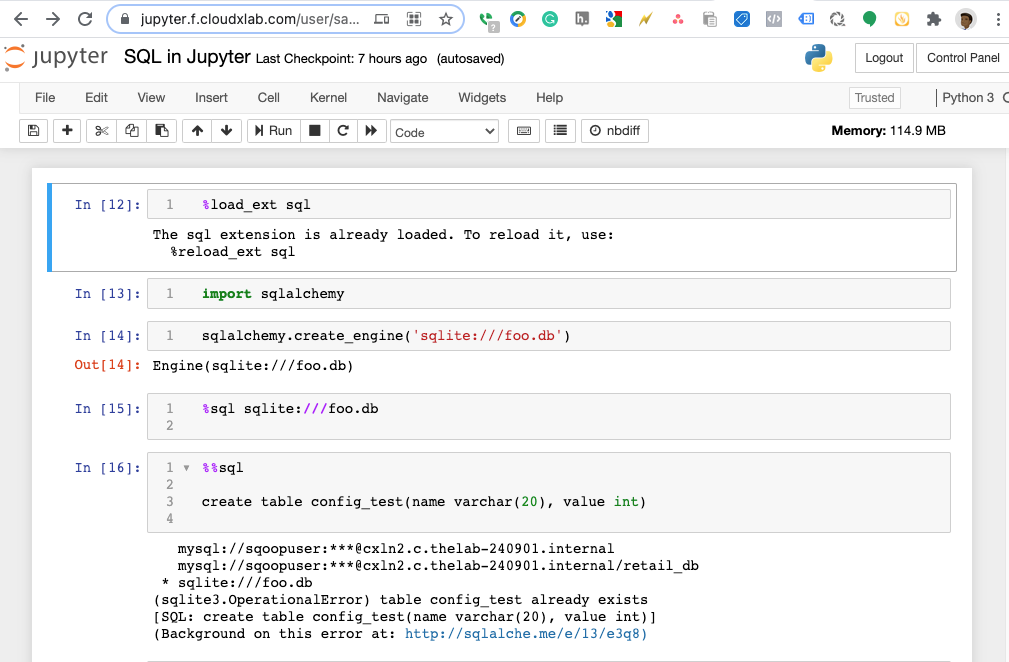
SQL is a very important skill. You not only can access the relational databases but also big data using Hive, Spark-SQL etcetera. Learning SQL could help you excel in various roles such as Business Analytics, Web Developer, Mobile Developer, Data Engineer, Data Scientist, and Data Analyst. Therefore having access to SQL client is very important via browser. In this blog, we are going to walk through the examples of interacting with SQLite and MySQL using Jupyter notebook.
A Jupyter notebook is a great tool for analytics and interactive computing. You can interact with various tools such as Python, Linux, File System, Scala, Lua, Spark, R, and SQL from the comfort of the browser. For almost every interactive tool, there is a kernel in Jupyter. Let us walk through how would you use SQL to interact with various databases from the comfort of your browser.
When you are building a production system whether it’s a machine learning model deployment or simple data cleaning, you would need to run multiple steps with multiple different tools and you would want to trigger some processes periodically. This is not possible to do it manually more than once. Therefore, you need a workflow manager and a scheduler. In workflow manager, you would define which processes to run and their interdependencies and in scheduler, you would want to execute them at a certain schedule.
When I started using Apache Hadoop in 2012, we used to get the HDFS data cleaned using our multiple streaming jobs written in Python, and then there were shell scripts and so on. It was cumbersome to run these manually. So, we started using Azkaban for the same, and later on Oozie came. Honestly, Oozie was less than impressive but it stayed due to the lack of alternatives.
As of today, Apache Airflow seems to be the best solution for creating your workflow. Unlike Oozie, Airflow is not really specific to Hadoop. It is an independent tool – more like a combination of Apache Ant and Unix Cron jobs. It has many more integrations. Check out Apache Airflow’s website.
