The bucketing in Hive is a data-organising technique. It is used to decompose data into more manageable parts, known as buckets, which in result, improves the performance of the queries. It is similar to partitioning, but with an added functionality of hashing technique.
Introduction
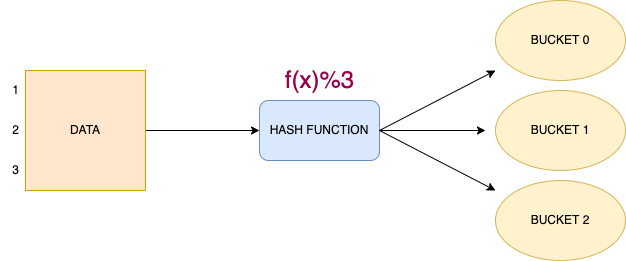
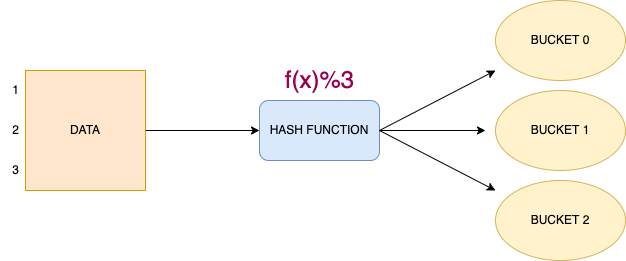
Bucketing, a.k.a clustering is a technique to decompose data into buckets. In bucketing, Hive splits the data into a fixed number of buckets, according to a hash function over some set of columns. Hive ensures that all rows that have the same hash will be stored in the same bucket. However, a single bucket may contain multiple such groups.
For example, bucketing the data in 3 buckets will look like-
These Machine Learning Interview Questions, are the real questions that are asked in the top interviews.
For hiring machine learning engineers or data scientists, the typical process has multiple rounds.
A basic screening round – The objective is to check the minimum fitness in this round.
Algorithm Design Round – Some companies have this round but most don’t. This involves checking the coding / algorithmic skills of the interviewee.
ML Case Study – In this round, you are given a case study problem of machine learning on the lines of Kaggle. You have to solve it in an hour.
Bar Raiser / Hiring Manager – This interview is generally with the most senior person in the team or a very senior person from another team (at Amazon it is called Bar raiser round) who will check if the candidate fits in the company-wide technical capabilities. This is generally the last round.
Today’s world is also known as the world of software with its builders known as Software Engineers. It’s on them that today we are interacting with each other because the webpage on which you are reading this blog, the web browser displaying this webpage, and the operating system to run the web browser are all made by a software engineer.
In today’s blog, we will start by introducing software engineering and will discuss its history, scope, and types. Then we will compare different types of software engineers on the basis of their demand in the industry. After that, we will discuss on full-stack developerjobrole and responsibilities and will also discuss key skills and the hiring process for a full-stack developer in detail.
During one of the keynote speeches in India, an elderly person asked a question: why don’t we use Sanskrit for coding in AI. Though this question might look very strange to researchers at first it has some deep background to it.
Long back when people were trying to build language translators, the main idea was to have an intermediate language to and from which we could translate to any language. If we build direct translation from a language A to B, there will be too many permutations. Imagine, we have 10 languages, and we will have to build 90 (10*9) such translators. But to come up with an intermediate language, we would just need to encode for every 10 languages and 10 decoders to convert the intermediate language to each language. Therefore, there will be only 20 models in total.
So, it was obvious that there is definitely a need for an intermediate language. The question was what should be the intermediate language. Some scientists proposed that we should have Sanskrit as the intermediate language because it had good definitive grammar. Some scientists thought a programming language that can dynamically be loaded should be better and they designed a programming language such as Lisp. Soon enough, they all realized that both natural languages and programming languages such as Lisp would not suffice for multiple reasons: First, there may not be enough words to represent each emotion in different languages. Second, all of this will have to be coded manually.
The approach that became successful was the one in which we represent the intermediate language as a list of numbers along with a bunch of numbers that represent the context. Also, instead of manually coding the meaning of each word, the idea that worked out was representing a word or a sentence with a bunch of numbers. This approach is fairly successful. This idea of representing words as a list of numbers has brought a revolution in natural language understanding. There is humongous research that is happening in this domain today. Please check GPT-3, Dall-E, and Imagen.
If you subtract woman from Queen and add Man, what should be the result? It should be King, right? This can be easily demonstrated using word embedding.
