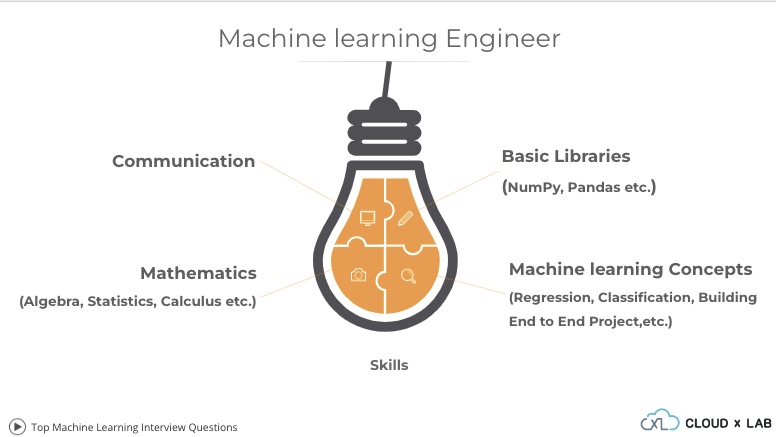
Machine Learning is the most rapidly growing domain in the software industry. More and more sectors are using concepts of Machine Learning to enhance their businesses. It is now not an add-on but has become a necessity for businesses to use ML algorithms for optimizing their businesses and to offer a personalised user experience.
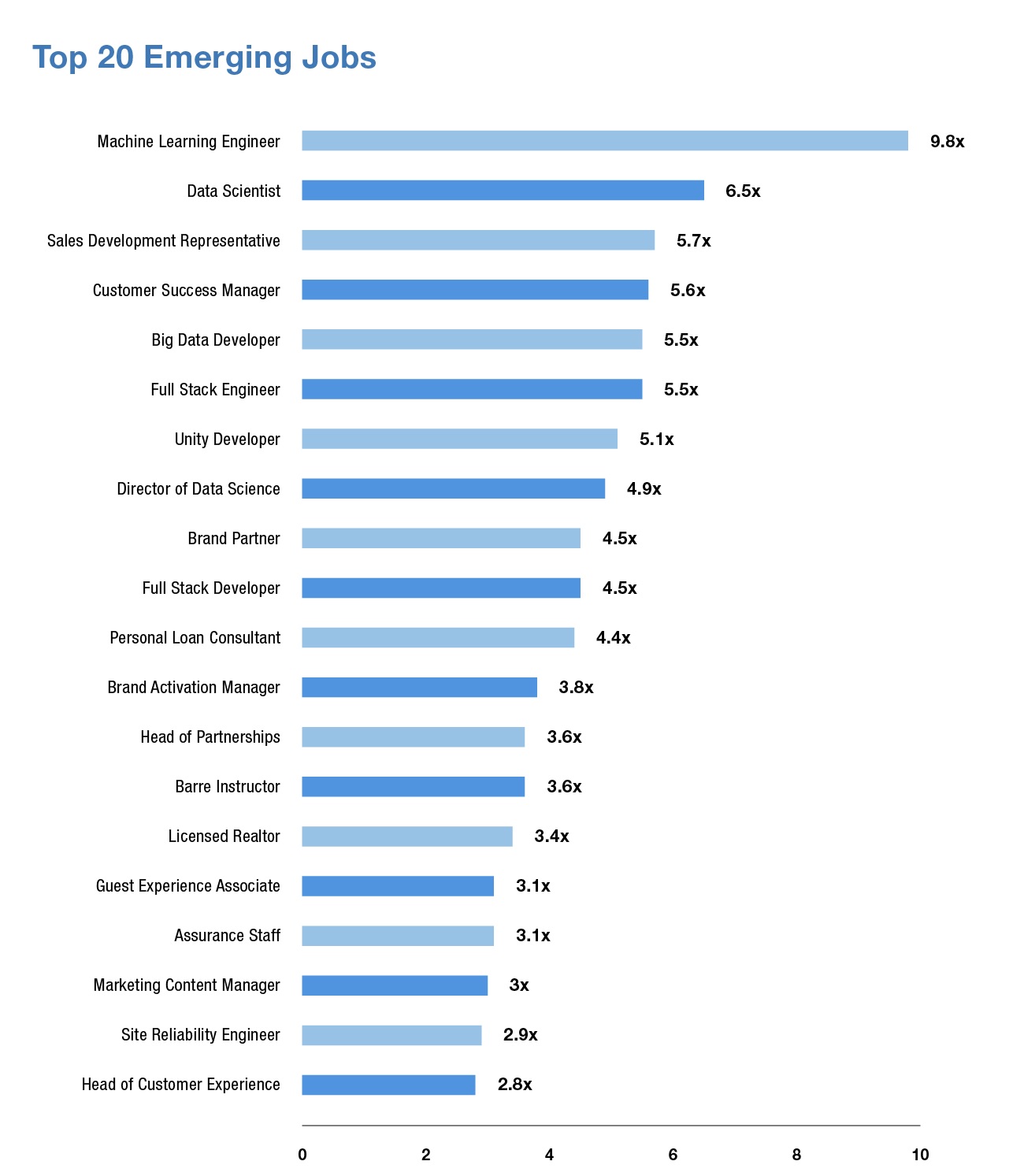
This demand for Machine Learning in the industry has directly increased the demand for Machine Learning Engineers, the ones who unload this magic in reality. According to a survey conducted by LinkedIn, Machine Learning Engineer is the most emerging job role in the current industry with nearly 10 times growth.
