
As AI and other technologies continue to advance, it is likely that many jobs that are currently considered essential will become obsolete, while new job opportunities will emerge in areas related to AI and other emerging technologies.
Continue reading “Jobs that will emerge/stay relevant in the near future.”Category: Others
I’m from the banking industry, should I learn Data Science and AI

If you work in the banking industry, learning about data science, machine learning, and AI could be a valuable investment in your career. These fields are rapidly growing and are expected to play an increasingly important role in the banking industry in the coming years.
Here are a few reasons why learning about data science, machine learning, and AI could be beneficial for individuals in the banking industry:
Continue reading “I’m from the banking industry, should I learn Data Science and AI”10 Reasons to Start Learning Data Science and Artificial Intelligence Today

The world is changing at an unprecedented pace in technology. The demand for Data Science and Artificial Intelligence (AI) skills is growing faster than ever before. Whether you’re a recent graduate, a seasoned professional, or simply looking to upskill, now is the perfect time to hone your skills in these exciting fields.
If you want to innovate or solve complex problems, you must empower yourself with the right tools and technologies today. These technologies include Machine Learning, Artificial Intelligence, Deep Learning, ChatGPT, Stable Diffusion, Data Science, Data Engineering and so much more!
Here are ten reasons why you should consider investing in Data Science and AI/ML training today.
1. The Job Market is Booming
Data science and AI are among the fastest-growing fields, and the demand for professionals with these skills is expected to continue to rise. According to a recent study, the number of job postings for data scientists has increased by almost 75% over the past five years, and the demand for AI professionals is growing even faster.
Starting Machine Learning with an End-to-End Project
When you are learning about Machine Learning, it is best to experiment with real-world data alongside learning concepts. It is even more beneficial to start Machine Learning with a project including end-to-end model building, rather than going for conceptual knowledge first.
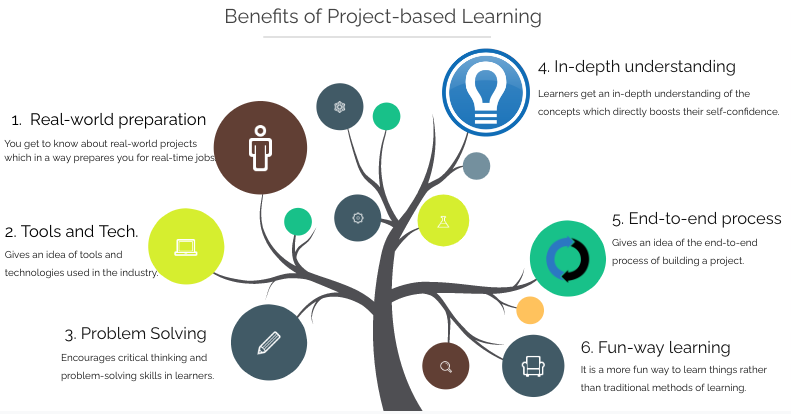
Benefits of Project-Based Learning
- You get to know about real-world projects which in a way prepares you for real-time jobs.
- Encourages critical thinking and problem-solving skills in learners.
- Gives an idea of the end-to-end process of building a project.
- Gives an idea of tools and technologies used in the industry.
- Learners get an in-depth understanding of the concepts which directly boosts their self-confidence.
- It is a more fun way to learn things rather than traditional methods of learning.
What is an End-to-End project?
End-to-end refers to a full process from start to finish. In an ML end-to-end project, you have to perform every task from first to last by yourself. That includes getting the data, processing it, preparing data for the model, building the model, and at last finalizing it.
