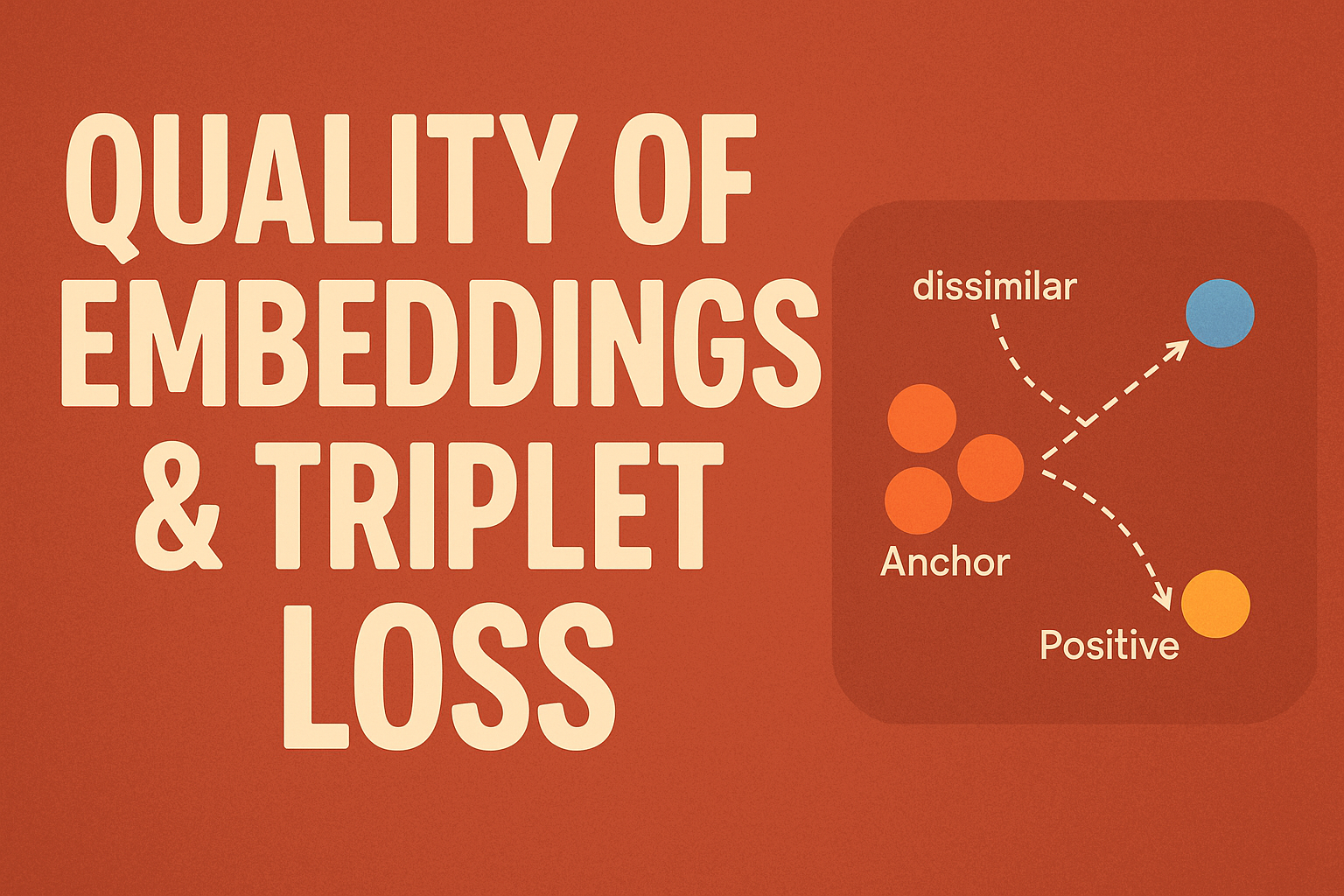
In Natural Language Processing (NLP), embeddings transform human language into numerical vectors. These are usually arrays of multiple dimensions & have schematic meaning based on their previous training text corpus The quality of these embeddings directly affects the performance of search engines, recommendation systems, chatbots, and more.
But here’s the problem:
Not all embeddings are created equal.