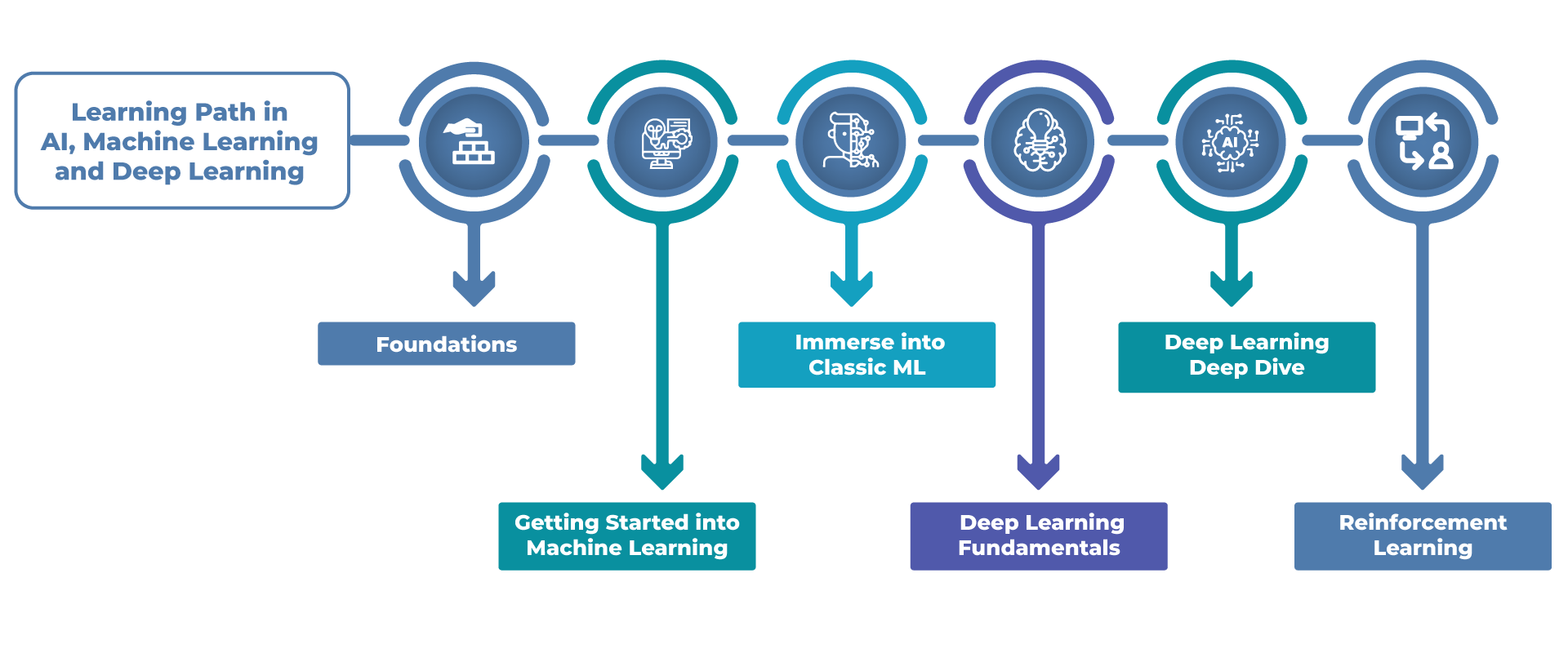
As of today, the hottest jobs in the industry are around AI, Machine Learning and Deep Learning. Let me try to outline the learning path for you in machine learning for the job profiles such as Data Scientist, Machine Learning Engineer, AI Engineer or ML Researcher.
AI basically means Artificial Intelligence – Making machines behave like an intelligent being. AI is defined around its purpose. To achieve AI, we use various hardware and software. In software, we basically use two kinds of approaches: Rule-Based and Machine Learning based.
In the rule-based approach, the logic is coded by people by understanding the problem statement. In the machine learning approach, the logic is inferred using the data or experience.
There are various algorithms or approaches that are part of the machine learning such as linear regression (fitting a line), Support vector machines, decision trees, random forest, ensemble learning and artificial neural networks etc.
The artificial neural network-based algorithms have proven very effective in recent years. The area of machine learning that deals with a complex neural network is called Deep Learning.
As part of this post, I want to help you plan your learning path in Machine Learning.
If you are looking for a non-mathematical and light on coding approach, please go through the course on “AI for Managers“. It is a very carefully curated and a very unique course that deals with AI and Machine Learning for those who are looking for a less mathematical approach.
If you are planning to become the Data Scientist, Machine Learning Engineer or Machine Learning Researcher, please follow this learning path. This learning path is also covered completely in our Certification Course on Machine Learning Specialization
Backpropagation is considered one of the core algorithms in Machine Learning. It is mainly used in training the neural network. And backpropagation is basically gradient descent. What if we tell you that understanding and implementing it is not that hard? Anyone who knows basic Mathematics and has knowledge of the basics of Python Language can learn this in 2 hours. Let’s get started.
Though there are many high-level overviews of the backpropagation and gradient descent algorithms what I found is that unless one implements these from scratch, one is not able to understand many ideas behind neural networks.
Recently, I came up with an idea for a new Optimizer (an algorithm for training neural network). In theory, it looked great but when I implemented it and tested it, it didn’t turn out to be good.