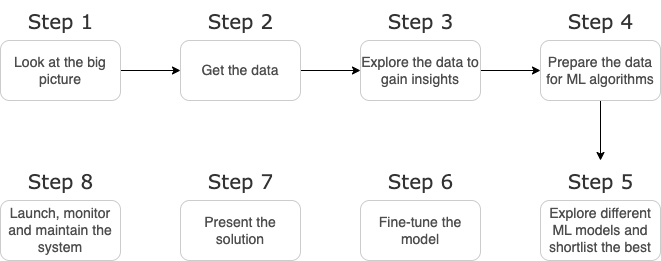
Ideology to start with End to End project
It is much more beneficial to start learning Machine Learning with an end-to-end project rather than diving down deep into the vast ocean of Machine Learning concepts. But, what will be the benefit of practicing concepts without even understanding them properly? How to implement concepts when we don’t understand them properly?
There are not one but several benefits of starting your ML journey with a project. Some of them are:
Continue reading “Starting Machine Learning with an End-to-End Project”How to Crack Machine Learning Interviews with Top Interview Questions(2024)
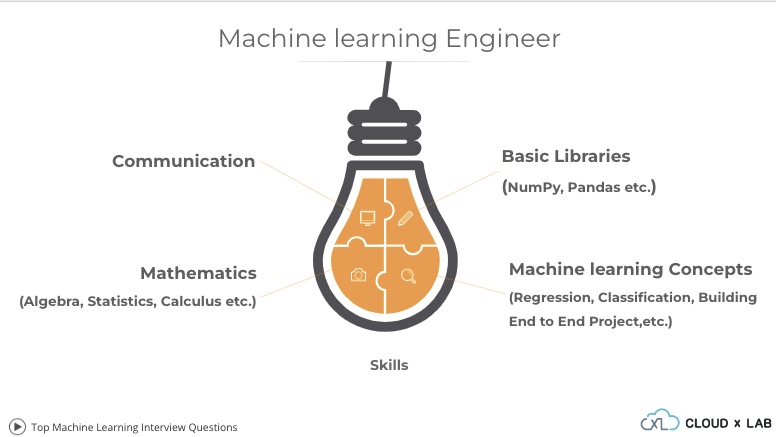
Machine Learning is the most rapidly growing domain in the software industry. More and more sectors are using concepts of Machine Learning to enhance their businesses. It is now not an add-on