So how do we measure their quality?
To Identify the quality of embeddings i conducted one experiment:
I took 3 leading (Free) Text → Embedding pretrained models which worked differently & provided a set of triplets and found the triplets loss to compare the contextual importance of each one.
Mental health care is an essential component of overall well-being, yet it remains one of the most underserved areas of medicine. The stigma surrounding mental health issues, coupled with limited access to qualified professionals, has created barriers to effective care for millions worldwide. AI-powered chatbots are emerging as a promising solution to bridge these gaps, providing accessible, scalable, and cost-effective mental health support. This blog explores how these innovative tools revolutionize mental health care, their challenges, and their potential future impact.
History of AI in Mental Health Care
The integration of artificial intelligence into mental health care has a rich and evolving history. The journey began in the mid-20th century with the development of early AI programs designed to simulate human conversation. One of the earliest examples was ELIZA, created in the 1960s by computer scientist Joseph Weizenbaum. ELIZA was a rudimentary chatbot that used pattern matching and substitution methodology to simulate a psychotherapist’s responses. While basic by today’s standards, ELIZA demonstrated the potential of conversational AI in providing mental health support.
The field of natural language processing has witnessed remarkable advancements over the years, with the development of cutting-edge language models such as GPT-3 and the recent release of GPT-4. These models have revolutionized the way we interact with language and have opened up new possibilities for applications in various domains, including chatbots, virtual assistants, and automated content creation.
What is GPT?
GPT is a natural language processing (NLP) model developed by OpenAI that utilizes the transformer model. Transformer is a type of Deep Learning model, best known for its ability to process sequential data, such as text, by attending to different parts of the input sequence and using this information to generate context-aware representations of the text.
What makes transformers special is that they can understand the meaning of the text, instead of just recognizing patterns in the words. They can do this by “attending” to different parts of the text and figuring out which parts are most important to understanding the meaning of the whole.
For example, imagine you’re reading a book and come across the sentence “The cat sat on the mat.” A transformer would be able to understand that this sentence is about a cat and a mat and that the cat is sitting on the mat. It would also be able to use this understanding to generate new sentences that are related to the original one.
GPT is pre-trained on a large dataset, which consists of:
If you work in the banking industry, learning about data science, machine learning, and AI could be a valuable investment in your career. These fields are rapidly growing and are expected to play an increasingly important role in the banking industry in the coming years.
Here are a few reasons why learning about data science, machine learning, and AI could be beneficial for individuals in the banking industry:
These Machine Learning Interview Questions, are the real questions that are asked in the top interviews.
For hiring machine learning engineers or data scientists, the typical process has multiple rounds.
A basic screening round – The objective is to check the minimum fitness in this round.
Algorithm Design Round – Some companies have this round but most don’t. This involves checking the coding / algorithmic skills of the interviewee.
ML Case Study – In this round, you are given a case study problem of machine learning on the lines of Kaggle. You have to solve it in an hour.
Bar Raiser / Hiring Manager – This interview is generally with the most senior person in the team or a very senior person from another team (at Amazon it is called Bar raiser round) who will check if the candidate fits in the company-wide technical capabilities. This is generally the last round.
