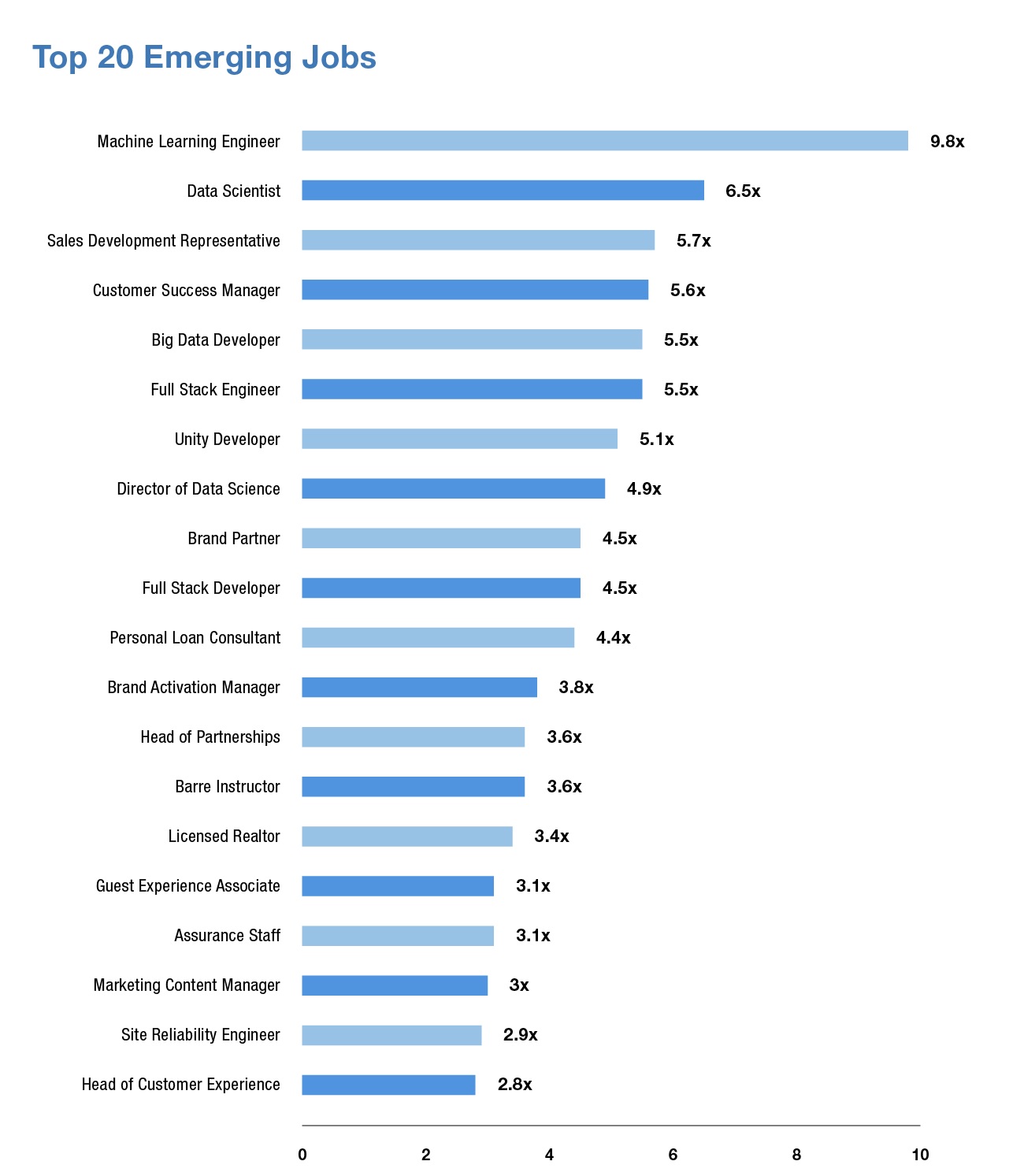
In the telecom industry, the use of AI and data science is becoming increasingly important for companies that want to stay competitive and deliver the best possible services to their customers.
Only by leveraging the power of AI and data science, telecom companies can gain valuable insights into their operations and make data-driven decisions that can help them improve efficiency, reduce costs, and develop new products and services.
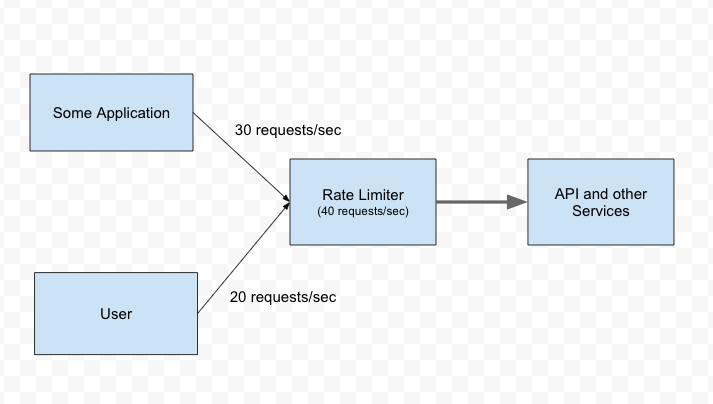
One key area where AI and data science can help telecom companies is in network optimization. By analyzing vast amounts of data from network sensors and other sources, AI algorithms can identify patterns and anomalies that can indicate where the network is underperforming or prone to failure. This can help telecom companies take proactive steps to improve network reliability and reduce downtime, leading to a better overall customer experience.
Continue reading “I’m from the telecom industry, should I learn Data Science and AI?”