Some of my learning are:
Neural Networks are hard to predict.
Figuring out how to customize TensorFlow is hard because the main documentation is messy.
Theory and Practical are two different things. The more hands-on you are, the higher are your chances of trying out an idea and thus iterating faster.
I am sharing my algorithm here. Even though this algorithm may not be of much use to you but it would give you ideas on how to implement your own optimizer using Tensorflow Keras.
A neural network is basically a set of neurons connected to input and output. We need to adjust the connection strengths such that it gives the least error for a given set of input. To adjust the weight we use the algorithms. One brute force algorithm could be to try all possible combinations of weights (connections strength) but that will be too time-consuming. So, we usually use the greedy algorithm most of these are variants of Gradient Descent. In this article, we will write our custom algorithm to train a neural network. In other words, we will learn how to write our own custom optimizer using TensorFlow Keras.
In your Jupyter notebook, please follow the instructions given below. To avoid installations of Jupyter or any library, you can simply use CloudxLab – it gives 15 days free subscription.
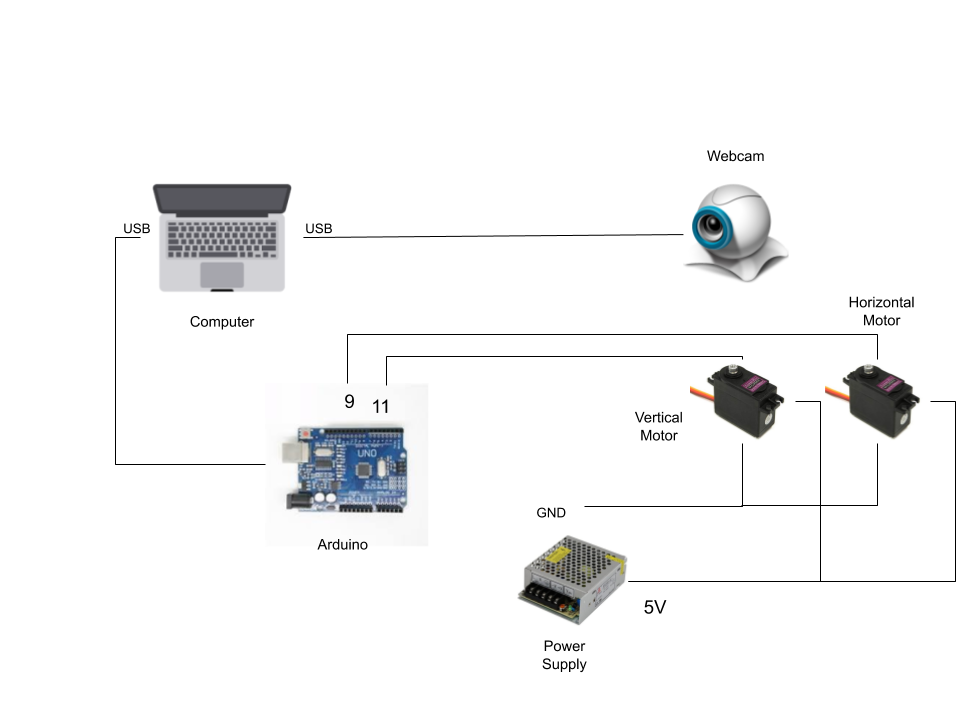
Whenever we have our live talks of CloudxLab, in presentations or in a conference, we want to live stream and record it. The main challenge that occurs is the presenter gets out of focus as the presenter moves. And for us, hiring a cameraman for three hours of a session is not a viable option. So, we thought of creating an AI-based pan and tilt platform which will keep the camera focussed on speaker.
So, Here are the step-by-step instructions to create such a camera along with the code needed.
As part of this blog post, I am going to walk you through how an Artificial Neural Network figures out a complex relationship in data by itself without much of our hand-holding. You should modify the data generation function and observe if it is able to predict the result correctly. I am going to use the Keras API of TensorFlow. Keras API makes it really easy to create Deep Learning models.
Machine learning is about computer figuring out relationships in data by itself as opposed to programmers figuring out and writing code/rules. Machine learning generally is categorized into two types: Supervised and Unsupervised. In supervised, we have the supervision available. And supervised learning is further classified into Regression and Classification. In classification, we have training data with features and labels and the machine should learn from this training data on how to label a record. In regression, the computer/machine should be able to predict a value – mostly numeric. An example of Regression is predicting the salary of a person based on various attributes: age, years of experience, the domain of expertise, gender.