But, even this high demand doesn’t make getting a job in ML any easier. ML interviews are tough regardless of your seniority level. But as said, with the right knowledge and preparation, interviews become a lot easier to crack.
In this blog, I will walk you through the interview process for an ML job role and will pass on some tips and tactics on how to crack one. We will also discuss the skills required in accordance with each round of the process.
These Machine Learning Interview Questions, are the real questions that are asked in the top interviews.
For hiring machine learning engineers or data scientists, the typical process has multiple rounds.
A basic screening round – The objective is to check the minimum fitness in this round.
Algorithm Design Round – Some companies have this round but most don’t. This involves checking the coding / algorithmic skills of the interviewee.
ML Case Study – In this round, you are given a case study problem of machine learning on the lines of Kaggle. You have to solve it in an hour.
Bar Raiser / Hiring Manager – This interview is generally with the most senior person in the team or a very senior person from another team (at Amazon it is called Bar raiser round) who will check if the candidate fits in the company-wide technical capabilities. This is generally the last round.
During one of the keynote speeches in India, an elderly person asked a question: why don’t we use Sanskrit for coding in AI. Though this question might look very strange to researchers at first it has some deep background to it.
Long back when people were trying to build language translators, the main idea was to have an intermediate language to and from which we could translate to any language. If we build direct translation from a language A to B, there will be too many permutations. Imagine, we have 10 languages, and we will have to build 90 (10*9) such translators. But to come up with an intermediate language, we would just need to encode for every 10 languages and 10 decoders to convert the intermediate language to each language. Therefore, there will be only 20 models in total.
So, it was obvious that there is definitely a need for an intermediate language. The question was what should be the intermediate language. Some scientists proposed that we should have Sanskrit as the intermediate language because it had good definitive grammar. Some scientists thought a programming language that can dynamically be loaded should be better and they designed a programming language such as Lisp. Soon enough, they all realized that both natural languages and programming languages such as Lisp would not suffice for multiple reasons: First, there may not be enough words to represent each emotion in different languages. Second, all of this will have to be coded manually.
The approach that became successful was the one in which we represent the intermediate language as a list of numbers along with a bunch of numbers that represent the context. Also, instead of manually coding the meaning of each word, the idea that worked out was representing a word or a sentence with a bunch of numbers. This approach is fairly successful. This idea of representing words as a list of numbers has brought a revolution in natural language understanding. There is humongous research that is happening in this domain today. Please check GPT-3, Dall-E, and Imagen.
If you subtract woman from Queen and add Man, what should be the result? It should be King, right? This can be easily demonstrated using word embedding.
Queen — woman + man = King
Similarly, Emperor — man + woman = Empress
Yes, this works. Each of these words is represented by a list of numbers. So, we are truly able to represent the meaning of words with a bunch of numbers. If you think about it, we learned the meaning of each word in our mother tongue without using a dictionary. Instead, we figured the meaning out using the context.
In our mind, we have sort of a representation of the word which is definitely not in the form of some other natural language. Based on the same principles, the algorithms also figure out the meaning of the words in terms of a bunch of numbers. It is very interesting to understand how these algorithms work. They work on similar principles to humans. They go through the large corpus of data such as Wikipedia or news archives and figure out the numbers with which each word can be represented. The problem is optimization: come up with those numbers to represent each word such that the distance between the words existing in a similar context is very small as compared to the distance between the words existing in different contexts.