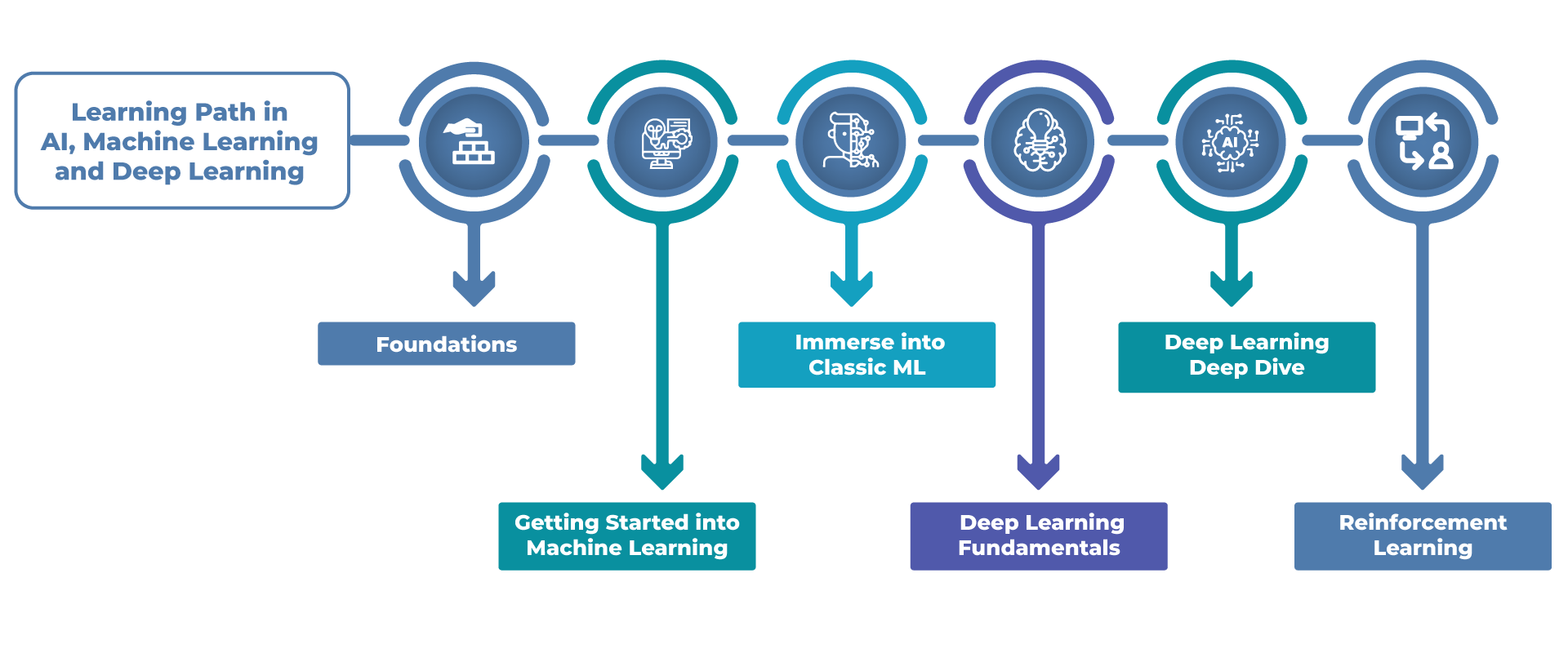
As of today, the hottest jobs in the industry are around AI, Machine Learning and Deep Learning. Let me try to outline the learning path for you in machine learning for the job profiles such as Data Scientist, Machine Learning Engineer, AI Engineer or ML Researcher.
AI basically means Artificial Intelligence – Making machines behave like an intelligent being. AI is defined around its purpose. To achieve AI, we use various hardware and software. In software, we basically use two kinds of approaches: Rule-Based and Machine Learning based.
In the rule-based approach, the logic is coded by people by understanding the problem statement. In the machine learning approach, the logic is inferred using the data or experience.
There are various algorithms or approaches that are part of the machine learning such as linear regression (fitting a line), Support vector machines, decision trees, random forest, ensemble learning and artificial neural networks etc.
The artificial neural network-based algorithms have proven very effective in recent years. The area of machine learning that deals with a complex neural network is called Deep Learning.
As part of this post, I want to help you plan your learning path in Machine Learning.
If you are looking for a non-mathematical and light on coding approach, please go through the course on “AI for Managers“. It is a very carefully curated and a very unique course that deals with AI and Machine Learning for those who are looking for a less mathematical approach.
If you are planning to become the Data Scientist, Machine Learning Engineer or Machine Learning Researcher, please follow this learning path. This learning path is also covered completely in our Certification Course on Machine Learning Specialization
Backpropagation is considered one of the core algorithms in Machine Learning. It is mainly used in training the neural network. And backpropagation is basically gradient descent. What if we tell you that understanding and implementing it is not that hard? Anyone who knows basic Mathematics and has knowledge of the basics of Python Language can learn this in 2 hours. Let’s get started.
Though there are many high-level overviews of the backpropagation and gradient descent algorithms what I found is that unless one implements these from scratch, one is not able to understand many ideas behind neural networks.
