GPUs, etc.
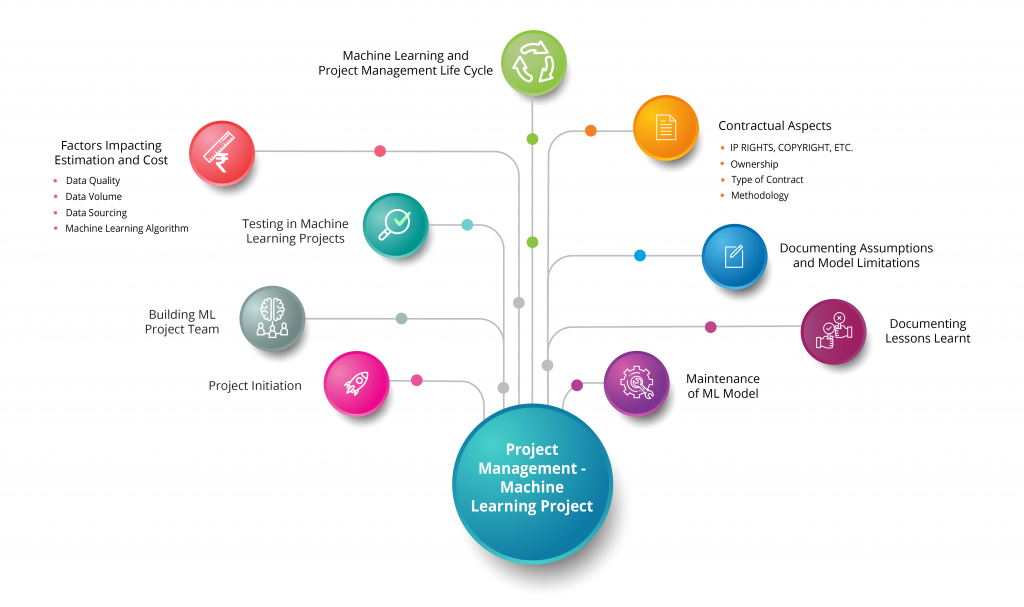
Machine Learning and Project Management Life Cycle
Below is diagram showing relationship between a ‘Machine Learning Development Life Cycle’ and ‘Project Management Life Cycle’.
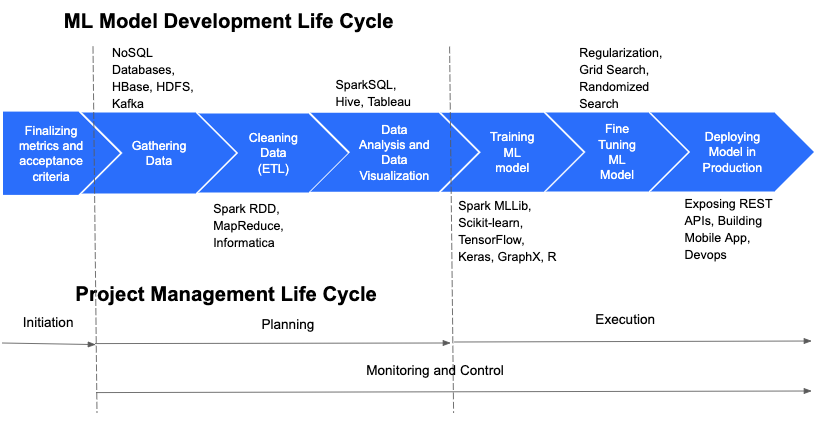
The processes (steps) in a ‘Machine Learning Development Life Cycle’ above are shown as sequential, just for ease of understanding. In real projects, some of these tasks may be executed in parallel, and there may be loops (iterations) involved.
For example, REST API creation, mobile app creation and ML model training can be executed in parallel. Depending upon the your requirement, some other tasks may also be fast tracked.
Also, there may be feedback loops (iterations) going back from ML model training phase to the data gathering phase, for the reasons like, if the ML model is overfitting, more input data may be required, or, model may need to be retrained on fresh dataset.
Contractual Aspects
There are few things that we need to keep in mind while creating contractual documents for AI/ML projects, these are as below:
IP rights, copyright, etc.
Definitions of the terms like patent, copyright, IP rights, etc. are undergoing change in light of AI/ML, because of their complex nature (e.g. model = code/algorithm + data). Hence, we should use these words carefully while documenting the contract.
Ownership
There are normally four things involved in any ML/AI project:
-
-
- Data
- ML algorithm
- Code (software) which transforms the data (cleaning, formatting, applying some statistical functions, etc.) and feeds it to the ML algorithm to make predictions.
- Pre-trained ML model reused to create your own ML model (especially in case of Neural Networks).
-
There are always questions around ownership of these four things.
For example,
-
-
- After transforming the data, who owns the data ? The person who created it originally, or, the person who transformed it ?
- If you tweaked the existing ML algorithm (originally created by someone else) little before using it, then, who owns this modified ML algorithm ?
- Who owns the final ML model, which consists of the transformed data, modified ML algorithm, a pre-trained ML model ?
-
Your contractual documents must answer the above questions, and, clearly define the ownership of pieces involved in creating a ML model.
Type of contract
While deciding the type of contract – fixed price, T&M, etc. – we should keep in mind that creation of ML model is a continuous and iterative process and may also involve lot of experimentation and trials (for fine-tuning the model). A model once deployed in production may get updated (retrained and deployed) multiple times, say due to stale data or spamming issues.
Methodology
Because of iterative nature, Agile or Iterative approach may be well suited for a AI/ML project.
Documenting Assumptions and Model Limitations
We need to document the assumptions made and the ML model limitations, so that we have realistic expectations from the performance of the ML model.
For example, suppose, we developed a SVM model for a problem, on a small input dataset, with an ‘assumption’ that in future too we will be getting smaller datasets. And, we already were aware of the ‘limitation’ of SVM, that it works best on smaller datasets, and is very slow on larger datasets.
Now, suppose, the SVM model’s performance degraded, say, due to stale data, and you want to retrain your model on the fresh dataset. If your fresh dataset is a large one, then you have two choices – either you compromise with model training time and use SVM only, or, you choose another ML algorithm to train which takes lesser time on larger datasets.
If all the stakeholders of this project were already made aware of this assumption (smaller dataset) and limitation (SVM slower on large datasets) in the beginning of the project, any possible conflicts (arising due to increase in model training time or change in ML model) at this stage can be easily avoided.
Documenting Lessons Learnt
Generally, ML model creation (and finalization) process involves a lot of experimentation and trials, hence, it is quite time consuming and tedious process.
Due to this, it is very important to document which experiments worked and which ones not, so that we could save effort in future by avoiding the things that didn’t work for a similar problem in the past.
Maintenance of ML Model
It is very important to monitor the performance of deployed ML model in production, which may get degraded, due to say – stale data issue, spamming, sensor malfunctioning, etc.
Poor performance of the model may necessitate retraining of the model (on fresh dataset) and re-deployment of the same in production at regular intervals.
Automating the process of training and deploying the ML model (in production) may also be good idea, to reduce the effort required for the same.
For the complete course, please visit AI for Managers