The word Cow is closer to Buffalo as compared to Cup because Cow and buffalo usually exist in similar contexts in sentences.
So, in summary, it is very unreasonable to pursue that we should still be considering a natural language to represent the meaning of a word or sentence.
I hope this makes sense to you. Please post your opinions in the comments.
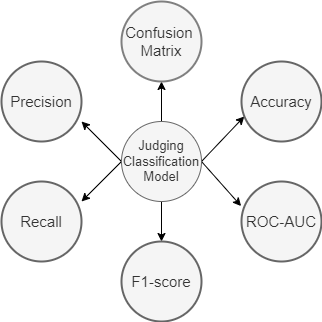
In this blog, we will discuss about commonly used classification metrics. We will be covering Accuracy Score, Confusion Matrix, Precision, Recall, F-Score, ROC-AUC and will then learn how to extend them to the multi-class classification. We will also discuss in which scenarios, which metric will be most suitable to use.
First let’s understand some important terms used throughout the blog-
True Positive (TP): When you predict an observation belongs to a class and it actually does belong to that class.
True Negative (TN): When you predict an observation does not belong to a class and it actually does not belong to that class.
False Positive (FP): When you predict an observation belongs to a class and it actually does not belong to that class.
False Negative(FN): When you predict an observation does not belong to a class and it actually does belong to that class.
All classification metrics work on these four terms. Let’s start understanding classification metrics-
The remaining useful life (RUL) is the length of time a machine is likely to operate before it requires repair or replacement. By taking RUL into account, engineers can schedule maintenance, optimize operating efficiency, and avoid unplanned downtime. For this reason, estimating RUL is a top priority in predictive maintenance programs.
Three are modeling solutions used for predicting the RUL which are mentioned below:
Regression: Predict the Remaining Useful Life (RUL), or Time to Failure (TTF).
Binary classification: Predict if an asset will fail within a certain time frame (e.g., Hours).
Multi-class classification: Predict if an asset will fail in different time windows: E.g., fails in window [1, w0] days; fails in the window [w0+1, w1] days; not fail within w1 days.
In this blog, I have covered binary classification and multi-class classification in the below sections.
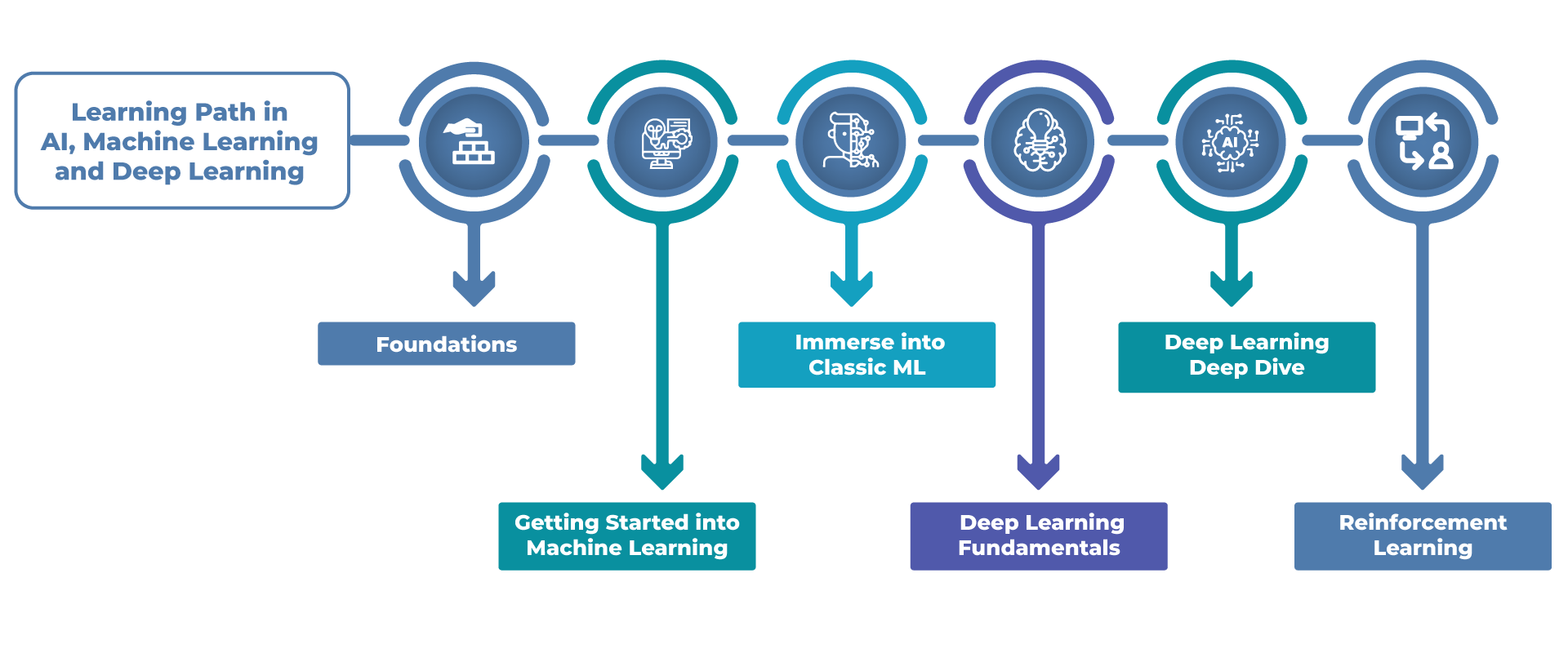
As of today, the hottest jobs in the industry are around AI, Machine Learning and Deep Learning. Let me try to outline the learning path for you in machine learning for the job profiles such as Data Scientist, Machine Learning Engineer, AI Engineer or ML Researcher.
AI basically means Artificial Intelligence – Making machines behave like an intelligent being. AI is defined around its purpose. To achieve AI, we use various hardware and software. In software, we basically use two kinds of approaches: Rule-Based and Machine Learning based.
In the rule-based approach, the logic is coded by people by understanding the problem statement. In the machine learning approach, the logic is inferred using the data or experience.
There are various algorithms or approaches that are part of the machine learning such as linear regression (fitting a line), Support vector machines, decision trees, random forest, ensemble learning and artificial neural networks etc.