The notebook having all the code is available here on GitHub as part of cloudxlab repository at the location deep_learning/tensorflow_keras_regression.ipynb . I am going to walk you through the code from this notebook here.
Generate Data: Here we are going to generate some data using our own function. This function is a non-linear function and a usual line fitting may not work for such a function
def myfunc(x):
if x < 30:
mult = 10
elif x < 60:
mult = 20
else:
mult = 50
return x*mult
Say you come up with a wonderful idea such as a really great phone service. You would want this phone service to be available to the APIs in various languages. Whether people are using Python, C++, Java or any other programming language, the users should be able to use your service. Also, you would want the users to be able to access globally. In such scenarios, you should create the Thrift Service. Thrift lets you create a generic interface which can be implemented on the server. The clients of this generic interface can be automatically generated in all kinds of languages.
Let us get started! Here we are going to create a very simple service that just prints the server time.
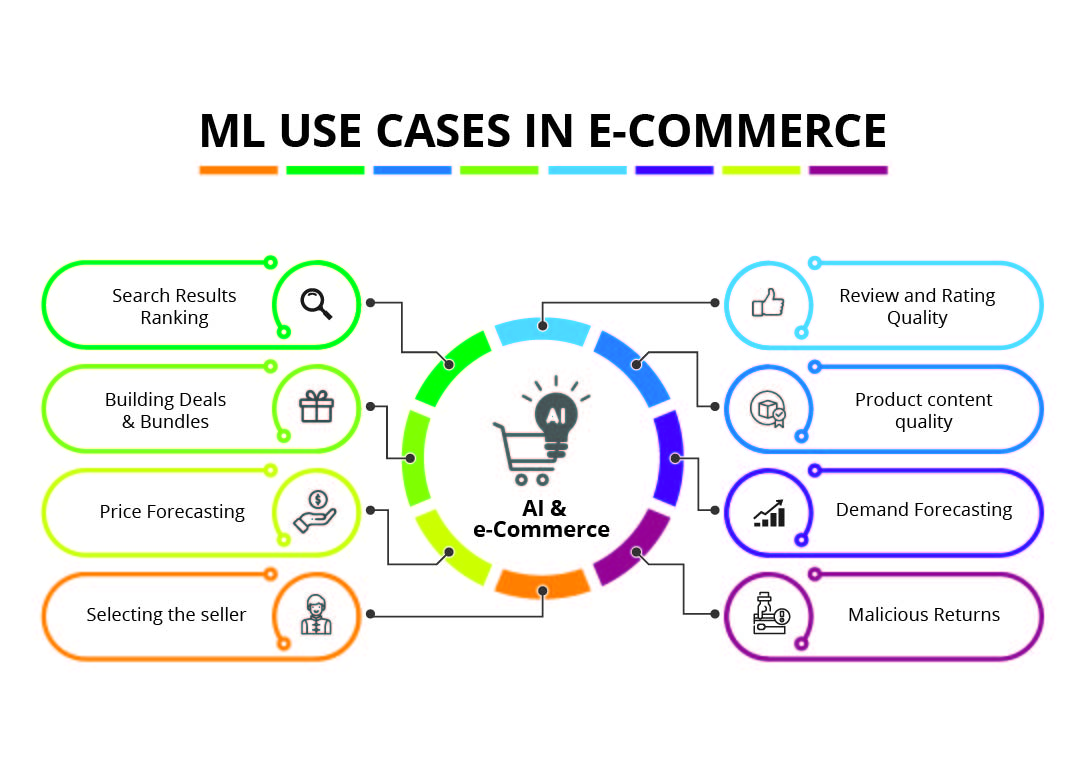
What computing did to the usual industry earlier, Machine Learning is doing the same to usual rule-based computing now. It is eating the market of the same. Earlier, in organizations, there used to be separate groups for Image Processing, Audio Processing, Analytics and Predictions. Now, these groups are merged because machine learning is basically overlapping with every domain of computing. Let us discuss how machine learning is impacting e-commerce in particular.
The first use case of Machine Learning that became really popular was Amazon Recommendations. Afterwards, the Netflix launched a challenge of Movie Recommendations which gave birth to Kaggle, now an online platform of various machine learning challenges.
Before I dive deep into the details further, lets quickly brief the terms that are found often confusing. AI stands for Artificial Intelligence which means being able to display human-like intelligence. AI is basically an objective. Machine learning is making computers learn based on historical or empirical data instead of explicitly writing the rules. Artificial Neural networks are the computing constructs designed on a similar structure like the animal brain. Deep Learning is a branch of machine learning where we use a complex Artificial Neural network for predictions.