but has become a necessity for businesses to use ML algorithms for optimizing their businesses and to offer a personalised user experience.
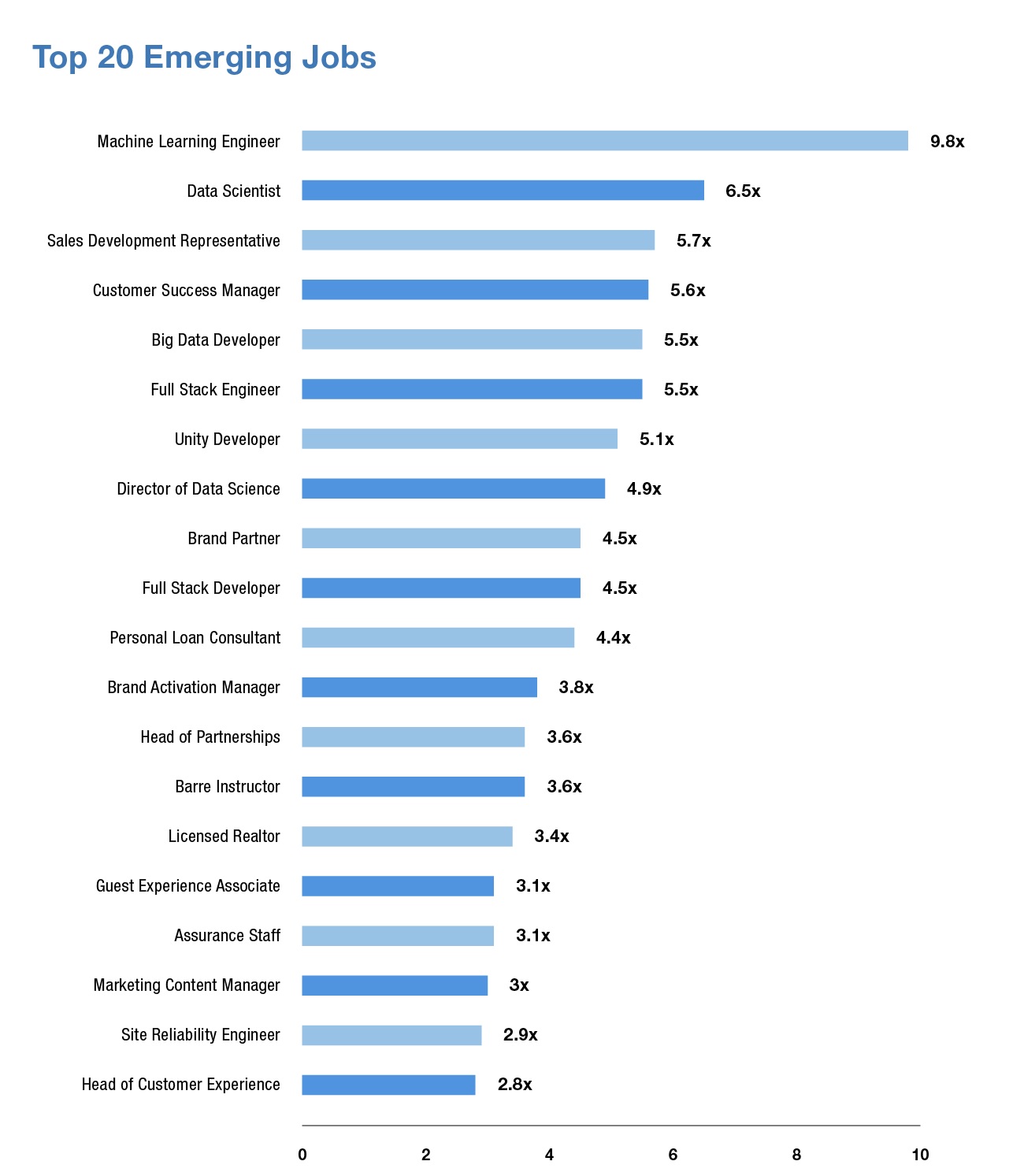
This demand for Machine Learning in the industry has directly increased the demand for Machine Learning Engineers, the ones who unload this magic in reality. According to a survey conducted by LinkedIn, Machine Learning Engineer is the most emerging job role in the current industry with nearly 10 times growth.
But, even this high demand doesn’t make getting a job in ML any easier. ML interviews are tough regardless of your seniority level. But as said, with the right knowledge and preparation, interviews become a lot easier to crack.
In this blog, I will walk you through the interview process for an ML job role and will pass on some tips and tactics on how to crack one. We will also discuss the skills required in accordance with each round of the process.