Queen — woman + man = King
Similarly, Emperor — man + woman = Empress
Yes, this works. Each of these words is represented by a list of numbers. So, we are truly able to represent the meaning of words with a bunch of numbers. If you think about it, we learned the meaning of each word in our mother tongue without using a dictionary. Instead, we figured the meaning out using the context.
In our mind, we have sort of a representation of the word which is definitely not in the form of some other natural language. Based on the same principles, the algorithms also figure out the meaning of the words in terms of a bunch of numbers. It is very interesting to understand how these algorithms work. They work on similar principles to humans. They go through the large corpus of data such as Wikipedia or news archives and figure out the numbers with which each word can be represented. The problem is optimization: come up with those numbers to represent each word such that the distance between the words existing in a similar context is very small as compared to the distance between the words existing in different contexts.
The word Cow is closer to Buffalo as compared to Cup because Cow and buffalo usually exist in similar contexts in sentences.
So, in summary, it is very unreasonable to pursue that we should still be considering a natural language to represent the meaning of a word or sentence.
I hope this makes sense to you. Please post your opinions in the comments.
The world in the future is complex, every aspect of services that we use will be AI based (most of them already are). The world of Data and AI. This thought often appears scary to our primitive brains and more so to people who see programming as Egyptian hieroglyphs but may I suggest an alternate approach to this view, instead of looking at how the technologies in the future are going to take away our job, we should learn to harness the power of AI and BIG DATA to be better equipped for the future.
At CloudxLab, We believe in providing Quality over Quantity and hence each one of our courses is highly rated by our learners, the love shown by our community has been tremendous and makes us strive for improvement, we strive to ensure that education does not feel like a luxury but a basic need that everybody is entitled to. Keeping this in mind, we bring forth the “#NoPayApril” where you can access some of the most sought after and industry-relevant courses completely free of cost. During #NoPayApril anybody who is signing up at CloudxLab will be able to access the contents of all the self-paced courses. This offer will be running from April 3 till April 30, 2022.
CloudxLab provides an online learning platform where you can learn and practice Data Science, Deep Learning, Machine Learning, Big Data, Python, etc.
When the highly competitive and commercialized education providers have cluttered the online learning platform, CloudxLab tries to break through with a disruptive change by making upskilling affordable and accessible and thus, achievable.
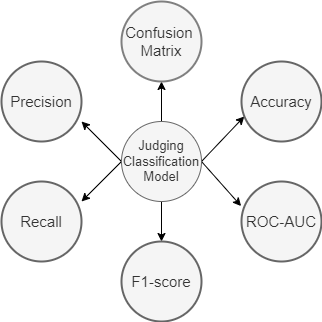
In this blog, we will discuss about commonly used classification metrics. We will be covering Accuracy Score, Confusion Matrix, Precision, Recall, F-Score, ROC-AUC and will then learn how to extend them to the multi-class classification. We will also discuss in which scenarios, which metric will be most suitable to use.
First let’s understand some important terms used throughout the blog-
True Positive (TP): When you predict an observation belongs to a class and it actually does belong to that class.
True Negative (TN): When you predict an observation does not belong to a class and it actually does not belong to that class.
False Positive (FP): When you predict an observation belongs to a class and it actually does not belong to that class.
False Negative(FN): When you predict an observation does not belong to a class and it actually does belong to that class.
All classification metrics work on these four terms. Let’s start understanding classification metrics-
The objective of this problem is to classify skin cancer detections, around 1.98% of people in the world are affected due to skin cancer and this would help the community diagnose it in early stages where there is limited clinical expertise.
This is a HAM10000 dataset containing 10012 images, classifying 7 types of cancer, and each instance has been resized to 64*64 RGB image for this problem, associated with label.
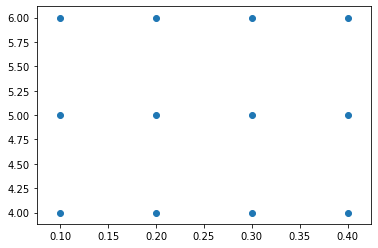
When you are generating data, the Meshgrid function of Numpy helps us to generate the coordinates data from individual arrays.
Say, you have a set of values of x 0.1, 0.2, 0.3, 0.4. You want to generate all possible points by combining these four values with say three values for y: 4, 5, 6.
This can be done very easily by using meshgrid function of Numpy as follows:
import numpy as np
x, y = np.meshgrid([0.1, 0.2, 0.3, 0.4], [4, 5, 6])
import matplotlib.pyplot as plt
plt.scatter(x, y)
Learn the basic concepts of DevOps. You will also learn the benefits of using DevOps practices in your application.
