When you are generating data, the Meshgrid function of Numpy helps us to generate the coordinates data from individual arrays.
Say, you have a set of values of x 0.1, 0.2, 0.3, 0.4. You want to generate all possible points by combining these four values with say three values for y: 4, 5, 6.
This can be done very easily by using meshgrid function of Numpy as follows:
import numpy as np
x, y = np.meshgrid([0.1, 0.2, 0.3, 0.4], [4, 5, 6])
import matplotlib.pyplot as plt
plt.scatter(x, y)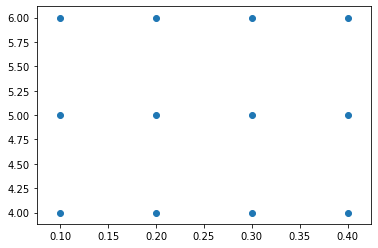
To learn more about it, please visit Numpy Meshgrid Reference