Continue reading “How to Crack Machine Learning Interviews with Top Interview Questions(2024)”Offline vs Online DevOps Training
Before we understand the different ways in which offline and online training can be beneficial for learners with different needs, let us understand what is DevOps.
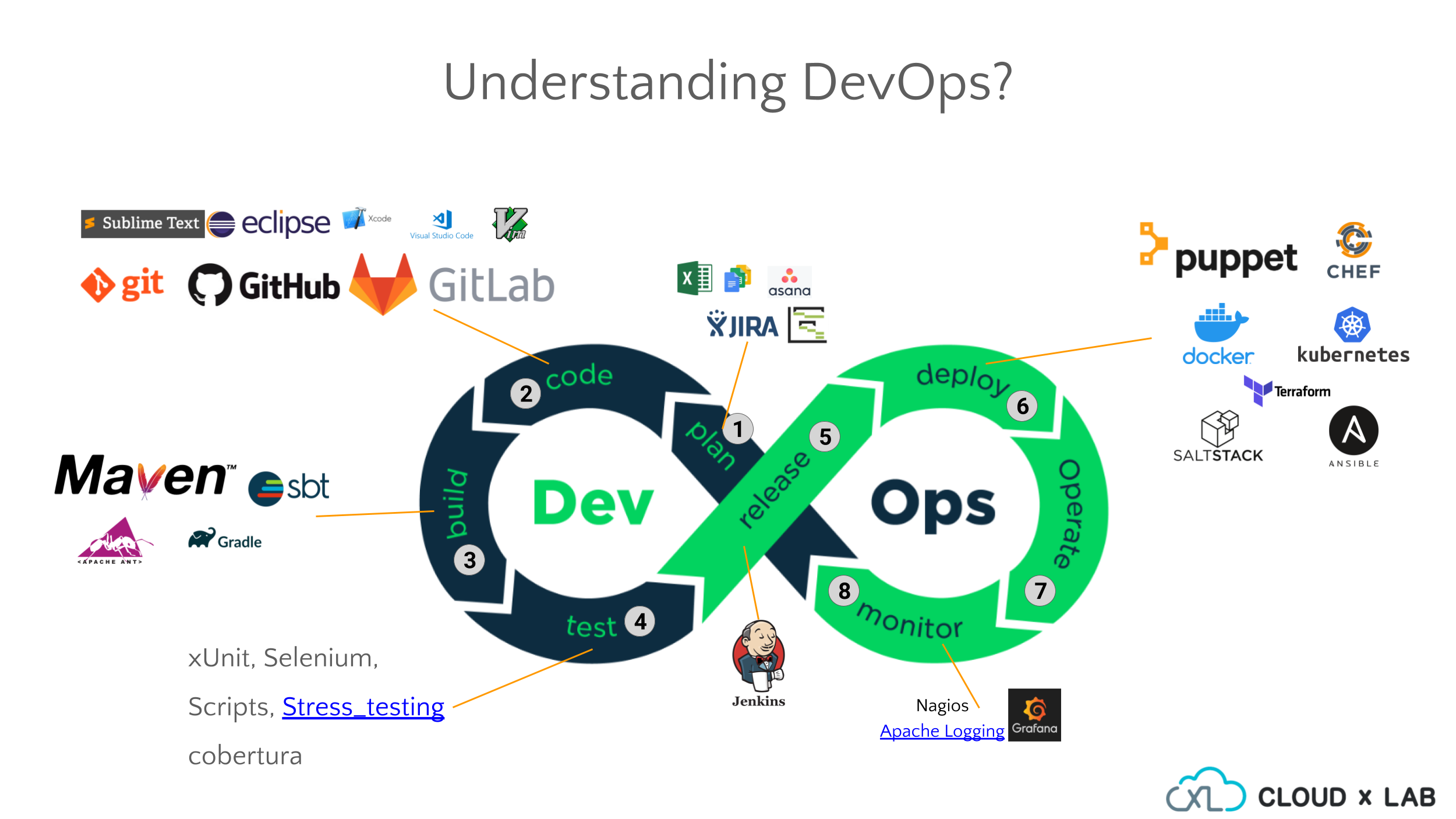
DevOps: An Introduction
What is DevOps?
DevOps is the amalgamation of cultural philosophies, practices, and tools that increases an organization’s ability to deliver applications and services at high velocity, understanding DevOps will help you evolve and improve products at a faster pace than organizations using traditional software development and infrastructure management processes. This speed enables organizations to serve their customers better and compete more effectively in the market.