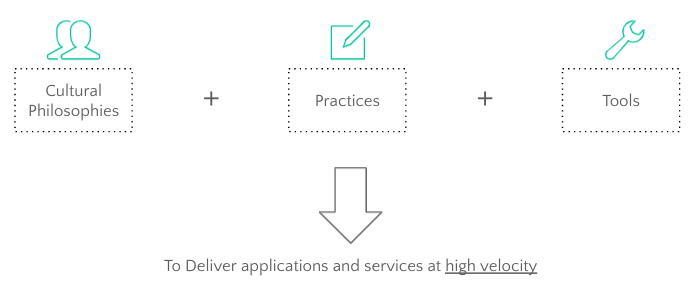
What is DevOps?
DevOps is essentially cultural philosophies, practices, and tools to help deliver your applications and services and tools to your huge number of users.
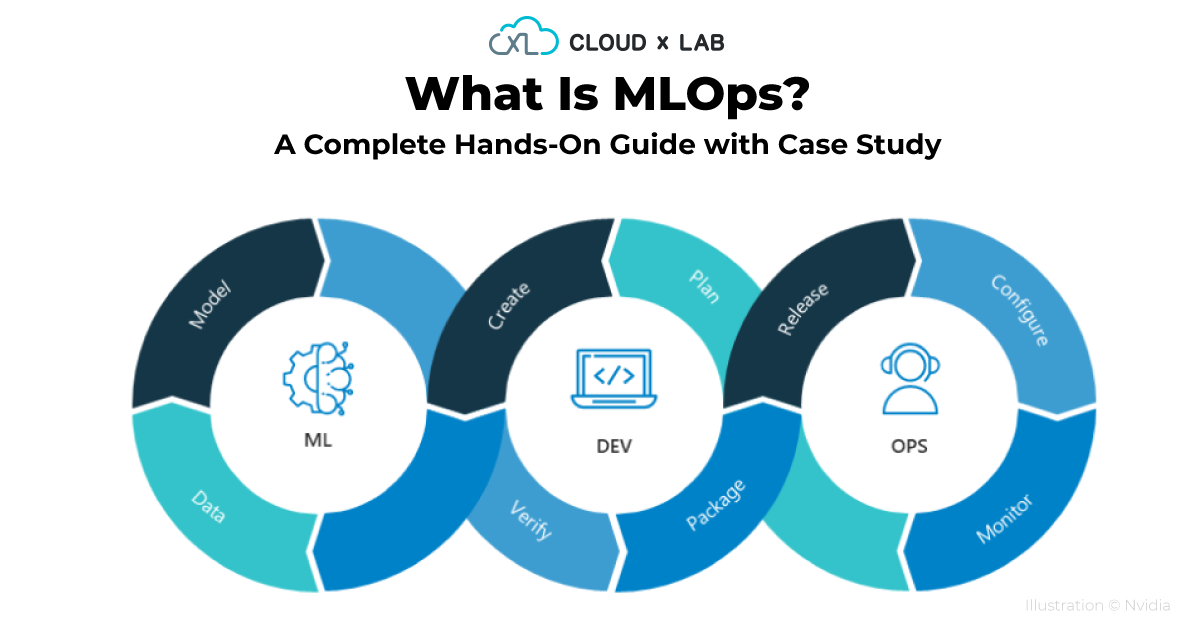
Learn about MLOps with a case study and guided projects. This will also cover DevOps, Software Engineering, System Engineering in the right proportions to ensure your understanding is complete.
You will learn about MLOps with a case study and guided projects. This will also cover DevOps, Software Engineering, System Engineering in the right proportions to ensure your understanding is complete.
Introduction
As part of this series of blogs, I want to help you understand MLOps. MLOps stands for Machine Learning Ops. It is basically a combination of Machine Learning, Software Development, and Operations. It is a vast topic. I want to first establish the value of MLOps and then discuss the various concepts to learn by way of guided projects in a very hands-on manner. If you are looking for a theoretical foundation on MLOps, please follow this documentation by Google.
Case Study
Objective
When I was working with an organization, we wanted to build and show the recommendation. The main idea was that we need to show something interesting to the users in a small ad space that people would want to use. Since we had the anonymized historical behavior of the users, we settled down to show recommendations of apps that they would also like based on their usage of various apps at the time when the ads were being displayed.