The artificial neural network-based algorithms have proven very effective in recent years. The area of machine learning that deals with a complex neural network is called Deep Learning.
As part of this post, I want to help you plan your learning path in Machine Learning.
If you are looking for a non-mathematical and light on coding approach, please go through the course on “AI for Managers“. It is a very carefully curated and a very unique course that deals with AI and Machine Learning for those who are looking for a less mathematical approach.
If you are planning to become the Data Scientist, Machine Learning Engineer or Machine Learning Researcher, please follow this learning path. This learning path is also covered completely in our Certification Course on Machine Learning Specialization
If you are interested in Machine Learning or Deep Learning, but struggling to decide which book to use to study the same, here is a list of the best books in these fields. What makes this list even better is that some of these books are available online, for free! So go through the list, and pick the one that suits you best.
1. Deep Learning Book – by Aaron Courville, Ian Goodfellow, and Yoshua Bengio This book covers them all, including the mathematics required for Deep Learning. What’s more, it is available for free from the official website of this book. This is a must have for any serious Deep Learning practitioner.
Backpropagation is considered one of the core algorithms in Machine Learning. It is mainly used in training the neural network. And backpropagation is basically gradient descent. What if we tell you that understanding and implementing it is not that hard? Anyone who knows basic Mathematics and has knowledge of the basics of Python Language can learn this in 2 hours. Let’s get started.
Though there are many high-level overviews of the backpropagation and gradient descent algorithms what I found is that unless one implements these from scratch, one is not able to understand many ideas behind neural networks.
Recently, I came up with an idea for a new Optimizer (an algorithm for training neural network). In theory, it looked great but when I implemented it and tested it, it didn’t turn out to be good.
Some of my learning are:
Neural Networks are hard to predict.
Figuring out how to customize TensorFlow is hard because the main documentation is messy.
Theory and Practical are two different things. The more hands-on you are, the higher are your chances of trying out an idea and thus iterating faster.
I am sharing my algorithm here. Even though this algorithm may not be of much use to you but it would give you ideas on how to implement your own optimizer using Tensorflow Keras.
A neural network is basically a set of neurons connected to input and output. We need to adjust the connection strengths such that it gives the least error for a given set of input. To adjust the weight we use the algorithms. One brute force algorithm could be to try all possible combinations of weights (connections strength) but that will be too time-consuming. So, we usually use the greedy algorithm most of these are variants of Gradient Descent. In this article, we will write our custom algorithm to train a neural network. In other words, we will learn how to write our own custom optimizer using TensorFlow Keras.