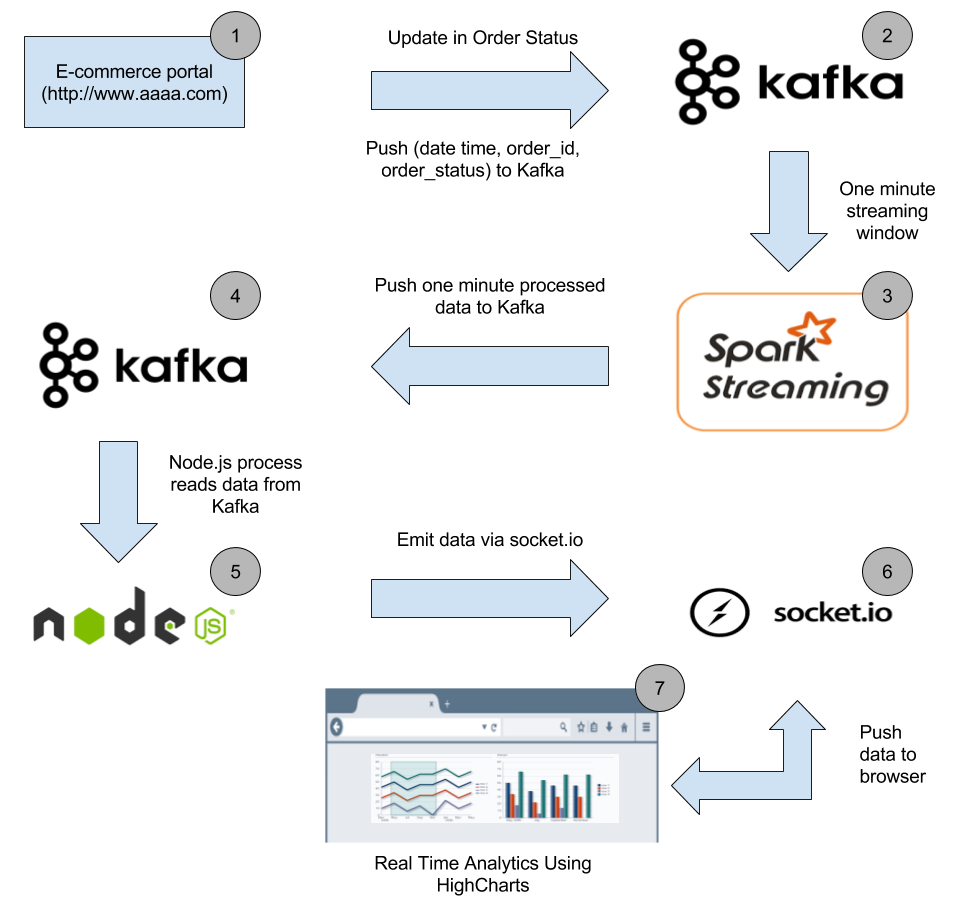
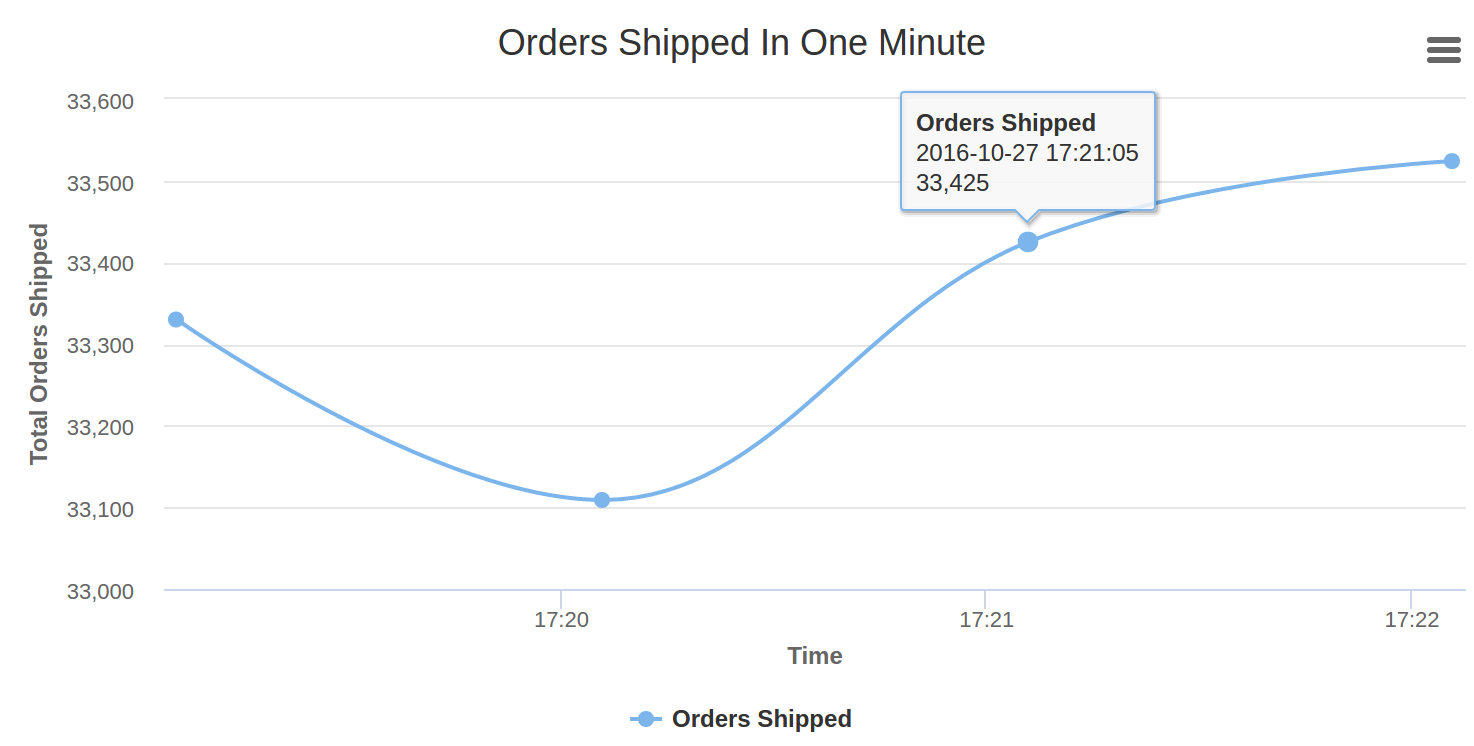
The supply chain is the backbone of global commerce, connecting manufacturers, suppliers, distributors, and consumers. However, traditional supply chain models are under increasing pressure to become more sustainable, efficient, and resilient in response to environmental challenges, consumer demands, and economic disruptions. Artificial Intelligence (AI) is emerging as a game-changer, revolutionizing supply chains to meet these demands while fostering sustainability.
The Challenges with Traditional Supply Chains
Traditional supply chains face significant challenges in achieving sustainability and efficiency due to:
- Inefficient Resource Utilization: Overproduction, waste, and under utilization of resources increase environmental footprints.
- Limited Visibility: Lack of end-to-end transparency makes it difficult to identify inefficiencies or environmental impacts.
- Demand Uncertainty: Fluctuating consumer demands lead to inventory mismatches and wastage.
- Complex Logistics: Managing global supply chains with multiple stakeholders is prone to errors and delays.
- Environmental Regulations: Increasingly stringent policies demand green practices and accountability.
These challenges necessitate innovative approaches, and AI is stepping in to transform supply chains into sustainable and efficient ecosystems.