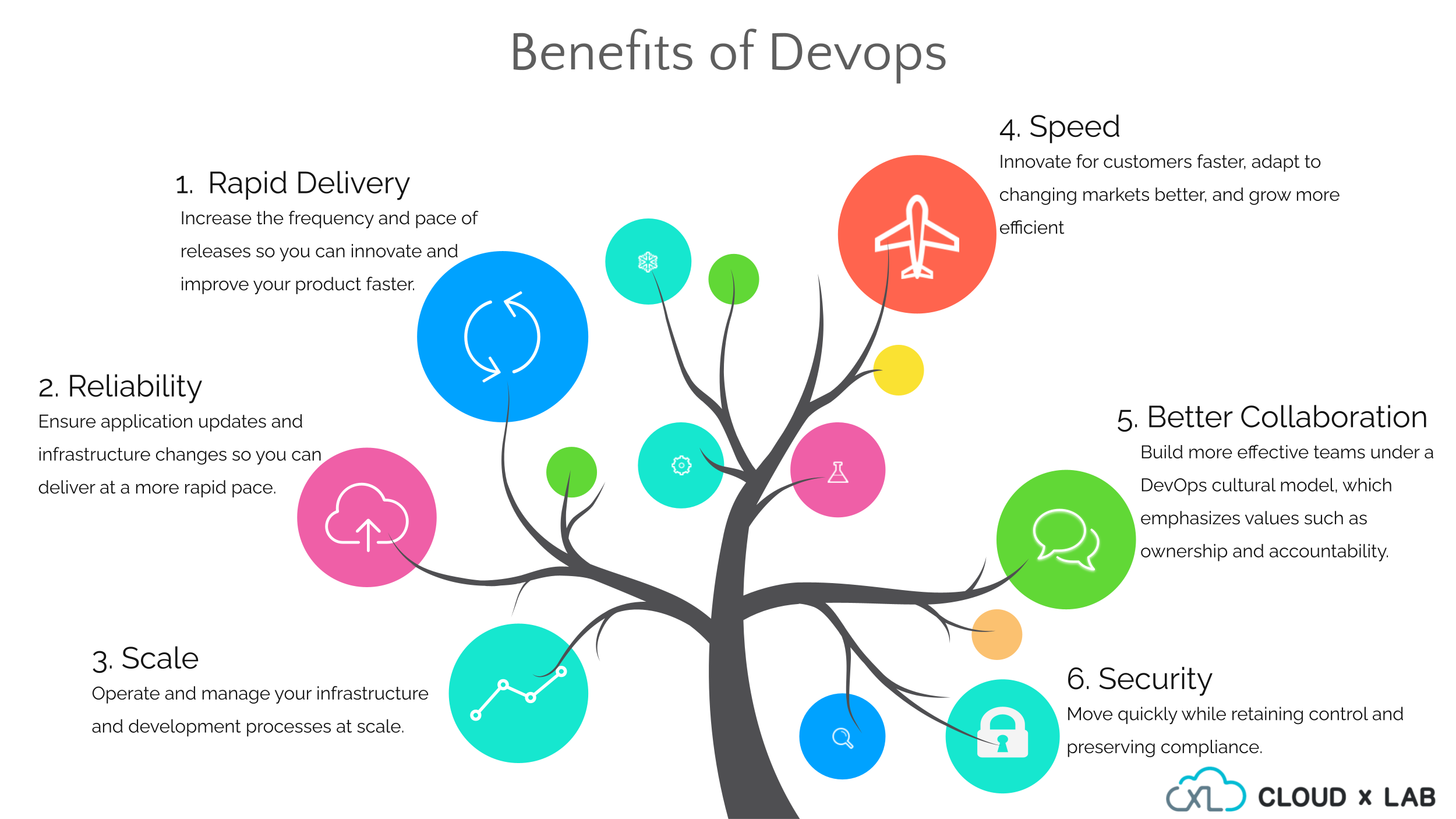
Check out the DevOps Introduction By Abhinav Singh for an in-depth understanding of DevOps tools and practices.
Continue reading “Offline vs Online DevOps Training”How to Interact with Apache Zookeeper using Python?
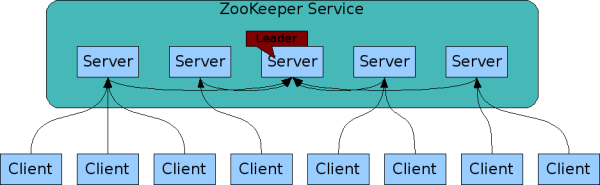
In the Hadoop ecosystem, Apache Zookeeper plays an important role in coordination amongst distributed resources. Apart from being an important component of Hadoop, it is also a very good concept to learn for a system design interview.
What is Apache Zookeeper?
Apache ZooKeeper is a coordination tool to let people build distributed systems easier. In very simple words, it is a central data store of key-value pairs, using which distributed systems can coordinate. Since it needs to be able to handle the load, Zookeeper itself runs on many machines.