Recently, I came up with an idea for a new Optimizer (an algorithm for training neural network). In theory, it looked great but when I implemented it and tested it, it didn’t turn out to be good.
Some of my learning are:
Neural Networks are hard to predict.
Figuring out how to customize TensorFlow is hard because the main documentation is messy.
Theory and Practical are two different things. The more hands-on you are, the higher are your chances of trying out an idea and thus iterating faster.
I am sharing my algorithm here. Even though this algorithm may not be of much use to you but it would give you ideas on how to implement your own optimizer using Tensorflow Keras.
A neural network is basically a set of neurons connected to input and output. We need to adjust the connection strengths such that it gives the least error for a given set of input. To adjust the weight we use the algorithms. One brute force algorithm could be to try all possible combinations of weights (connections strength) but that will be too time-consuming. So, we usually use the greedy algorithm most of these are variants of Gradient Descent. In this article, we will write our custom algorithm to train a neural network. In other words, we will learn how to write our own custom optimizer using TensorFlow Keras.
GPT-3 is the largest NLP model till date. It has 175 billion parameters and has been trained with 45TB of data. The applications of this model are immense.
GPT3 is out in private beta and has been buzzing in social media lately. GPT3 has been made by Open AI, which was founded by Elon Musk, Sam Altman and others in 2015. Generative Pre-trained Transformer 3 (GPT3) is a gigantic model with 175 billion parameters. In comparison the previous version GPT2 had 1.5 billion parameters. The larger more complex model enables GPT3 to do things that weren’t previously possible.
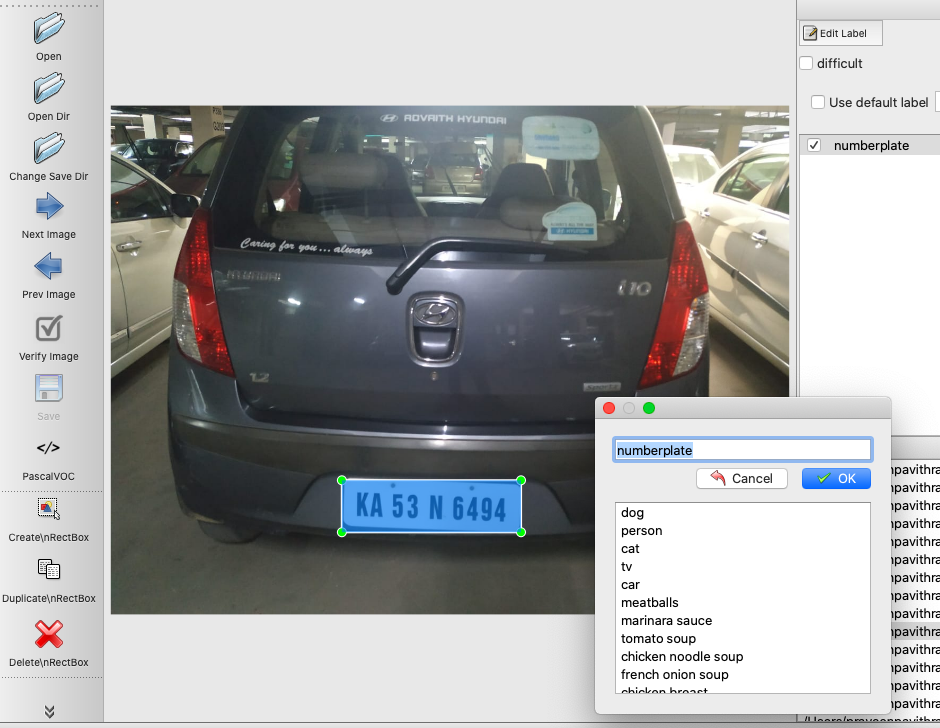
In this duology of blogs, we will explore how to create a custom number plate reader.
In this duology of blogs, we will explore how to create a custom number plate reader. We will use a few machine learning tools to build the detector. An automatic number plate detector has multiple applications in traffic control, traffic violation detection, parking management etc. We will use the number plate detector as an exercise to try features in OpenCV, tensorflow object detection API, OCR, pytesseract