Zookeeper provides a simple set of primitives and it is very easy to program.
It is used for:
- synchronization
- locking
- maintaining configuration
- failover management.
It does not suffer from Race Conditions and Dead Locks.
Continue reading “How to Interact with Apache Zookeeper using Python?”Bucketing- CLUSTERED BY and CLUSTER BY
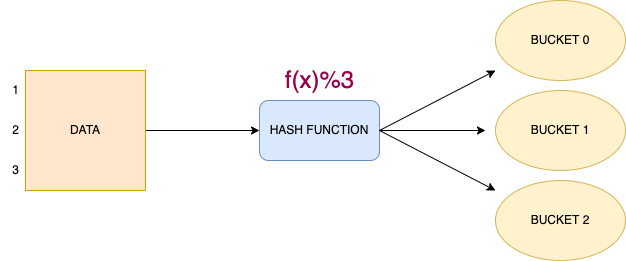
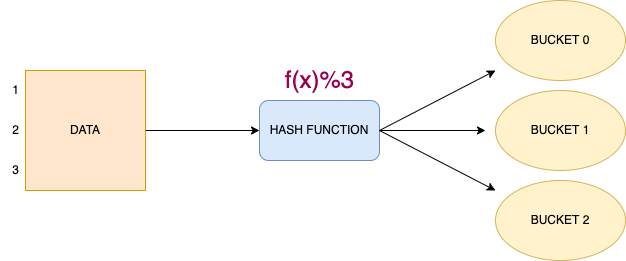
The bucketing in Hive is a data-organising technique. It is used to decompose data into more manageable parts, known as buckets, which in result, improves the performance of the queries. It is similar to partitioning, but with an added functionality of hashing technique.
Introduction
Bucketing, a.k.a clustering is a technique to decompose data into buckets. In bucketing, Hive splits the data into a fixed number of buckets, according to a hash function over some set of columns. Hive ensures that all rows that have the same hash will be stored in the same bucket. However, a single bucket may contain multiple such groups.
For example, bucketing the data in 3 buckets will look like-
The Era of Software Engineering and how to become one
Today’s world is also known as the world of software with its builders known as Software Engineers. It’s on them that today we are interacting with each other because the webpage on which you are reading this blog, the web browser displaying this webpage, and the operating system to run the web browser are all made by a software engineer.
In today’s blog, we will start by introducing software engineering and will discuss its history, scope, and types. Then we will compare different types of software engineers on the basis of their demand in the industry. After that, we will discuss on full-stack developer job role and responsibilities and will also discuss key skills and the hiring process for a full-stack developer in detail.
Continue reading “The Era of Software Engineering and how to become one”Summer Sale 2022

The Summer Sale is here!
The world in the future is complex, every aspect of services that we use will be AI based (most of them already are). The world of Data and AI. This thought often appears scary to our primitive brains and more so to people who see programming as Egyptian hieroglyphs but may I suggest an alternate approach to this view, instead of looking at how the technologies in the future are going to take away our job, we should learn to harness the power of AI and BIG DATA to be better equipped for the future.
At CloudxLab, We believe in providing Quality over Quantity and hence each one of our courses is highly rated by our learners, the love shown by our community has been tremendous and makes us strive for improvement, we strive to ensure that education does not feel like a luxury but a basic need that everybody is entitled to. Keeping this in mind, we bring forth the “#NoPayApril” where you can access some of the most sought after and industry-relevant courses completely free of cost. During #NoPayApril anybody who is signing up at CloudxLab will be able to access the contents of all the self-paced courses. This offer will be running from April 3 till April 30, 2022.
CloudxLab provides an online learning platform where you can learn and practice Data Science, Deep Learning, Machine Learning, Big Data, Python, etc.
When the highly competitive and commercialized education providers have cluttered the online learning platform, CloudxLab tries to break through with a disruptive change by making upskilling affordable and accessible and thus, achievable.
Happy Learning!